

2025年10月21日,DeepSeek AI研究团队正式发布技术博客,详解DeepSeek-OCR的核心原理与应用价值。这款以“光学2D映射”为核心的OCR系统,通过“文本转视觉”的创新思路,实现长文本7-20倍压缩,同时保持高识别精度,为大模型(LLM)处理海量文档提供了全新解决方案,目前代码与模型权重已开源至GitHub。
开源地址:https://github.com/deepseek-ai/DeepSeek-OCR
一、核心突破:四大革命性优势,重新定义OCR效率
DeepSeek-OCR并非传统OCR工具的升级,而是通过底层技术创新,在“压缩比、效率、性能、 scalability”四大维度实现突破,彻底改变长文本处理逻辑。
1. 超高压缩比+高精度:10倍压缩仍保96%识别率
传统文本编码需用大量Token承载信息,而DeepSeek-OCR通过视觉映射实现“Token瘦身”,关键数据如下:
压缩比9-10倍时,OCR识别精度达96%以上,满足学术论文、企业合同等高精度场景需求;
压缩比10-12倍时,精度维持在90%左右,适用于新闻、报告等非关键信息处理;
即使压缩比提升至20倍(极端轻量化场景),仍能保持60%精度,可用于文本检索、关键词提取等基础任务。
这一表现证明,视觉 tokens 能以更少的计算成本,承载与文本 tokens 相当的信息密度。
2. DeepEncoder架构:低内存占用,高分辨率也不“崩”
作为系统的“压缩核心”,DeepEncoder通过三大设计解决传统视觉编码器的痛点:
混合注意力机制:串联“窗口注意力”(聚焦局部文字细节)与“全局注意力”(把控文档整体布局),既避免细节丢失,又不遗漏版式逻辑;
16倍卷积压缩层:在注意力计算前,先将高分辨率图像的视觉 tokens 压缩16倍,例如1024×1024图像的 tokens 量可从4096个降至256个,彻底解决GPU内存溢出问题;
多分辨率适配:无需调整架构,即可处理从手机拍摄(512×512)到高清扫描(1280×1280)的不同分辨率文档,适配多样化输入场景。
3. 性能碾压竞品:用最少tokens拿最优结果
在权威文档处理基准测试OmniDocBench中,DeepSeek-OCR展现出“用更少资源办更多事”的优势:
对比GOT-OCR2.0:后者每页需256个 tokens,而DeepSeek-OCR仅用100个视觉 tokens,精度仍更高;
对比MinerU2.0:后者每页平均需6000+ tokens,DeepSeek-OCR用不到800个视觉 tokens 即可超越其性能;
成为端到端OCR模型中“视觉 tokens 用量最少、综合性能最优”的方案,大幅降低推理成本。
4. 生产级 scalability:单A100日处理20万页
不同于实验室模型,DeepSeek-OCR已具备大规模落地能力,算力效率突出:
单张A100-40G GPU,每日可处理20万+页文档,相当于10名人工录入员的月工作量;
20个节点(共160张A100-40G)集群,日处理量可达3300万页,能支撑跨国企业、国家级档案馆的海量数字化需求;
可直接用于LLM/VLM的训练数据生成,为大模型提供高质量、大规模的文本-视觉对齐数据。
二、技术拆解:从架构到训练,读懂DeepSeek-OCR的“底层逻辑”
要理解其优势来源,需从“视觉编码器对比”“MoE解码器”“训练 pipeline”三方面拆解技术细节。
1. 视觉编码器:取长补短,解决三大传统方案痛点
当前开源视觉语言模型(VLM)的编码器存在明显缺陷,DeepEncoder则融合各方优势:
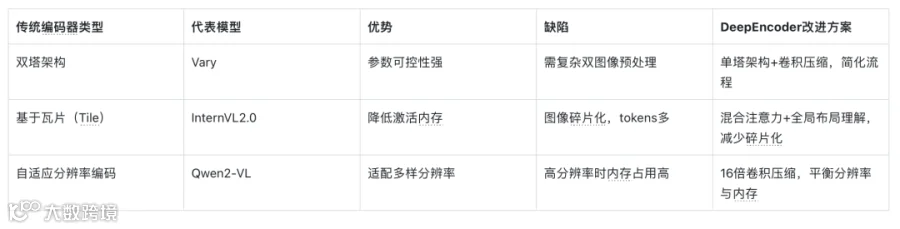
