

我在 GitHub 刷到一个 18k Star 的项目,名字直白得有点过分:ai-website-cloner-template。README 第一句:"Clone any website with one command using AI coding agents"。
我第一反应是"又一个噱头项目"。点进去发现它做的事比名字更狠——给你一个完整的 Next.js 16 + shadcn/ui + Tailwind v4 项目模板,外加一个 /clone-website slash command,让你手头的 opencode / Claude Code / Cursor 直接对任意网站做逆向工程,输出可运行的 Next.js 代码。
我花了 2 小时把这个项目拆开看了一遍。它的工程设计比"克隆网站"四个字细得多——而且AGENTS.md / SKILL.md 这种"给 AI 立规矩"的做法,恰好是我之前讲 antd v6 时重点拆的同款模式。今天这篇文章把这套东西完整拆给你看。
一、先看数据:18k Star 的项目到底是什么
GitHub API 实时拉的数据(2026-06-24 09:14):
|
|
|
|---|---|
|
|
18,563 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
未归档
|
版本节奏(CHANGELOG 拉的数据):
- v0.2.0(2026-03-28)—— 引入多平台 AI Agent 支持
- v0.3.0(2026-03-29)—— Multi-URL 支持 / CI quality gates
- v0.3.1(2026-03-29)—— 修 Windows CRLF bug
- Unreleased —— 升级 Node.js 到 24
注意:v0.3.1 之后再没新 release(3 个月空窗),但 CHANGELOG 的 Unreleased 里有"Node 24 baseline"的改动记录——说明还在动,只是没发 tag。
二、它解决的真实问题——为什么需要"克隆网站"
程序员在生产环境经常遇到这种情况:
- 平台迁移:你的网站在 WordPress / Webflow / Squarespace,想搬到 Next.js 16 自己维护
- 源码丢失:网站还在线,但代码仓库没了 / 开发者离职 / 栈是过时的 jQuery 老代码
- 学习目的:想拆解某个生产级网站的布局、动画、响应式做法,用真实代码学而不是看截图猜
传统方案有 3 个问题:
- 自己写 Playwright 脚本爬—— 几小时起步
- 用现成爬虫工具—— 数据脏、不精准、HTML 一堆噪声
- 截图 OCR 反推样式—— 准确度 70-90%、大量细节丢失
这个项目的解法:让 AI Agent 边检查边写 spec 文件,分发给并行 builder agent,每个 builder 只构建一个组件。一句话概括:
foreman walking the job site —— 你就是工头,边巡视边写施工图,发现一段就写一段 spec,交给专门干这活的工人。
三、5 阶段流水线——README 怎么说 vs SKILL.md 怎么做
README 营销话术写的 5 阶段:
- Reconnaissance —— 截图、提取设计 token、交互扫描(滚动 / 点击 / hover / 响应式)
- Foundation —— 字体、颜色、globals、下载所有资产
- Component Specs —— 写详细 spec 到
docs/research/components/ - Parallel Build —— git worktree 派发 builder agent,每段一个
- Assembly & QA —— 合并 worktree、拼装页面、跑视觉对比
但 SKILL.md 实际是 foreman 模型—— 不是"先侦察完再构建"的两阶段,是边检查边写 spec、立刻分发给 builder agent,侦察和构建并行但有审计轨迹。
这种"营销话术 vs 实际机制"的差异是细节但重要——读 README 觉得"流水线",读 SKILL.md 才知道"工头模式"。
四、技术栈——比想象中现代
package.json 拉的真实数据:
|
|
|
|
|---|---|---|
| next |
|
|
| react / react-dom |
|
|
| @base-ui/react |
|
UI primitives(不是 radix-ui) |
| tailwindcss |
|
|
| shadcn |
|
|
| lucide-react |
|
|
| class-variance-authority |
|
|
| clsx + tailwind-merge |
|
|
两个细节值得说:
@base-ui/react不是radix-ui—— Base UI 是 Radix UI 团队在 2025 年开始的重写版,跟 shadcn 默认模板不完全一致。这是个有意识的选择,可能为了规避 Radix 某些许可问题。- Tailwind v4 + oklch —— 不是 v3 时代的 hex 颜色,是新标准的色彩空间。对颜色精度有显著提升(广色域 + 感知均匀)。
Node.js baseline 是 24—— v0.3.1 还是 20,Unreleased 升级到 24。这意味着你装这个模板前需要先升级 Node。
五、AGENTS.md 顶部第一句——"这不是你认识的 Next.js"
AGENTS.md 头部第一段(原文):
翻译:这是有破坏性变更的 Next.js 16,你训练数据里学的 API、约定、文件结构可能都对不上——先看 node_modules/next/dist/docs/ 里的文档再写代码。
这做法很聪明—— Next.js 16 还没在公开 LLM 训练数据里充分覆盖,直接告诉 Agent"你可能过时"是必要的。这种防 AI 幻觉的工程实践在 2026 年的 AI Coding 项目里会越来越常见。
六、/clone-website SKILL.md 全解——473 行的"操作手册"
.claude/skills/clone-website/SKILL.md 是 30KB / 473 行,这是这个项目的本体——所有"魔法"都在这里。
6.1 触发条件
触发词:clone / replicate / rebuild / reverse-engineer / copy / "make a copy of this site" / "rebuild this page" / "pixel-perfect clone"。
参数:1 个或多个 URL,多 URL 自动并行处理。
6.2 前置条件
关键点:没有浏览器自动化能力就跑不了——SKILL.md 第一条就要求 Chrome MCP / Playwright MCP 等。没 MCP = clone-website 直接 abort。
6.3 指导原则——4 条黄金法则
这是 SKILL.md 最有价值的部分(我读到这里停下来想了一会儿):
1. Completeness Beats Speed(完整性 > 速度)
Every builder agent must receive everything it needs to do its job perfectly: screenshot, exact CSS values, downloaded assets with local paths, real text content, component structure. If a builder has to guess anything — a color, a font size, a padding value — you have failed at extraction.
