
在大语言模型(LLM)领域,开源社区的发展速度令人惊叹。然而,关于如何科学地扩展模型规模,业界一直存在不同的声音和结论。今天,我们要介绍的 DeepSeek LLM 项目,不仅带来了性能卓越的开源模型,更重要的是,它为我们揭示了大模型训练背后的科学规律。
一、什么是 DeepSeek LLM?
DeepSeek LLM 是一个完全从零开始训练的开源大语言模型系列,包含 7B 和 67B 两个版本。这个项目最大的特点是秉承"长期主义"理念——不追求短期效果,而是深入研究模型扩展的底层规律,为未来持续改进打下坚实基础。
核心数据:
预训练数据:2 万亿 tokens(中英文为主,持续扩充中)
模型规模:7B 和 67B 两个版本
性能表现:67B 版本在多项基准测试中超越 LLaMA-2 70B,Chat 版本媲美 GPT-3.5
二、训练大模型的"配方"是什么?
训练一个大语言模型,就像烹饪一道复杂的菜肴。你需要准备好食材(数据)、选择合适的烹饪方法(模型架构)、掌握火候(超参数),还要有一套高效的厨房设备(训练基础设施)。
数据准备:质量决定上限
DeepSeek 团队在数据准备上下了很大功夫。他们将数据处理分为三个关键阶段:
1. 去重(Deduplication)
你可能想不到,互联网上的重复内容有多严重。团队发现,如果只对单个数据集去重,大约能去掉 22% 的重复内容。但如果对 91 个不同时期的 Common Crawl 数据一起去重,重复率高达 90%!这意味着,大部分网页内容其实是重复的。
2. 过滤(Filtering)
不是所有数据都值得学习。团队开发了一套评估体系,从语言特征和语义内容两个维度评估文档质量,就像给每篇文章打分一样,只保留高质量的内容。
3. 重新混合(Remixing)
数据分布不均衡怎么办?团队会适当增加某些稀缺但重要领域的数据比例,确保模型能学到更全面的知识。
模型架构:站在巨人的肩膀上
DeepSeek LLM 的基础架构借鉴了 LLaMA 的设计,但做了一些巧妙的调整:
7B 模型:30 层网络
67B 模型:95 层网络,采用分组查询注意力(GQA)机制降低推理成本
