
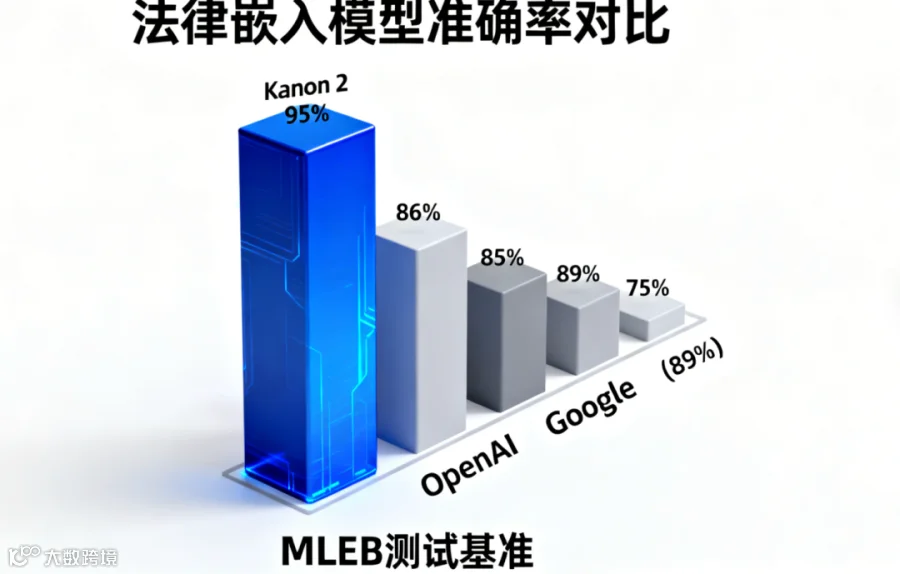
当AI在法律领域的应用越来越广泛,“检索准确性”成为决定法律RAG(检索增强生成)工具价值的关键。近日,澳大利亚初创公司Isaacus推出的法律专用嵌入模型Kanon 2 Embedder,在全新基准测试中一举超越OpenAI、谷歌等巨头模型,不仅刷新了法律信息检索的精度上限,还通过数据主权保护和开放基准,为行业发展提供了新方向。
一、核心突破:Kanon 2 Embedder凭什么赢?
在Isaacus自研的“海量法律嵌入基准(MLEB)”测试中,Kanon 2 Embedder展现出碾压性优势,核心成绩可总结为“两高两快”:
精度更高:准确率比OpenAI Text Embedding 3 Large高出9%,比谷歌Gemini Embedding高出6%,在20个参赛模型(含Qwen3、IBM Granite等)中排名第一。
速度更快:运行速度比上述两大巨头模型快30%以上,同时比排名第二的Voyage 3 Large快340%。
体量更小:模型规模仅为Voyage 3 Large的几分之一,更易部署且成本更低。
适配性更广:基于覆盖38个司法管辖区的数百万法律文件(案例、法规、合同等)训练,天然适配多地区法律场景。
二、关键配套:MLEB打造法律检索“黄金标准”
要衡量模型好坏,首先得有科学的基准。Isaacus推出的MLEB,填补了法律嵌入模型评估的空白,成为当前最全面的法律检索测试体系:
覆盖范围广:涵盖6个司法管辖区(美国、英国、欧盟、澳大利亚、新加坡、爱尔兰)和5大法律领域(案例、成文法、规章、合同、学术文献),避免单一场景的局限性。
数据质量硬:所有数据集均由法律领域专家筛选和审核,确保测试内容符合真实法律工作需求,杜绝“纸面数据”偏差。
结论有价值:测试明确证明“法律专用模型优于通用模型”——排名前三的Kanon 2 Embedder、Voyage 3 Large、Voyage 3.5均为法律优化模型,其中Voyage系列还得益于与法律科技公司Harvey的合作。
三、行业痛点解决:从检索质量到数据安全的双重保障
法律领域对“准确性”和“保密性”的要求远超其他行业,Kanon 2 Embedder和MLEB恰好针对性解决了两大核心痛点:
1. 终结“低质检索导致的AI幻觉”
在法律RAG应用中,嵌入模型的质量直接决定检索结果精度。低质量嵌入会导致AI给出错误法律依据,甚至出现“幻觉内容”,给律师工作带来风险。Kanon 2 Embedder通过提升检索准确性,从源头降低了法律AI的错误率,为Harvey、LexisNexis等主流法律科技工具提供更可靠的底层支持。
2. 严守法律数据主权,拒绝“默认用私域数据训练”
与Voyage、Cohere等公司不同,Isaacus默认不将企业用户的私有法律数据用于模型训练,避免敏感案件、内部合同等信息泄露。此外,针对高隐私需求客户,Isaacus还将推出“空气隔离部署容器”,可在AWS和微软云市场使用,进一步保障数据不被外部访问。
四、现在就能用:企业与开发者的上手指南
目前Kanon 2 Embedder已开放试用,不同需求的用户可通过以下方式接入:
普通开发者/小团队:直接查看Isaacus官方文档的“快速启动指南”,即可测试模型在自有法律场景中的检索效果。
大企业/高隐私需求客户:关注Isaacus的LinkedIn账号,未来几周将推送AWS和微软云市场的私有部署版本通知,支持本地化、安全化部署。
研究与测试人员:MLEB的全部数据和代码已在Hugging Face和GitHub开放,同时Isaacus官网还提供排行榜和测试方法论文档(后续将以论文形式发布),方便行业对比和优化模型。
五、法律AI进入“专用化竞争”时代
Kanon 2 Embedder的胜出,标志着法律AI从“通用模型适配”转向“专用模型深耕”的新阶段。对于法律从业者而言,更准确的检索工具能减少重复劳动;对于行业而言,MLEB的开放为技术迭代提供了统一标准;而数据主权保护的设计,也为全球法律科技公司树立了“安全标杆”。
后续随着私有部署版本的落地,这款澳产LLM或许会成为更多法律机构的首选底层工具,进一步推动法律行业的智能化升级。