2. MoE解码器:高效推理,专家分工提升精度
解码器采用DeepSeek3B-MoE-A570M混合专家模型,核心设计逻辑是“专业事交给专业专家”:
总参数30亿,但每次推理仅激活5.7亿参数(64个专家中选6个),计算量仅为同规模稠密模型的1/5,兼顾精度与速度;
不同专家分工明确:部分专家专注“文字识别”,部分专攻“版式解析”,还有专家负责“公式/图表还原”,通过协同提升复杂文档处理能力;
支持动态专家选择,简单文本(如纯文字新闻)仅调用少量专家,复杂文档(如含公式的论文)自动激活更多专家,进一步优化算力分配。
3. 训练 pipeline:两步走,数据引擎保障泛化性
为确保模型在不同场景下的稳定性,DeepSeek-OCR采用“分阶段训练+多源数据”策略:
第一步:训练DeepEncoder:单独优化视觉编码器的压缩能力,用OCR 1.0(传统OCR数据集)、通用视觉数据(多样化图像)做预训练,确保其能高效将文本转为视觉 tokens;
第二步:训练完整系统:将编码器与MoE解码器结合,用OCR 2.0(含合成与真实复杂文档)、文本-only数据(纯语言数据)做微调,让模型既懂“看图”,又懂“读文”;
数据多样性:覆盖多语言(40+语种)、多版式(横排/竖排/表格)、多场景(印刷体/手写体/模糊文本),确保模型在不同行业落地时无需大量二次训练。
三、应用场景:不止“识别文字”,解锁四大创新用法
DeepSeek-OCR的价值远超传统OCR,其“视觉压缩+长文本处理”能力,在多个领域打开新可能:
1. 历史文档数字化:低存储成本保存文化遗产
图书馆、档案馆的历史文档(如古籍、老报纸)数量庞大,传统扫描存储占用空间大,DeepSeek-OCR可将其压缩7-20倍后存储,同时保留关键信息,既节省服务器成本,又方便后续检索。
2. LLM内存机制优化:为大模型“扩容”上下文
当前LLM的上下文窗口受限于Token数量,DeepSeek-OCR的视觉压缩可帮其“突破限制”:将长文本压缩为少量视觉 tokens 输入LLM,相当于间接扩展上下文长度,让模型能一次性处理整本书、整套合同,无需分段解析。
3. 复杂文档深度解析:公式、图表也能“读懂”
区别于传统OCR仅能识别纯文字,DeepSeek-OCR可处理多类型内容:
精准还原数学公式、化学结构,并转化为LaTeX格式,方便科研人员编辑;
解析表格数据,保留行列关系,输出可编辑的Excel/CSV文件;
识别自然图像中的嵌入式文本(如广告图中的文字、截图中的对话),适用于社交媒体内容分析。
4. 大规模训练数据生成:为LLM/VLM“喂料”
单A100日处理20万页的能力,让DeepSeek-OCR成为大模型训练的数据“生产机”:可快速将海量文档转化为“文本-视觉对齐”的训练数据,用于提升LLM的长文本理解能力、VLM的文档处理能力,加速大模型迭代。
四、开源与未来:代码已开放,重新思考“视觉与语言”的关系
DeepSeek-OCR不仅是一款工具,更提出了一个重要命题:“对于文本,视觉 tokens 是否比文本 tokens 更高效?”
目前,其代码与模型权重已开源至GitHub仓库,开发者可直接:
复现论文中的实验结果,验证技术可行性;
基于现有架构开发定制功能(如适配特定行业文档);
将其集成到自有系统(如企业OA、科研工具),降低开发成本。
未来,DeepSeek AI团队计划进一步优化模型:提升低分辨率文本的识别精度、支持更多语种、探索与LLM的深度融合(如直接让LLM理解视觉 tokens)。正如博客中所说:“这一范式不仅改变OCR,更将重新定义视觉与语言模态的协同方式,让AI处理长文本更高效、更经济。”