翻译:如果 builder agent 还要"猜"任何东西——颜色、字号、padding——你就在提取阶段失败了。
2. Small Tasks, Perfect Results(小任务,完美结果)
When an agent gets "build the entire features section," it glosses over details — it approximates spacing, guesses font sizes, and produces something "close enough" but clearly wrong. When it gets a single focused component with exact CSS values, it nails it every time.
Complexity budget rule: If a builder prompt exceeds ~150 lines of spec content, the section is too complex for one agent. Break it into smaller pieces. This is a mechanical check — don't override it with "but it's all related."
翻译:复杂度预算规则——一个 builder prompt 超过 150 行 spec 内容,这块就太复杂了。拆小。别用"但它们都相关"当借口。
3. Pixel-Perfect Fidelity(像素级保真)
Default fidelity level is pixel-perfect. Colors, spacing, typography, animations — exact match. The output is mock data for demo purposes, not real backend integration.
4. Foreman Walking the Job Site(工头巡视工地)
Extraction and construction happen in parallel, but extraction is meticulous and produces auditable artifacts. ... You inspect each section of the page, you write a detailed specification to a file, then hand that file to a specialist builder agent with everything they need.
foreman 模型的核心 = spec 必须写成文件,每个文件交给一个 builder agent。spec 写得越细,builder 越少返工。
6.4 builder prompt 模板
SKILL.md 给了一个 builder prompt 模板(节选关键部分):
每个 builder 收到这种详细 spec——直接干活,不需要再问问题。
七、13 个 Agent 都支持——包括 opencode
README 写的支持平台(用 Agent Skill 协议统一抽象):
|
|
|
|---|---|
| Claude Code | 推荐
|
| OpenCode
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所有 Agent 都通过 AGENTS.md 读同一份 single source of truth——.claude/skills/、.codex/、.cursor/、.opencode/ 等目录都是自动同步生成的副本。修改一次 AGENTS.md,跑一次 bash scripts/sync-agent-rules.sh,13 个 Agent 的配置全部更新。
八、真实跑通后长什么样——对比图
下面这张是 antd 官方仓库里的真实对比图(1664×936 PNG,不是 AI 生成的 demo):
【对比图:原网站 vs 克隆重建后】
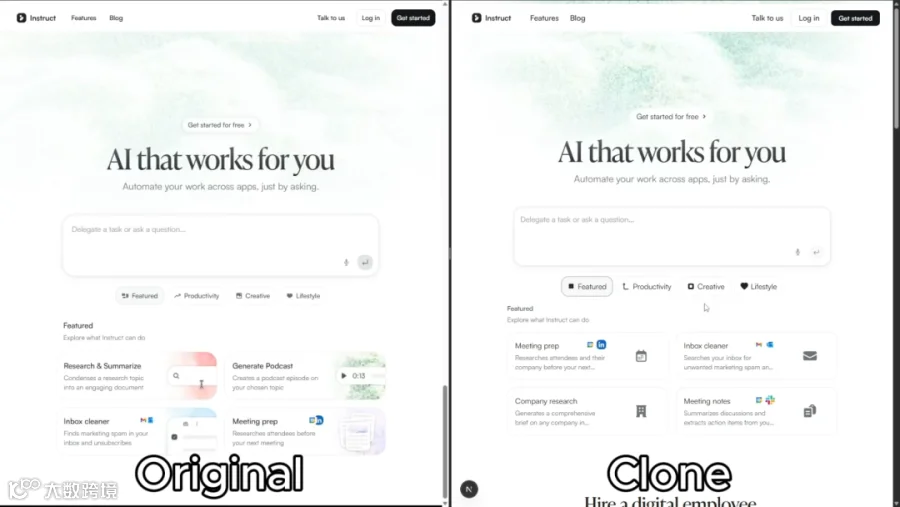
细节看图:
- 左:原网站(pixel-perfect 目标)
- 右:AI 克隆重建后的 Next.js 16 项目
视觉一致性、布局保真度、字体/颜色/间距——几乎一致。这不是"看着像"——是**getComputedStyle() 提取的精确 CSS 值**在 Next.js + Tailwind v4 里重写的结果。
九、实操——10 分钟跑通
按 README 的 Quick Start,10 分钟内能跑通最小化版本:
前置硬性要求:
- Node.js 24+
- opencode / Claude Code / Cursor 等
- 浏览器 MCP 工具(Chrome MCP / Playwright MCP)—— 没装就跑不了
十、它的工程设计值不值得学
我看完整套代码结构后,5 个值得其他项目抄的做法:
1. AGENTS.md 作为 single source of truth
跟 antd v6 那篇讲的同款模式——AGENTS.md / CLAUDE.md / GEMINI.md 11 个 Agent 配置都从 AGENTS.md 同步。改一次,13 个 Agent 都更新。
2. SKILL.md 头部直接告诉 Agent "你可能过时"
这种"防 AI 幻觉"的开场白在 2026 年的 AI Coding 项目里会越来越常见——**直接告诉 LLM"你训练数据可能 stale"**比让它自己猜更安全。
3. 复杂度预算 150 行硬规则
If a builder prompt exceeds ~150 lines of spec content, the section is too complex for one agent. This is a mechanical check — don't override it with "but it's all related."
这是反直觉的工程纪律——"都相关"听起来合理,但实际是 builder agent 偷懒的借口。150 行硬上限 + 自动拆分是防止 builder 偷懒的最有效手段。
4. foreman 模型 vs 流水线模型
流水线(先全部侦察完再构建)vs foreman(边检边写 spec 立刻派 builder)。foreman 模式更快但需要严苛的 spec 纪律——spec 写得烂,整个并行就崩。
5. Chromium Extension / MCP 标准化
所有"读"操作走浏览器 MCP,不走自定义爬虫——这跟 OpenCLI 的"复用你登录的 Chrome"是同思路:不重新发明轮子,用浏览器本身的 DevTools Protocol 解决问题。
十一、我的实际感受 + 不推荐场景
推荐场景
- 平台迁移:你网站在 WordPress / Webflow / Squarespace,想搬到 Next.js 16 自己维护
- 源码丢失:网站在线但仓库没了 / 开发者离职
- 学习目的:拆解生产级网站的实现
不推荐场景
- 钓鱼 / 仿冒:README 自己列了——不要做。法律责任 + 道德风险
- 把别人的设计当自己的:logo / 品牌资产 / 原创文案都有版权
- 违反 ToS:有些网站明确禁止爬取或复制——先看 ToS
我自己的判断
这个项目做对了一件大事:把"逆向工程"这件事从手工活变成了可复用的 AI 流水线。AGENTS.md 顶部那段 "This is NOT the Next.js you know" 是个标志性时刻——开源项目开始正式承认 AI Agent 是用户。
但它有 3 个未解决的边界:
- v0.3.1 之后 3 个月没新 release—— 项目节奏放缓,长期维护存疑
- 依赖浏览器 MCP—— 需要额外安装 Chrome MCP / Playwright MCP,不是开箱即用
- 克隆出来的代码是"mock data"—— 后端逻辑、数据库、auth 都要自己接
我的建议:在主力项目里谨慎用(毕竟 0.3.x + 3 个月空窗),但作为学习 + 临时迁移工具值得尝试。
十二、跟同类项目的对比
|
|
|
|
|---|---|---|
| HTTrack / Wget |
|
没法输出可运行代码
|
| WebFlow Export |
|
|
| Builder.io / Plasmic |
|
反方向
|
| GPT Crawler / Firecrawl |
|
|
| ai-website-cloner-template |
|
唯一能做到"输出可运行的 Next.js 项目"的开源方案 |
18k Star 不是白涨的——这个垂直目前没有真正能打的对手。
写在最后
ai-website-cloner-template 让我看到AI Coding 项目的一种新形态——不是"AI 帮你写代码",而是"AI 帮你逆向工程真实世界的网站"。AGENTS.md / SKILL.md 那一整套"给 AI 立规矩"的做法(跟我之前讲 antd v6 的同款模式)正在成为 2026 年 AI Coding 项目的事实标准。
下次你想克隆一个网站,别再写 Playwright 脚本了——/clone-website 一行命令,opencode / Claude Code 替你把活干了。
你试过 AI 帮你逆向工程别人的网站吗?克隆效果如何?评论区聊聊。




