转载请微信联系:huangdiezi,更多DAO、Web3、NFT、Metaverse资讯请关注老雅痞👇
网站https://allrecode.com/ 点击阅读原文进网站查看更多资讯。
信息来源自Engadget,略有修改,作者Daniel Cooper
编译:RR

1917年,马塞尔·杜尚用假名向独立艺术家协会提交了一件雕塑作品。他从一家厕所供应商那里买来一个小便池,并把它取名为喷泉。喷泉的侧面用黑色油漆写着R. Mutt的签名。杜尚想看看该协会是否会遵守承诺,在没有审查或偏袒的情况下接受该作品(没有)。但杜尚也想拓宽艺术的概念,他说,在合适的环境下,一件现成品是有资格成为艺术的。1962年,安迪·沃霍尔以《金宝汤罐头》改变了传统,这是一个含有32副不同口味的汤罐头画作的系列。和以前一样,关于机械生产的东西——小便池或汤罐头(尽管是沃霍尔的手绘)——是否算艺术,以及这意味着什么,人们展开了激烈的辩论。
而现在,由于机器可以自己大量生产独特的艺术作品,这场辩论已经被颠覆了。生成性人工智能(GAI)是一种能够创造出在技术上(如果不是在意图上)能够与早期大师相匹敌的作品的系统。但有一个问题,因为这些系统是在现有素材的基础上训练的,通常使用从互联网上、从我们这里提取的内容。那么,未来的人工智能是否能够在不需要我们同意或补充的情况下,在我们的劳动基础上创造出一些神奇的东西吗?
新前沿
目前最著名的GAI是DALL-E 2,这是用于“根据自然语言的描述创造逼真的图像和艺术”的Open AI系统。用户输入“泰迪熊在浮世绘风格中购物”,该模型就会生成该风格的图片。同样,如果你让这些熊去古埃及购物,图片将看起来更像是博物馆里描绘法老时代生活的立体模型。在未经专门训练的人看来,这些图有些像是在17世纪的日本绘制的,或者像是在20世纪80年代的博物馆里拍摄的。尽管这项技术还处于相对早期的阶段,但这些成果已经出现了。
Open AI最近宣布,作为大规模测试的一部分,DALL-E 2将向多达100万用户开放。每个用户在第一个月可以免费生成50件产品,之后每个月可以免费生成15件。额外的115套餐可以以15美元的价格购买,该公司表示,随着产品的发展,未来可能会公布更详细的定价。最重要的是,用户有权将DALL-E制作的图像用于商业化,允许他们打印、销售或以其他方式许可。

然而,这些系统并没有培养出在封闭状态中寻找优秀图像的能力,每个GAI都必须经过训练。毕竟,人工智能是一个花哨的术语,它本质上是一种教软件如何识别的方法。旨在改善司法公正的人工智能初创公司达罗Darrow的研究主管Ben Hagag说:“你可以开发一种可以通过经验加以改进的算法。”“我所说的经验是指在数据中检查和寻找的范例。“我们对[系统]说,‘看看这个数据集,并找到范例’,然后它继续对手头的数据形成一个连贯的视图。”他说,“这就像婴儿学习一样,”如果一个婴儿看了1000张风景图片,他很快就会明白,天空——通常位于图像顶部——是蓝色的,而陆地是绿色的。
Hagag列举了谷歌是如何通过在几千兆字节的文本上训练一个系统来建立其语言模型的。Hagag说:“该模型理解了语言模式、构建方式、语法,甚至理解语言学家都很难定义的隐藏结构。”现在这个模型已经足够成熟,“一旦你给它几个单词,它就能预测你接下来要写的几个词。”2018年,谷歌的Ajit Varma告诉《华尔街日报》,其智能回复功能已经针对“数十亿条Gmail信息”进行了训练,并补充说,在最初的测试中,人们看到了诸如“我爱你”和“从我的iPhone发送”等选项,因为它们在通信中非常常见。
开发人员如果不能获得像谷歌这样庞大的数据集,就需要通过其他途径来寻找数据。Hagag说:“每个开发语言模型的研究者都会先下载维基百科,然后添加更多内容。”他补充说,他们可能会提取他们能找到的所有可用数据。几年前你发的某条推文,或者某篇真诚的Facebook帖子,都可能成为在某个地方被用来训练某人的语言模型。甚至Open AI也会将社交媒体帖子与WebText一起使用。
Huski的首席技术官 Guan Wang表示,数据的提取“非常普遍”。他说:“开放的互联网数据是目前大多数人工智能模型训练的首选。”而且,大多数研究人员的政策是尽可能多地获取数据。他补充说:“当我们寻找语音数据时,我们会得到我们能得到的任何语音。”这种数据越多,结果就越不理想,Ben Hagag引用了Airbnb前数据科学负责人Riley Newman的话说,“更好的数据胜过更多的数据”,但Hagag指出,通常情况下,“获取更多数据比清理数据更容易”。

