

视觉语言模型(VLMs)越来越强,但“听懂”人类需求、输出符合预期的结果,始终是关键难题。近日,Hugging Face的TRL库迎来重大更新,新增了3种多模态对齐方法,能让VLMs从偏好数据中提取更多信息,性能再上一个台阶!
一、为什么VLMs需要“对齐”?
简单说,“对齐”就是让模型的输出更符合人类偏好。传统流程是:先用有监督微调Supervised Fine-Tuning (SFT) 让模型学会遵循指令,再用直接偏好优化Direct Preference Optimization (DPO)让模型区分“好回答”和“坏回答”(通过对比“选择的答案”和“拒绝的答案”)。
但DPO只能处理成对数据,信息利用率有限。而新方法能突破这一限制,甚至解决SFT和DPO的固有问题(比如SFT的分布偏移、DPO生成重复内容等)。
二、3种新方法:让VLMs更聪明的核心技术
1. 混合偏好优化(MPO):多损失协同发力
Mixed Preference Optimization (MPO) 是DPO的“升级版”,通过三种损失结合解决单一方法的缺陷:
偏好损失(来自DPO):区分好/坏回答;
质量损失(来自BCO):判断回答质量;
生成损失(来自SFT):保证生成内容连贯。
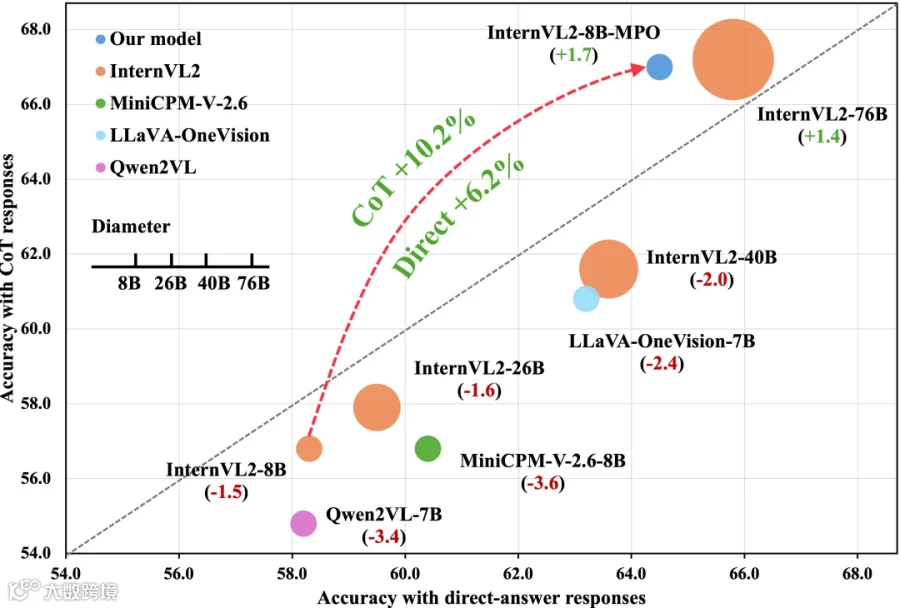
效果有多好?在MathVista数据集上,MPO直接带来了6.2分的性能提升!
如何使用?
只需在TRL的DPOTrainer中配置损失类型和权重:
mpo_config = DPOConfig(loss_type=["sigmoid", "bco_pair", "sft"], # 三种损失类型loss_weights=[0.8, 0.2, 1.0], # 对应权重# 其他参数(略))mpo_trainer = DPOTrainer(model=model_id, args=mpo_config, ...)mpo_trainer.train()
2. 组相对策略优化(GRPO):抗噪声能力更强
Group Relative Policy Optimization (GRPO) 源自DeepSeek团队的研究,基于PPO但更强大:它不再针对单个样本优化,而是对一整组对话轨迹(比如一个批次的对话数据)进行更新。
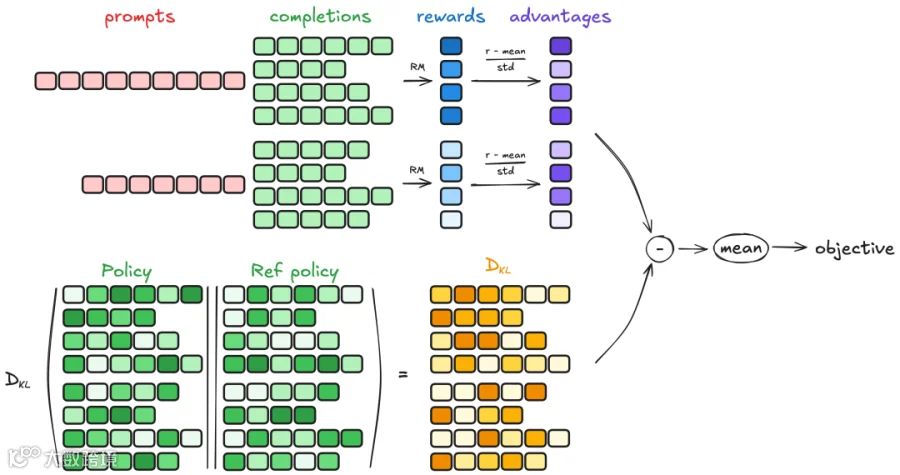
这样做的好处是:
奖励数据中的噪声会被“平均掉”,模型更稳健;
模型能学到“什么是整体好的回答”,而不是纠结于个别高奖励样本。
关键操作:定义奖励函数
GRPO需要自定义奖励函数(比如检查回答格式、验证答案正确性),再传入训练器:
# 示例:检查回答格式的奖励函数def format_reward(completions, **kwargs):pattern = r"^</think>.*?</think>s*</think>.*?</RichMediaReference>$" # 自定义格式return [1.0 if re.match(pattern, c) else 0.0 for c in completions]# 初始化训练器trainer = GRPOTrainer(model=model,reward_funcs=[format_reward, accuracy_reward], # 传入奖励函数args=training_args,...)
