搜索
首页
大数快讯
大数活动
服务超市
文章专题
出海平台
流量密码
出海蓝图
产业赛道
物流仓储
跨境支付
选品策略
实操手册
报告
跨企查
产业带
导航
知识体系
工具箱
产业园
更多
百科
找货源
跨境招聘
DeepSeek
首页
>
科普贴 | 只谈面数就是耍流氓!数字孪生场景渲染的短板原理
>
科普贴 | 只谈面数就是耍流氓!数字孪生场景渲染的短板原理
DataMesh
2022-07-07
1
导读:经常碰到客户问 – 我们厂里设备的3D设备模型都有,你们的数字孪生平台导入模型的时候能支持多大的面数啊?
经常碰到客户问 – 我们厂里设备的3D设备模型都有,你们的数字孪生平台导入模型的时候能支持多大的面数啊?
这个问题,我可以回答最高支持上千万面,但这个可能和用户实际用的体验完全不同,究其根本原因,是3D渲染的效率被短板原理决定,瓶颈总出在细节上,而不是一个简单的面数,就拿我们的DataMesh Director这个应用来说,同一个iPad上,几千万面的体育馆BIM模型渲染可以非常流畅,也出现过几万面的开关模型卡到不动的情况,猜猜看这是什么原因呢?
在整个3D渲染流程中,有非常多的因素会制约渲染效率,无论是从帧率还是从规模看,用户需要对自己希望构建的场景有较好的容量规划,尽量利用平台能力,同时优化内容,减少短板。优化的逻辑可以写几本书,在这里我们先介绍一个非常常见但用户通常不了解的机制,也就是Draw Call数量。在数字孪生类应用中,使用Draw Call估算比面数估算更容易直观地判断应用性能。
什么是Draw Call?
Draw Call这个词在游戏行比较常见,没有对应的翻译,简单来说,就是CPU向GPU发出“画丫的”这个指令的过程,在Unity、UE等开发工具中统称为Draw Call,在OpenGL、DirectX、Metal等渲染引擎中对应的是glDrawElements、drawIndexedPrimitives等命令。在这个过程里,CPU会把一系列要干的事情塞到命令缓冲区(Command Buffer),GPU去执行缓冲区的命令。
比如说你要画一个物体,那我们就要有前置的准备工作,把你要画什么都准备好,再写入队列里去。但是一个物体可能有不同的材质贴图等信息,这样也可能会产生多个Draw Call。无论这个缓冲区怎么执行,最终的渲染质量是一致的,但帧率可能会差异很大。
Draw Call的数量为什么会影响渲染?
由于CPU和GPU的效率差异很大,如果塞得不够快,就会出现GPU等CPU的瓶颈;塞得太快,会出现CPU等GPU的瓶颈。但是通常来说,GPU比CPU要快很多,每次调用Draw Call又有不小的成本,因此Draw Call的数量会严重影响到渲染效率,我们就需要尽量批处理(Batch)这个工作,让一个Draw Call尽可能塞更多的东西,而不是产生更多的Draw Call。Unity里Draw Call数量就直接叫做Batch Count。
换个说法,同体积的话,你觉得在电脑上拷贝一千个小文件的速度和一个大文件的速度哪个更快?
在处理大量Draw Call时,CPU和拷贝小文件时的状态类似,每处理一个文件/发出一个Draw Call都绕不开刚才说的前置各类准备工作。假定我们的单一一个小文件(小物体)的实际工作处理时间是X,前置工作时间是Y,那么1000个小文件(小物体)的总处理时间是1000*X+1000*Y,而一个大文件(小物体合并打包)的总处理时间相对来说是1000*X + Y。
对,差了999个Y的时间。这个Y的时间是没法忽视的,在CPU算力越弱的平台上Y的影响越大。
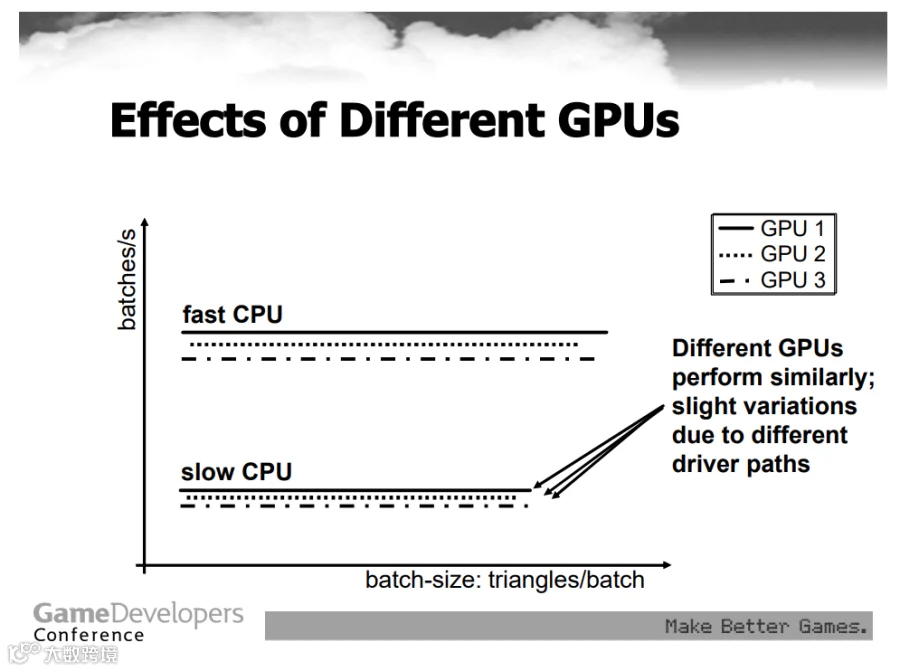
英伟达在很久很久以前有个著名的演讲叫“Batch, Batch, Batch!”,说的就是这个问题,有兴趣可以点击文末