有意思的是,67B 模型选择增加网络深度(95 层)而不是加宽网络,这样能获得更好的性能,同时便于训练和推理时的并行计算。
学习率策略:不走寻常路
大多数模型使用余弦学习率衰减,但 DeepSeek 团队选择了多阶段学习率策略:
前 80% 训练:学习率降至最大值的 31.6%
80-90%:进一步降至 10%
最后 10%:保持在 10%
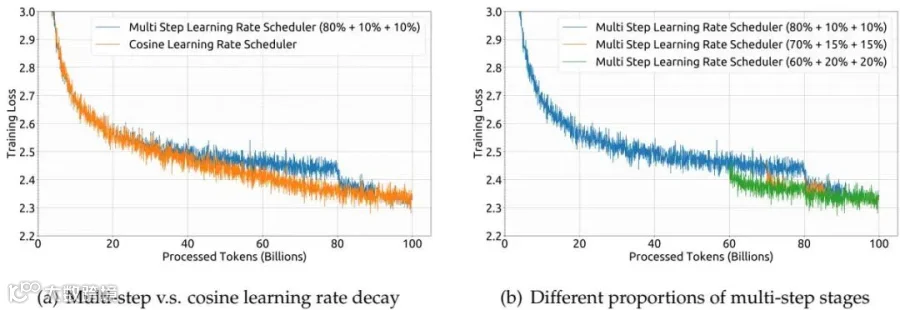
如图所示,虽然多阶段策略的损失下降曲线与余弦策略有所不同,但最终性能相当。更重要的是,这种策略便于继续训练——如果想继续训练更多数据,可以直接复用前面阶段的训练成果。
三、破解扩展定律的秘密
训练大模型最大的挑战是:在算力有限的情况下,如何分配模型规模和数据规模?这就是"扩展定律"(Scaling Laws)要回答的问题。
超参数的扩展规律
DeepSeek 团队首先研究了批次大小和学习率的最优设置。他们发现:
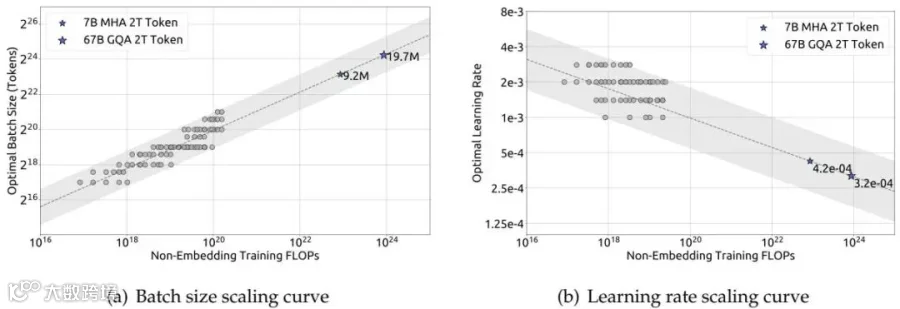
批次大小:随着计算量增加而增大,遵循幂律关系
学习率:随着计算量增加而减小,同样遵循幂律关系
这个发现非常实用——给定计算预算,可以直接用公式算出最优的批次大小和学习率,不需要再手动调试。
模型与数据的最佳配比
这是扩展定律中最核心的问题:增加计算量时,应该把资源投向更大的模型,还是更多的数据?
以往研究给出的答案差异很大。OpenAI 的研究认为应该主要扩大模型(73% 资源给模型,27% 给数据),而 DeepMind 的 Chinchilla 研究则认为应该均衡分配(约 50:50)。
DeepSeek 团队发现了答案的关键:数据质量决定最优分配策略。
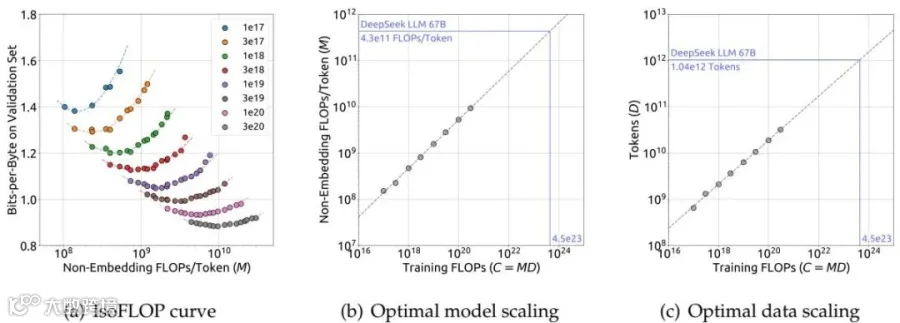
他们用三种不同质量的数据集做实验:
早期内部数据:模型扩展系数 0.450
当前内部数据:模型扩展系数 0.524
OpenWebText2(高质量):模型扩展系数 0.578
结论很清晰:数据质量越高,越应该把资源投向模型扩展。这解释了为什么不同研究会得出不同结论——他们用的数据质量不同!
