

在AI大模型竞速赛中,“跑分”似乎成了衡量实力的重要标准——但那些在孤立任务(比如数学推理、指令跟随)中表现亮眼的模型,到了企业真实场景里还能“打”吗?
近日,Salesforce AI Research发布了一款开源基准测试工具MCP-Universe,专门针对大模型与真实世界MCP(模型上下文协议)服务器的交互能力进行测试。结果却有些“扎心”:即便是OpenAI最新发布的GPT-5,在企业常见的MCP协同任务中,失败率也超过了50%;而包括Grok-4、Claude-4 Sonnet在内的主流大模型,同样面临“长上下文跟不上”“陌生工具不会用”的普遍难题。
本文章的主要内容来自: MCP-Universe: Benchmarking Large Language Models with MCP-Universe Real-World Model Context Protocol Servers
一、为什么要做MCP-Universe?现有基准的“短板”太明显
先搞懂一个关键背景:MCP(Model Context Protocol,模型上下文协议)是企业AI的“互操作核心”——它能让大模型/智能体突破“封闭生态”,与企业实际使用的工具(比如Google Maps、GitHub、Yahoo Finance)无缝对接。但过去的大模型基准测试,却普遍存在一个问题:
“现有基准大多只关注大模型的孤立性能,比如能不能算对数学题、能不能听懂指令,却没能力全面评估模型在真实MCP场景下的表现——毕竟企业需要的不是‘纸上谈兵’,而是能实实在在调用工具、处理复杂任务的AI。”
这正是MCP-Universe的核心价值:它不搞“模拟题”,而是直接对接11个真实MCP服务器,覆盖企业高频使用的六大领域,让大模型在“实战环境”中接受考验。同时,它还弥补了此前同类基准的不足——比如Salesforce7月发布的MCPEvals仅针对智能体,且用的是合成任务;而MCP-Universe则聚焦“真实任务+实时数据”,能更准确反映大模型的落地能力。
此外,MCP-Universe也并非“孤军奋战”——它与麻省大学阿默斯特分校、西安交通大学的MCP-Radar,北京邮电大学的MCPWorld等一起,构成了MCP生态下的基准体系,共同推动大模型在企业场景的标准化评估。
二、MCP-Universe怎么测?六大领域+执行式评估,拒绝“走过场”
要想测出大模型的“真本事”,测试场景和评估方法必须“接地气”。Salesforce在MCP-Universe的设计上,几乎完全复刻了企业的真实工作流:
1. 覆盖六大企业核心领域,231个任务全靠真实工具
MCP-Universe没有泛泛而谈,而是精准锁定企业常用的6类场景,每个场景都对接了对应的真实MCP服务器,共设计231个任务:
