

2025年8月16日,VentureBeat发布深度文章,聚焦大语言模型(LLM)的核心进化逻辑——反馈循环。LLM的初始性能并非决定产品生命力的关键,能否通过用户交互持续学习,才是区分“惊艳demo”与“长效产品”的核心,而反馈循环正是多数AI部署中缺失的关键层。
一、为何静态LLM会陷入性能瓶颈?
AI产品开发中存在一个常见误区:认为完成模型微调或优化提示词后,产品就“大功告成”。但实际部署中,LLM的局限性会逐渐显现:
LLM本质是概率模型,并非真正“理解”信息,面对实时数据、边缘场景或更新内容时,性能易下降或偏离预期;
应用场景变化、用户非常规表述,甚至品牌调性、领域术语的细微调整,都可能导致原本稳定的输出失效;
优秀的LLM系统需突破“仅依赖初始训练”的模式,通过结构化信号与产品化反馈循环,实现持续学习。
二、LLM反馈类型:不止“点赞/差评”
二进制的“ thumbs up/down ”是LLM应用中最常见的反馈方式,但它无法捕捉用户不满的具体原因(如事实错误、语气不符、信息不全等),易造成数据解读偏差。要实现系统智能的实质性提升,需构建多维度反馈体系:
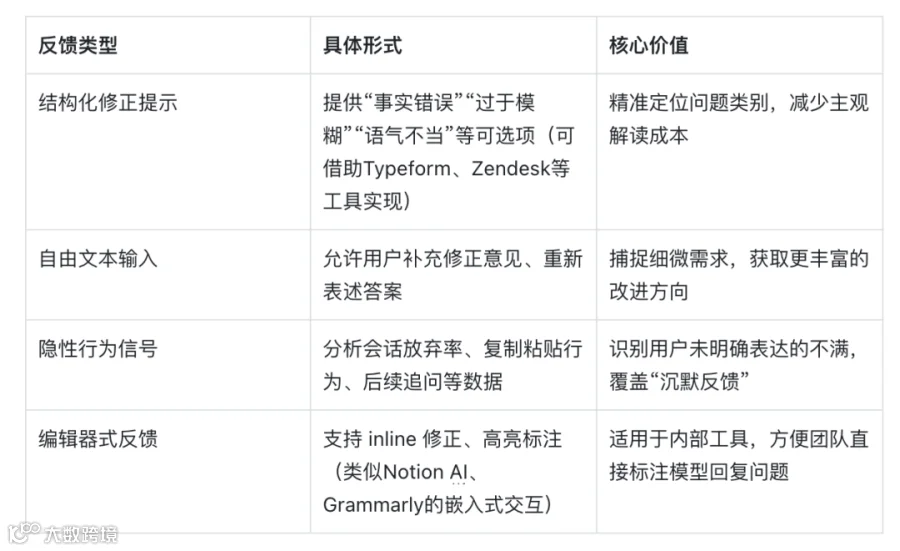
这些反馈形式能构建更丰富的训练基础,为提示词优化、上下文补充等提供方向。
三、如何存储与结构化反馈?
收集反馈只是第一步,只有将其结构化、可检索,才能转化为提升模型性能的动力。建议从三方面搭建反馈架构:
- 用向量数据库实现语义召回
将用户反馈(如“标记某金融建议有误”)与对应交互内容嵌入向量数据库(如Pinecone、Weaviate),未来遇到相似用户输入时,可快速匹配历史问题案例,避免重复错误,或动态补充优化后的上下文。
- 为反馈添加结构化元数据
给每条反馈标注关键信息:用户角色、反馈类型(如“事实错误”)、会话时间、模型版本、部署环境(开发/生产)等。这些元数据能帮助团队分析长期反馈趋势,定位特定版本或场景的问题。
- 记录可追溯的会话历史
完整日志需覆盖“用户查询→系统上下文→模型输出→用户反馈”的全链条,便于团队精准诊断问题根源(如“是上下文缺失导致回答偏差,还是提示词设计不足”),为后续提示词调优、训练数据筛选等提供依据。
这三大组件能将分散的用户意见转化为结构化“燃料”,让持续改进成为系统设计的一部分,而非事后补充。
四、何时及如何“闭环”反馈?
并非所有反馈都需相同处理方式,三类核心闭环策略:
- 上下文注入:快速灵活调整
针对高频反馈(如“回答语气过正式”),直接在系统提示词或上下文栈中补充指令(如“对消费者用户使用口语化表达”),可借助LangChain的提示词模板、Vertex AI的上下文锚定功能实现,适合快速迭代场景。
- 模型微调:解决深层问题
若反馈反复指向同一深层问题(如“对医疗领域术语理解不足”),则需启动微调。需注意:微调成本高、复杂度高,仅适用于高置信度的改进需求。
- 产品层调整:用UX弥补AI不足
部分问题并非LLM性能问题,而是产品设计缺陷。例如,用户因“无法找到历史对话”放弃使用,此时优化界面导航比调整模型更有效,能直接提升用户信任度与使用体验。
此外,特别强调“人工参与”的重要性:部分边缘案例需人工审核,领域专家需筛选优质反馈作为训练样本,“人机协同”仍是生成式AI时代的关键闭环环节。
五、将反馈视为产品战略
AI产品并非静态存在,需在自动化与用户交互间动态适配。团队若将反馈视为战略核心,能打造更智能、更安全、更贴合人类需求的AI系统:
“对待反馈应像对待产品监控数据一样——做好埋点、持续观察,并将其导向系统可优化的环节。毕竟,‘教会模型学习’不只是技术任务,本身就是产品的核心价值。”