性能预测:小实验预测大模型
更令人兴奋的是,基于小规模实验建立的扩展定律,能够准确预测大规模模型的性能。
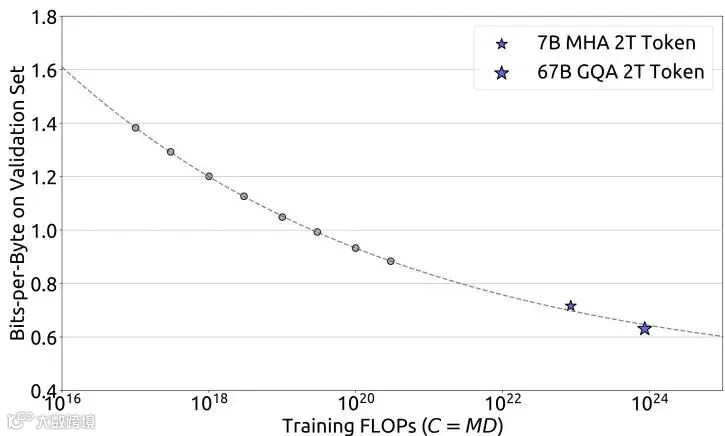
如图所示,用计算量小 1000 倍的实验建立的预测曲线(虚线),能够准确预测 DeepSeek LLM 7B 和 67B 的实际性能(蓝色星标)。这为训练更大规模的模型提供了信心和指导。
四、从基础模型到对话助手
训练好基础模型只是第一步,要让模型真正有用,还需要对齐(Alignment)训练。
监督微调(SFT)
DeepSeek 收集了约 150 万条指令数据,涵盖:
31.2% 通用语言任务
46.6% 数学问题
22.2% 编程练习
30 万条安全相关数据
有趣的发现:
小模型需要更多训练:7B 模型微调 4 轮,67B 模型只需 2 轮(大模型容易过拟合)
数学数据会导致重复问题:过多的数学推理数据会让模型产生重复输出,需要两阶段训练来解决
直接偏好优化(DPO)
为了进一步提升对话能力,团队使用 DPO 算法让模型学习人类偏好。结果显示,DPO 能显著提升开放式对话能力,但对标准测试分数影响不大。
五、性能表现如何?
基础模型:全面超越 LLaMA-2
尽管 DeepSeek 使用中英双语数据训练(可能导致语言冲突),但性能依然出色:
亮点领域:
数学推理:MATH 数据集 18.7%,GSM8K 达到 63.0%
代码能力:HumanEval 42.7%,MBPP 57.4%
中文理解:C-Eval 66.1%,CMMLU 70.8%
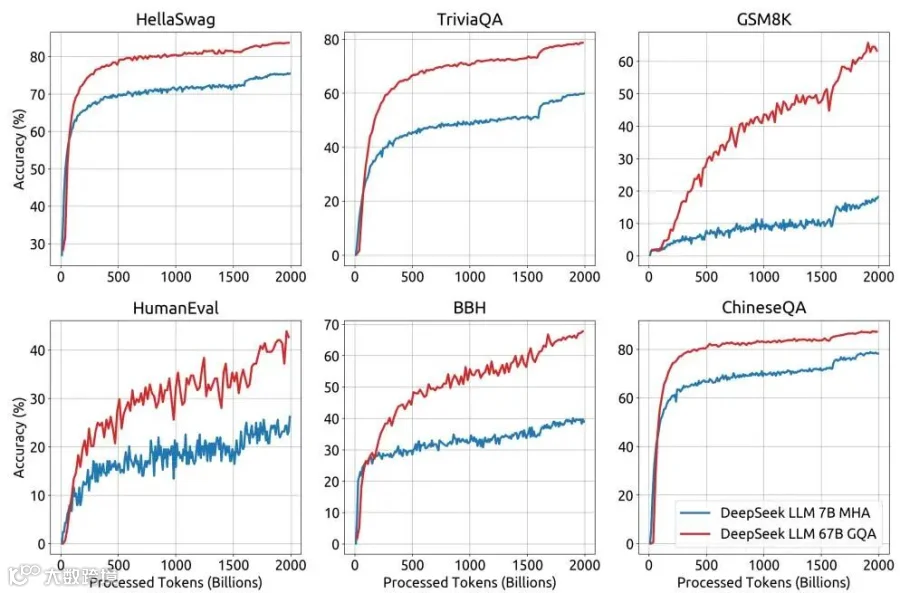
从训练曲线可以看出,模型在各项任务上都呈现稳定的提升趋势,尤其是数学和代码任务在大模型上有明显的涌现效应。
Chat 模型:媲美 GPT-3.5
中文开放对话(AlignBench)
总分 6.69,超越 GPT-3.5(6.08)
仅次于 GPT-4 系列
DPO 版本进一步提升到 6.69,在多个维度达到第一梯队
英文开放对话(MT-Bench)
得分 8.35,与 GPT-3.5 相当
DPO 版本达到 8.76,仅次于 GPT-4
新数据集测试:真实实力的体现
为了避免测试集污染,团队用最新的数据集测试:
LeetCode 周赛(2023 年 7-11 月)
DeepSeek 67B Chat:17.5%
远超其他开源模型
匈牙利高中数学考试
DeepSeek 67B Chat:58 分
展现出接近人类学生的数学能力
指令遵循评估(IFEval)
DeepSeek 67B Chat:55.5%
说明模型具有良好的指令理解能力
六、安全性:负责任的 AI
DeepSeek 团队组建了 20 人的专家团队,构建了全面的安全评估体系,涵盖:
歧视与偏见问题
侵犯他人合法权益
商业秘密与知识产权
违法违规行为