“阅读原文”
里的链接
看看,里面讲的到现在也没怎么过时。
(以下为部分截图👇)
因此,尽量优化Batch里能塞多少内容是解决CPU到GPU的阻塞问题的关键之一。
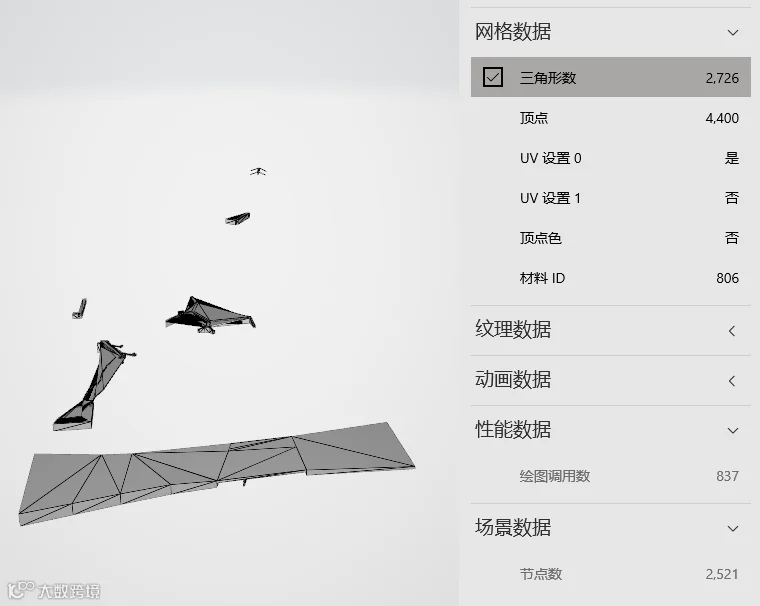
举例来说,日本国土交通省用倾斜摄影建的这组模型,就出现了三角面数很低,绘图调用数(Draw Call)很高的问题。虽然只有2000多个面,但是在微软3D查看器里显示却产生了800多个Draw Call,模型信息少得可怜,终端加载卡的要死。如果你仔细分析这个模型,他是由800多个子物体碎片构成的,这是倾斜摄影模型处理时的常见情况 – 国土交通省把一个半拉子货发布给大众了,不再次处理是没什么用的。
对于降低Draw Call数量的处理办法有很多,但无论是前置优化处理、后置优化处理,由于数据源的不同,在数字孪生场景里和游戏产业是有很大差异的,具体的我们以后再说。
为什么B/S架构的渲染能力烂泥扶不上墙?
前些年浏览器战争打的惨烈,给人了一种浏览器无所不能的感觉,nodejs被捧上天,很多前端公司卷了各种可视化面板之后,又卷到使用Three.js去调用WebGL插入到原有的面板中做展示大屏,一时风生水起。简单的场景在B/S架构下没有任何问题,但投入实际应用后,设备和结构数量增大时,B/S架构的加载速度、显示效率就跟不上了,甚至直接崩溃。
同理,到现在也没有几个认真的游戏公司能在浏览器里做复杂的模拟游戏。
原因很简单,在浏览器里用WebGL渲染3D物体的开销,与原生应用比,大概是10-100倍的关系。即使是用WebAssembly去做,极限性能的差异也非常明显。
尤其是上面所说的Draw Call的代价 – 前置工作的成本由于浏览器在中间的介入变得极高,当物体数量变多时Y的影响变得非常糟糕,这就是所谓的浏览器税。
在一些极端情况下,如果你用浏览器能以固定帧率渲染十台机器人跑到不掉帧的边缘,同一台机器C/S架构可能可以渲染一百台以上,数字孪生场景又经常是这种大量设备、大量数据点位的情况,B/S的一招鲜就不奏效了。有些导入了BIM的场景甚至可能会更糟,我们见过不少企业单位自制的系统,光是载入就一层层加载了几分钟,领导汇报也许还能对付过去,要说日常使用真的太强人所难了。
对于做监控大屏这个具体场景来说,B/S架构可以采取总 – 分的形式进行导航优化,让同屏Draw Call数减少到极限值以下,同时使用极致优化过的手绘模型。
但是对于数字孪生的全场模拟仿真场景,B/S架构就力不从心了,因为极限值太低,只能把所有的计算放到服务端完成,或者是用远程渲染的方式来做。但这种模式本质上其实还是C/S架构,只不过在最终用浏览器打开了客户端的渲染结果而已,不仅对网络连接和带宽高度依赖,而且有潜在的权限安全隐患 – 对于这类应用我们的评价是 – 你开心就好。此外,B/S结构在移动设备上由于浏览器支持更差很难有扩展性,现在基本上属于只能简单看看模型的状态。
我们当然不能排除未来浏览器端能有办法绕开高额渲染开销问题的办法,只不过目前看起来这并不是业界的普遍努力方向。在应用中,用户应该根据实际场景的新需求和平台能力去选择技术架构,而不是让旧观念先入为主,这样才能减少项目失败的可能性。
公众号|DataMesh
微博|DataMesh商询科技
长按扫码关注我们
点击“阅读原文”了解更多
【声明】内容源于网络
0
0
DataMesh
Digital Twin +XR + AI 构建工业元宇宙,赋能一线工作者。
内容
225
粉丝
0
关注
在线咨询
DataMesh
Digital Twin +XR + AI 构建工业元宇宙,赋能一线工作者。
总阅读
43
粉丝
0
内容
225




 DataMesh
DataMesh