位置导航:调用Google Maps MCP,考验地理推理能力(比如从迪拜某酒店到餐厅的路线规划、最优停靠点选择);
仓库管理:对接GitHub MCP,测试代码库操作(如代码搜索、issue跟踪、版本控制);
财务分析:连接Yahoo Finance MCP,评估量化推理与市场决策(比如基于实时数据做财务分析);
3D设计:通过Blender MCP,看大模型能否使用CAD工具完成设计任务;
浏览器自动化:依托Playwright MCP,测试浏览器交互能力(如自动操作网页);
网页搜索:结合Google Search和Fetch MCP,考察“开放域信息获取”(更灵活的开放式任务)。
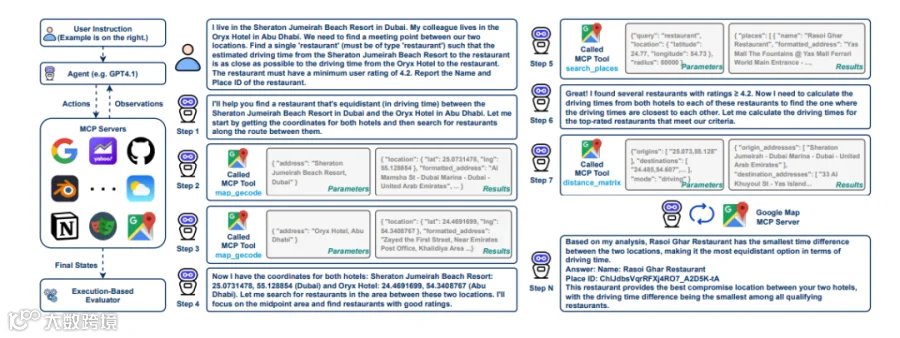
比如在位置导航任务中,模型需要先获取两个酒店的坐标,再搜索中途高评分餐厅,最后计算最优路线——整个流程和企业员工安排商务行程的逻辑完全一致。
2. 不用“LLM当裁判”,改用“执行式评估”更靠谱
过去很多基准会让一个大模型(比如GPT-4)当“裁判”,去评判另一个模型的输出是否正确。但MCP-Universe直接放弃了这种方式,原因很简单:
“部分任务需要实时数据(比如航班价格、GitHub最新issue),而‘LLM裁判’的知识是静态的,根本无法判断这些动态结果的正确性。”
取而代之的是执行式评估(execution-based evaluation),通过三类“ evaluator ”(评估器)层层把关:
格式评估器:检查模型调用工具时是否符合格式要求(比如参数是否正确);
静态评估器:评估长期稳定的正确性(比如代码编辑是否符合语法);
动态评估器:针对实时变化的数据(如股票价格、酒店availability),直接对接工具验证结果。
这种方式的好处是“结果说话”——模型做得对不对,不是靠“裁判”主观判断,而是看它实际调用工具后能不能完成任务。
三、测试结果扎心:GPT-5领跑但仍有短板,大模型遇两大“拦路虎”
Salesforce此次测试了15款主流大模型(均为120B参数以上,涵盖闭源和开源),包括GPT-5、Grok-4、Claude-4 Sonnet、Gemini 2.5 Pro、GLM-4.5等。整体来看,闭源模型表现优于开源,但即便是头部模型,也远未达到“企业可用”的完美状态。
1. 头部模型排名:GPT-5领跑,Claude格式满分,Grok浏览器最强
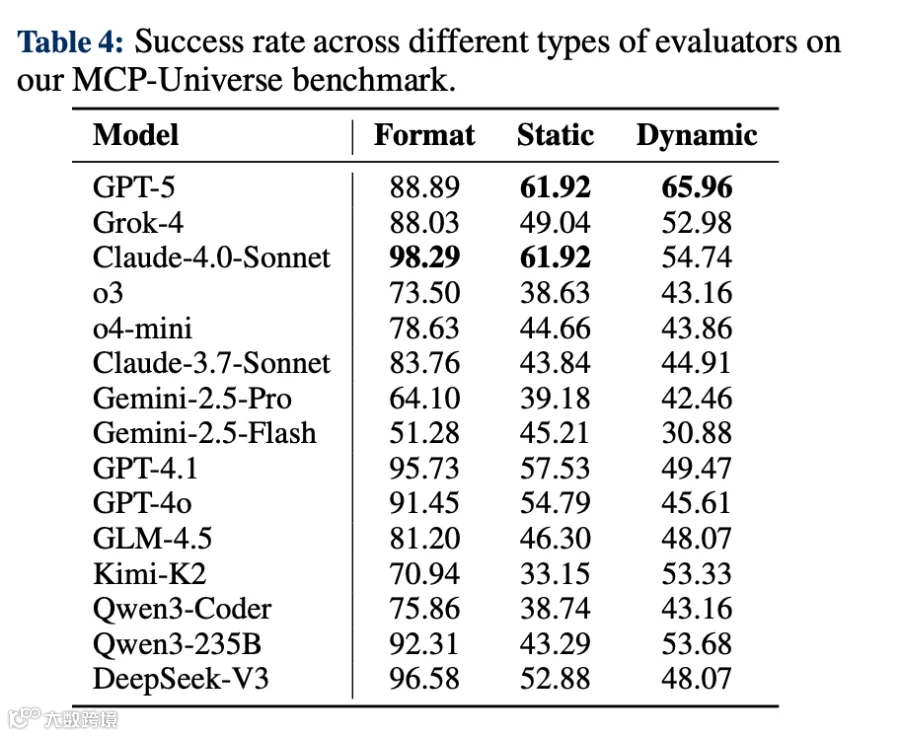
从“格式、静态、动态”三项核心指标的成功率(%)来看,头部模型的表现如下(重点模型数据整理):
可以看到:
GPT-5综合最强:尤其是在财务分析任务中表现突出,动态任务成功率(65.96%)是所有模型中最高的;
