

一直以来,“成本更低”都是开源AI模型吸引企业的重要理由。但一项新研究却揭示了一个反常识的真相:在执行相同任务时,开源AI模型消耗的计算资源远高于闭源模型,其“低价优势”可能只是假象。
一、核心发现:开源模型的“token黑洞”
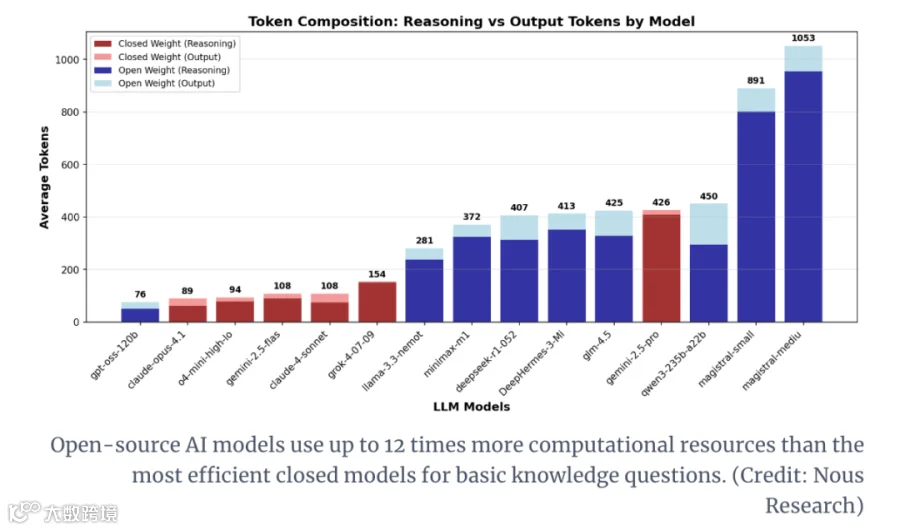
AI计算的核心单位是“token”(可理解为AI处理信息的“最小颗粒”),token消耗量直接决定计算成本。AI公司Nous Research对19个AI模型(覆盖基础知识问答、数学问题、逻辑谜题三大任务)的研究显示:
普遍差距:开源模型的token消耗量是OpenAI、Anthropic等闭源模型的1.5-4倍;
极端情况:面对“澳大利亚首都是哪里”这类简单知识题,部分开源模型的token用量甚至是闭源模型的10-12倍——明明一句话能答完,却要消耗数百个token“反复思考”;
成本反转:尽管开源模型单token价格更低,但“多耗token”的特性会直接抵消这一优势,最终导致单条查询成本更高。
二、关键原因:“推理效率”的巨大鸿沟
研究首次聚焦“token效率”(模型解决问题时,token消耗量与任务复杂度的匹配度),发现开源模型的低效主要源于两点:
推理过程冗余:尤其是“大型推理模型(LRMs)”,为了实现“逐步思考”,会用“思维链(Chain of Thought)”处理问题。但这种设计在简单任务上会过度消耗资源——比如回答基础常识题,也需要生成冗长的推理步骤;
优化方向差异:闭源模型厂商一直在迭代优化“减少token消耗”,以此降低用户的推理成本;而开源模型的新版本反而在增加token用量,优先追求“推理性能提升”,却忽视了成本控制。
三、谁才是“性价比之王”?模型实测排名
研究对不同厂商的模型效率做了横向对比,结果清晰:
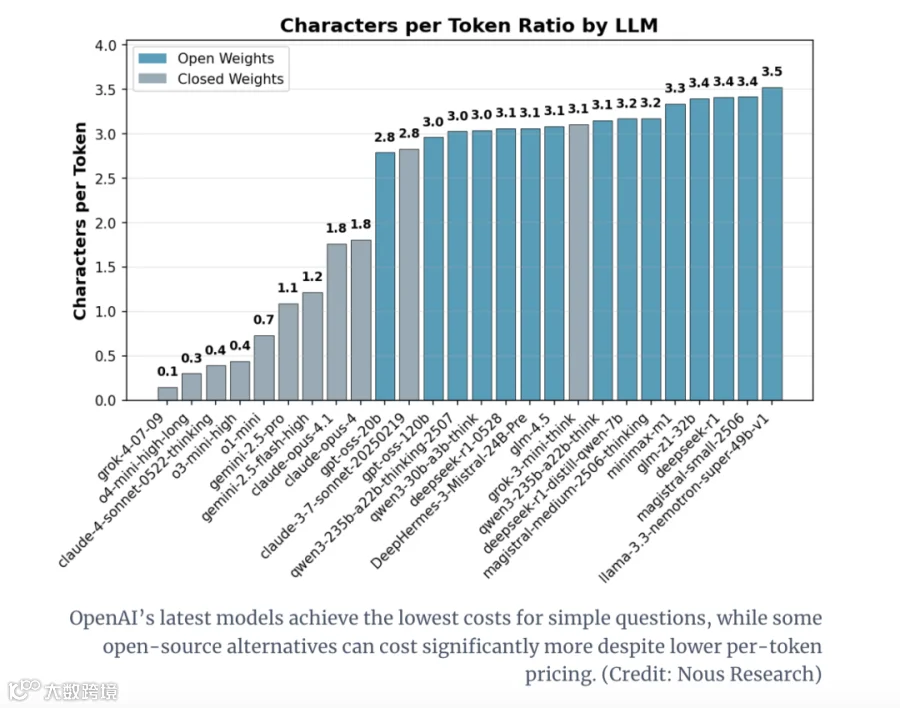
闭源模型:OpenAI表现突出
