

企业选大语言模型(LLM)时,“跑分”是重要参考,但传统基准测试常困在静态数据集和实验室环境里,和真实应用场景脱节。近日,VentureBeat报道了阿里蚂蚁集团关联机构Inclusion AI推出的Inclusion Arena——一个聚焦LLM真实生产环境表现的新基准平台,为企业选模型提供了更实用的参考。
一、为什么要“告别实验室基准”?传统测试的痛点很明显
目前主流的LLM基准测试(如MMLU、OpenLLM)存在关键局限:
数据/环境静态化:大多基于固定数据集和封闭测试场景,无法模拟用户真实使用时的动态需求(比如多轮对话、个性化交互);
忽略用户偏好:只考核模型的“知识储备”,不关注人类用户对回答的实际满意度——毕竟企业用LLM,最终要服务于人的需求。
Inclusion AI的研究者认为,LLM需要一个能衔接真实应用与模型能力的评估体系,这正是Inclusion Arena诞生的核心原因。
二、Inclusion Arena:在真实应用里“打榜”,靠用户偏好定排名
和传统基准平台不同,Inclusion Arena的核心逻辑是“让模型在实际使用中接受检验”,具体设计有三大亮点:
1. 独特的评估方式:嵌入真实APP,收集用户选择
平台会将基准测试框架直接集成到AI应用中,目前已接入两款应用:
角色聊天APP“Joyland”
教育沟通APP“T-Box”
当用户使用这些APP时,系统会在后台把用户的提问同步发给多个LLM,生成不同回答;用户无需知道哪个回答来自哪个模型,只需选择自己最满意的一个——这些“用户偏好选择”就是评估模型的核心数据。
2. 更稳定的排名算法:用Bradley-Terry替代部分Elo
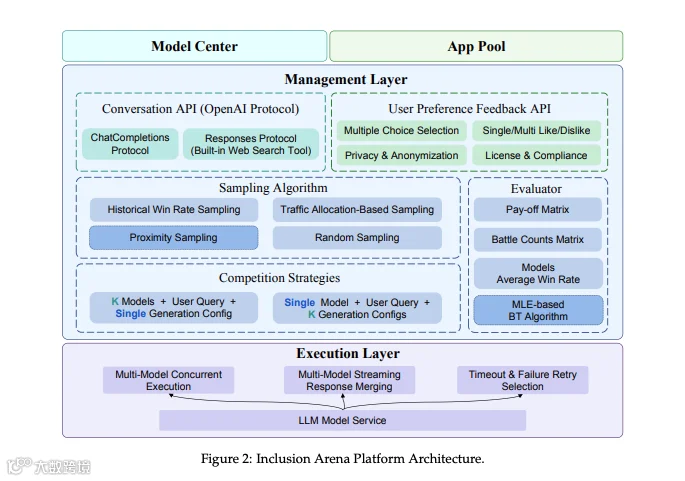
传统LLM排行榜常用“Elo评分法”(源自国际象棋,计算选手相对实力),而Inclusion Arena主要采用Bradley-Terry模型:
两者都是概率性排名框架,但研究者表示,Bradley-Terry能生成更稳定的模型评分,减少因单次测试波动导致的排名偏差;
为解决“模型太多、两两对比太耗资源”的问题,平台还加了两个辅助机制:
初始匹配机制:给新加入排行榜的模型快速估算初始排名,避免从零开始对比;
邻近采样:只让排名处于同一“信任区间”的模型互相比较,提升计算效率。
3. 初期数据:50万次对比,这几款模型表现突出
截至2025年7月,Inclusion Arena已收集到501,003次模型两两对比数据,覆盖46,611名活跃用户(来自上述两款APP)。
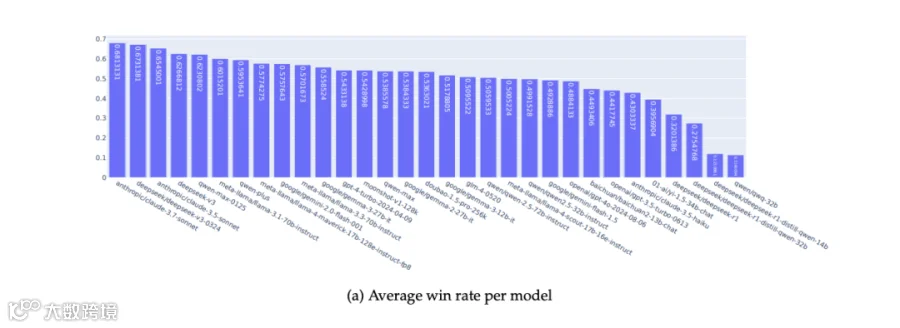
根据初期实验结果,表现最优的LLM依次为(按性能排序):
Anthropic Claude 3.7 Sonnet
DeepSeek v3-0324
Anthropic Claude 3.5 Sonnet
DeepSeek v3
Qwen Max-0125
研究者强调,随着接入的APP增多、用户数据积累,这份排行榜会更精准、更具参考性——目前平台正计划打造“开放联盟”,扩大应用生态。
三、对企业的启示:排行榜是参考,内部测试不能少
文章指出,随着LLM数量爆发,企业选择模型的难度越来越大,Inclusion Arena这类“贴近真实场景”的排行榜,能帮技术决策者快速锁定潜力模型。
但需注意:排行榜只是“初选工具”。企业最终仍需结合自身业务场景做内部评估——比如电商客服场景要测模型的“问题解决效率”,教育场景要测“知识准确性”,确保模型真的适配自己的需求。
此外,Inclusion Arena并非个例,近期AI领域已出现更多“落地导向”的基准测试(如艾伦人工智能研究所的RewardBench 2),它们共同推动LLM评估从“实验室跑分”走向“实际价值检验”。
如果想了解Inclusion Arena的详细技术细节,可查阅Inclusion AI团队发布的相关论文;对企业而言,也可关注其“开放联盟”动态,未来或许能将自家应用接入平台,获取更定制化的模型评估数据。