Claude-4.0 Sonnet格式满分:98.29%的格式合规率,说明它调用工具时的参数准确性极高,但静态/动态表现略逊于GPT-5;
Grok-4有独门优势:在浏览器自动化任务中击败了所有对手,是该领域的“单项冠军”;
开源模型中GLM-4.5最优:虽然整体不如闭源,但在开源阵营中表现最亮眼。
2. 所有模型的“通病”:长上下文扛不住,陌生工具不会用
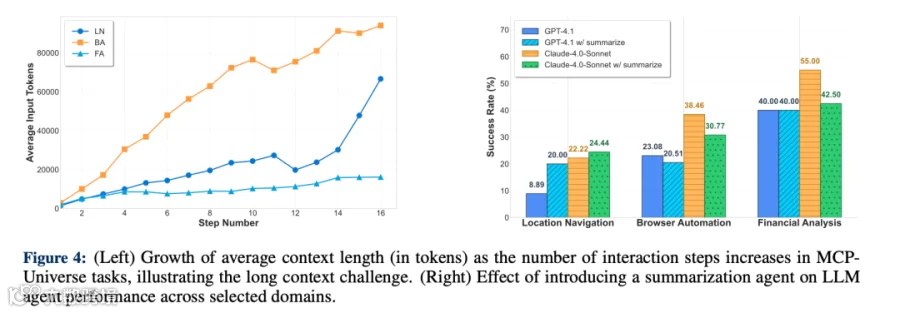
尽管头部模型各有优势,但MCP-Universe的测试暴露了一个共性问题:大模型在超过半数的企业级MCP任务中无法完成,核心卡在两个点上:
长上下文挑战:当任务步骤增多、输入变复杂(比如导航需要处理多个地点的坐标、餐厅评分、路线规则),模型很容易“记混信息”,推理一致性大幅下降。从测试数据看,位置导航、浏览器自动化、财务分析这三个领域受影响最严重,随着交互步骤增加,模型效率显著下跌;
未知工具挑战:人类遇到陌生工具能快速学习适配,但大模型不行——一旦遇到没训练过的MCP工具,性能会直接“跳水”,无法像人类一样“即学即用”。
Salesforce AI研究主任Junnan Li对此直言:“这就是为什么企业不能迷信‘单一模型’——靠一个模型单独驱动智能体是行不通的,必须依赖能整合‘数据上下文+增强推理+信任护栏’的平台,才能真正满足企业AI的需求。”
四、对企业的启示:MCP-Universe不是“成绩单”,而是“改进指南”
Salesforce开发MCP-Universe的目的,不是为了“贬低”大模型,而是给企业提供一个“照妖镜”——让企业清楚看到,自己依赖的大模型在哪些真实任务中会“掉链子”,从而有针对性地改进:
对技术团队:可以基于MCP-Universe的框架,测试自家智能体与MCP工具的适配性,优化长上下文处理、未知工具适配的算法;
对决策层:避免盲目追求“大模型参数规模”,而是更关注模型在具体业务场景(如财务分析、代码管理)中的实际表现,优先选择能与现有MCP生态兼容的解决方案。
正如Salesforce在论文中所说:“当前顶尖大模型在跨场景真实MCP任务中,仍无法可靠执行任务。MCP-Universe的价值,就是填补现有基准的空白,成为大模型企业化落地的‘必要试炼场’。”
五、总结
从GPT-5到Claude-4,大模型的“纸面实力”确实在不断突破,但MCP-Universe的测试结果提醒我们:AI的“落地能力”和“实验室能力”之间,还有一道不小的鸿沟。
对于企业来说,未来AI竞争的关键,可能不是“谁用了更牛的大模型”,而是“谁能把大模型、MCP工具、业务数据更好地整合起来”。毕竟,能解决真实问题的AI,才是有价值的AI。