数学任务最优:OpenAI的o4-mini和新推出的开源版gpt-oss系列,token效率远超同行,用量比其他商业模型少3倍;
简单任务最省:处理基础知识题时,OpenAI最新模型的成本最低,token消耗控制能力最强。
开源模型:英伟达成唯一亮点
最佳开源选择:英伟达的llama-3.3-nemotron-super-49b-v1是“全任务场景下token效率最高的开源模型”;
反面案例:Magistral等公司的新开源模型属于“极端 outliers”,token消耗量异常高,成本优势完全消失。
四、对企业的3个重要启示
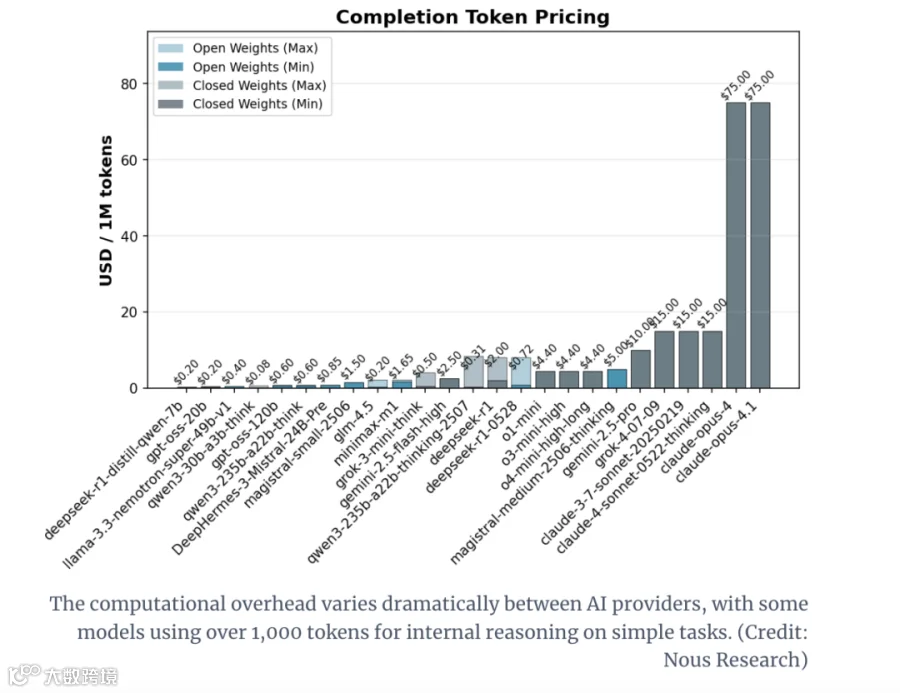
别只看“单token价格”:评估AI模型时,不能只关注单token成本,必须计算“完成任务的总token消耗量”,否则可能陷入“低价陷阱”;
闭源模型的“隐性优势”:闭源模型虽然单token定价更高,但凭借高token效率,最终的推理成本反而可能更低;
任务类型影响选型:数学、逻辑题场景下,开源与闭源模型的token差距约2倍;但基础知识问答场景差距会骤增,此时优先选闭源模型更划算。
五、未来方向:AI竞争的核心将是“效率”
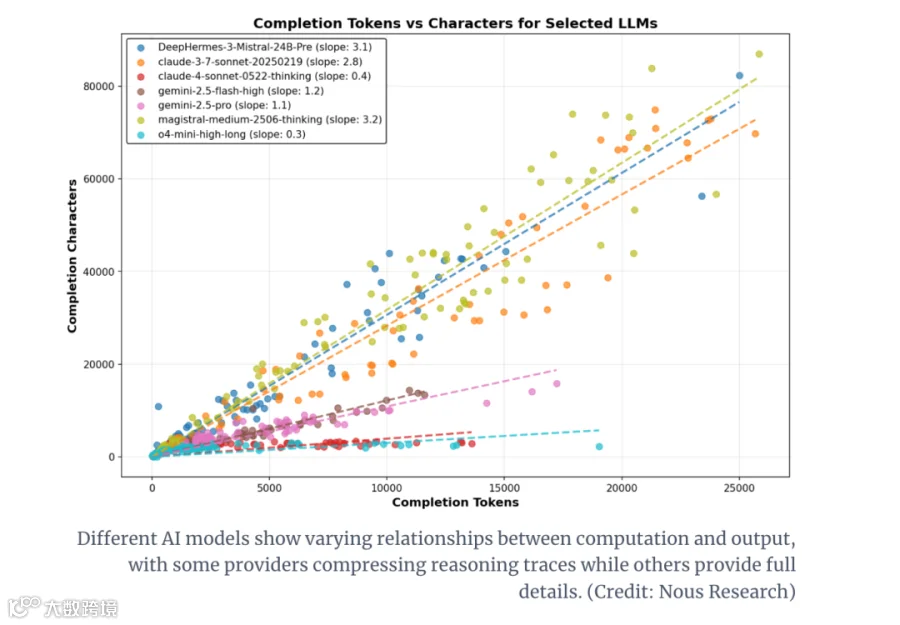
研究团队建议,未来AI模型开发需将“token效率”与“准确率”放在同等重要的位置——更精简的“思维链”不仅能降低成本,还能减少长文本推理时的“上下文退化”问题。
值得关注的是,OpenAI新推出的开源版gpt-oss模型,既保持了“思维链可查看”的开源特性,又实现了顶尖的token效率,或许能为开源模型的优化提供参考。
目前,该研究的完整数据集和评估代码已在GitHub开源,供行业验证和延伸研究。正如研究结论所言:未来AI的竞争,可能不再是“谁的模型更聪明”,而是“谁的模型更高效”——在token成本敏感的时代,浪费资源的模型终将被市场淘汰。