3. 组序列策略优化(GSPO):训练更稳定,适合大模型
Group Sequence Policy Optimization (GSPO) 是Qwen团队提出的GRPO改进版,核心差异是:在序列级别(而非逐token)计算重要性采样权重,让训练更稳定,尤其适合MoE(混合专家)架构的大模型。
使用技巧:
配置时只需在GRPO的参数基础上,增加序列级相关设置:
training_args = GRPOConfig(importance_sampling_level="sequence", # 序列级计算epsilon=3e-4, # 控制更新幅度# 其他参数(略))
三、效果对比:哪种方法更优?
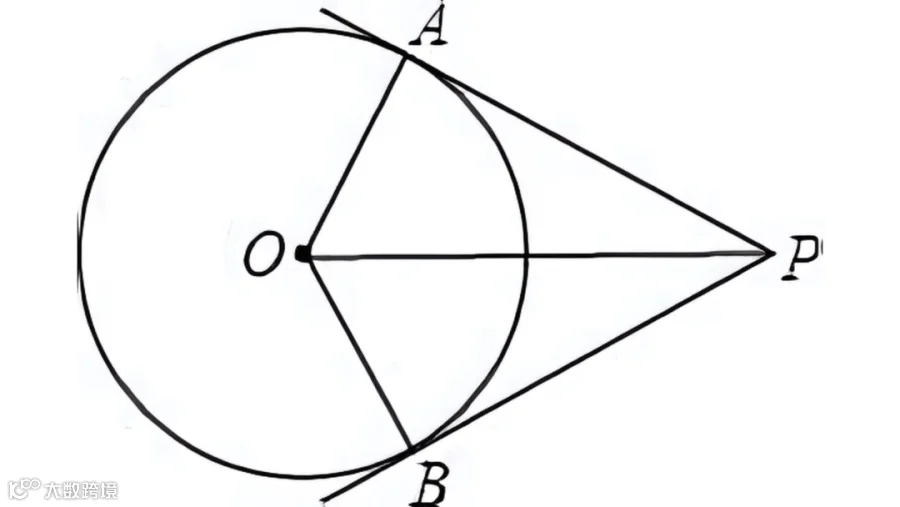
以Qwen2.5VL-3B模型解决几何问题(已知∠APO=25°,求∠AOB)为例,不同方法的输出差异明显:

可见,GRPO和GSPO在理解问题、应用知识、贴合人类需求上表现更优。
四、效率提升:vLLM集成加速训练
为了让大模型训练更高效,TRL还集成了vLLM(高性能推理库),支持在线生成样本时加速。使用时只需在脚本中添加--use_vllm,并选择两种模式:
colocate模式:vLLM与训练循环在同一进程,共享GPU,适合单机训练;
server模式:vLLM单独作为服务启动,适合多机分布式训练。
启动示例:
# colocate模式CUDA_VISIBLE_DEVICES=1,2 python grpo_vlm.py --model Qwen2.5-VL-3B --use_vllm --vlm_mode colocate# server模式(先启动服务)trl vllm-serve --model Qwen2.5-VL-3B --tensor-parallel-size 1# 再运行训练脚本CUDA_VISIBLE_DEVICES=1,2 python grpo_vlm.py --use_vllm --vlm_mode server
五、总结:快速上手资源
如果你想立即尝试这些新方法,可以参考TRL提供的:
完整训练脚本(examples/scripts/);
演示笔记本(含代码和可视化结果);
官方文档(详细参数说明)。
有了这些工具,让你的VLMs更懂人类,从此不再复杂!