其他安全问题
在 2400 个安全测试问题中,DeepSeek 67B Chat 表现出色,安全回答率达到很高水平。在 Do-Not-Answer 数据集上,得分 97.8,超过 ChatGPT(97.7)和 GPT-4(96.5)。
七、一些有趣的发现
在开发过程中,团队还发现了一些有意思的现象:
1. 系统提示词的效果取决于模型大小
对于 7B 模型,添加系统提示词反而会轻微降低性能(从 7.15 降到 7.11)。但对于 67B 模型,系统提示词能显著提升性能(从 8.35 升到 8.58)。
原因:大模型更能理解系统提示词的含义并正确遵循指令,而小模型可能会被复杂的提示词困扰。
2. 选择题数据的两面性
添加大量选择题数据能显著提升 MMLU、C-Eval 等多选题基准的分数(从 47% 提升到 71%),但对开放问答能力没有帮助。
结论:为了避免过度拟合测试集,团队决定不在预训练和微调中使用选择题数据。
3. 模型大小带来的质变
虽然 7B 和 67B 模型使用相同的训练流程,但在新数据集上的表现差距显著。这说明算力投入确实能带来模型"智能"的质变,而不仅仅是量变。
八、局限性与未来方向
团队也坦诚地指出了当前的局限:
当前局限:
预训练后知识无法更新
可能生成未经验证的信息
存在幻觉问题
中文数据覆盖还不够全面
对英语以外的其他语言支持有限
未来计划:
即将发布:代码智能和混合专家(MoE)模型的技术报告
数据扩充:构建更大更优质的数据集,提升推理、中文知识、数学和代码能力
对齐研究:通过强化学习提升模型的复杂推理能力,打造有用、诚实、安全的模型
九、写在最后
DeepSeek LLM 项目最大的价值,不仅在于提供了性能出色的开源模型,更在于系统性地研究了大模型训练的科学规律。他们的研究回答了几个关键问题:
如何科学地选择训练超参数?通过扩展定律建立公式,可以根据计算预算直接计算最优参数。
模型和数据如何平衡?答案是:取决于数据质量。高质量数据支持训练更大的模型。
小实验能预测大模型吗?可以!扩展定律让我们能用小规模实验准确预测大模型性能。
如何避免测试集过拟合?不要在训练中使用过多选择题数据,专注提升模型的真实能力。
这种长期主义的研究理念,为开源社区提供了宝贵的经验和工具。随着 DeepSeek 团队持续改进数据质量和模型能力,我们有理由期待未来会有更强大的开源模型出现。
对于想要训练自己大模型的研究者和开发者来说,DeepSeek LLM 的经验告诉我们:不要盲目追求规模,而要先搞清楚扩展的科学规律;不要急于求成,而要打好数据和方法的基础。正如项目名称所示,这是一条需要长期主义精神的道路。
参考资料
DeepSeek LLM 论文:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek 官网:https://www.deepseek.com