DALL-E现在大概可供100万用户使用,但人们对GAI的第一次体验很可能是在它不那么花哨的兄弟产品上。Craiyon是法国开发者Boris Dayma的心血结晶,他在阅读了Open AI的原始DALL-E论文后开始研究他的模型。不久之后,谷歌和人工智能开发社区HuggingFace举办了一场黑客马拉松,让人们建立便捷的机器学习模型。“我建议,‘让我们复制DALL-E。我不知道该怎么做,但我们还是去做吧。”该团队最终赢得了比赛,尽管该系统只是一个简陋、粗糙的版本。他补充道,“(它生成的)图像很清晰。不是很好,但也不糟糕。”但与DALLl-E不同,Dayma的团队专注于缩小模型,使其能够在相对低功率的硬件上工作。
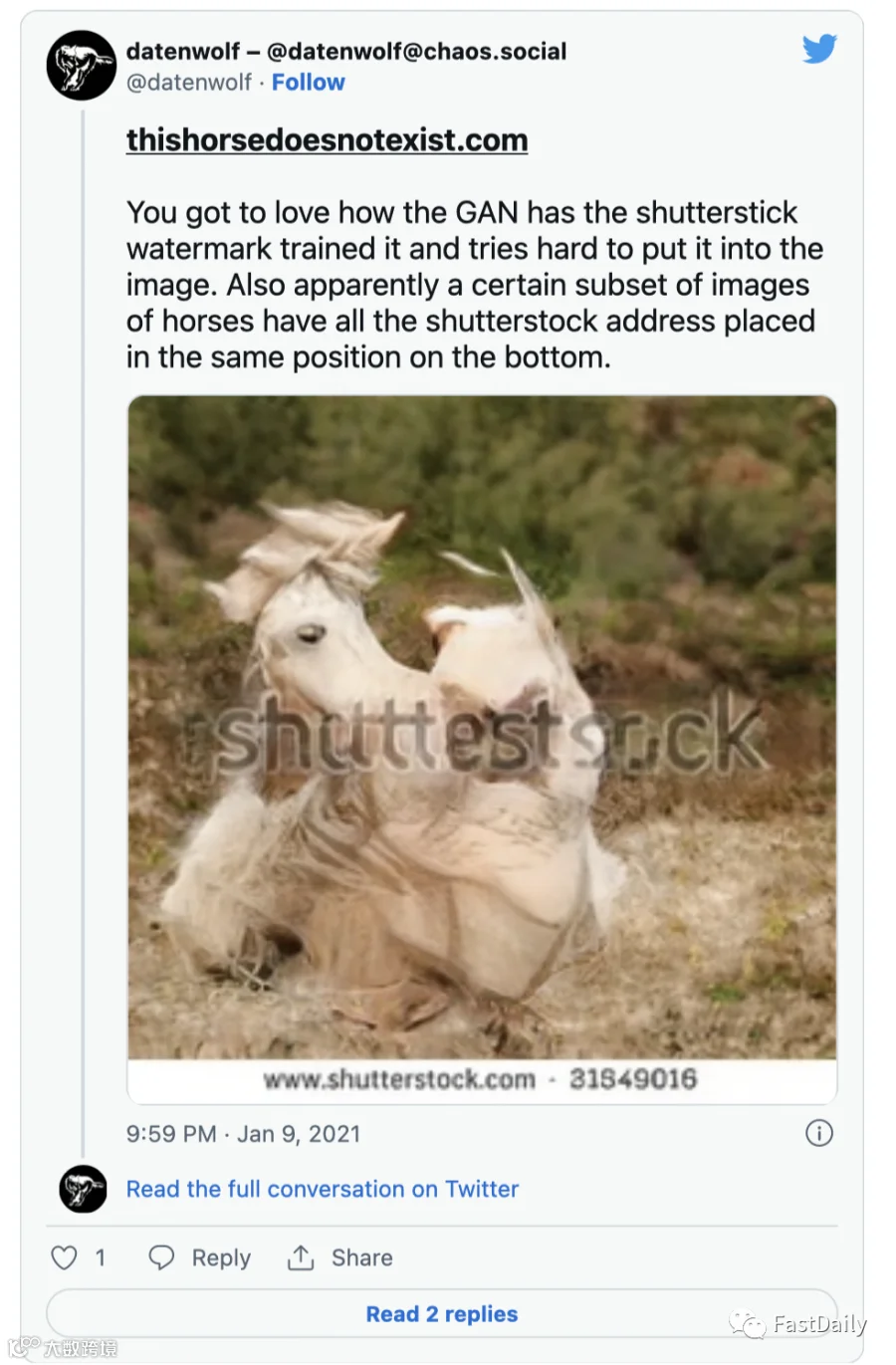
Dayma的原始模型对它将从哪些图片集中提取是相当开放的,而这通常会产生问题。他说:“在早期的模型中(以及现在的一些模型),你要求的照片上面往往会带有Shutterstock或Alamy水印。”在GAI接受面向公众的图像库(这些图像库中的内容都盖着反盗版水印)的训练后,许多人工智能研究人员都发现了这一点。
Dayma说,该模型错误地认识到,高质量的风景图像通常带有来自那些公共图库中的水印,他在此后将其从他的模型中删除。他补充说,一些早期的结果还输出了不安全的工作反应,这迫使他对初始训练集进行了进一步的改进。Dayma补充说,他必须亲自对数据进行大量的整理,并说“互联网上的很多图像都很糟糕。”
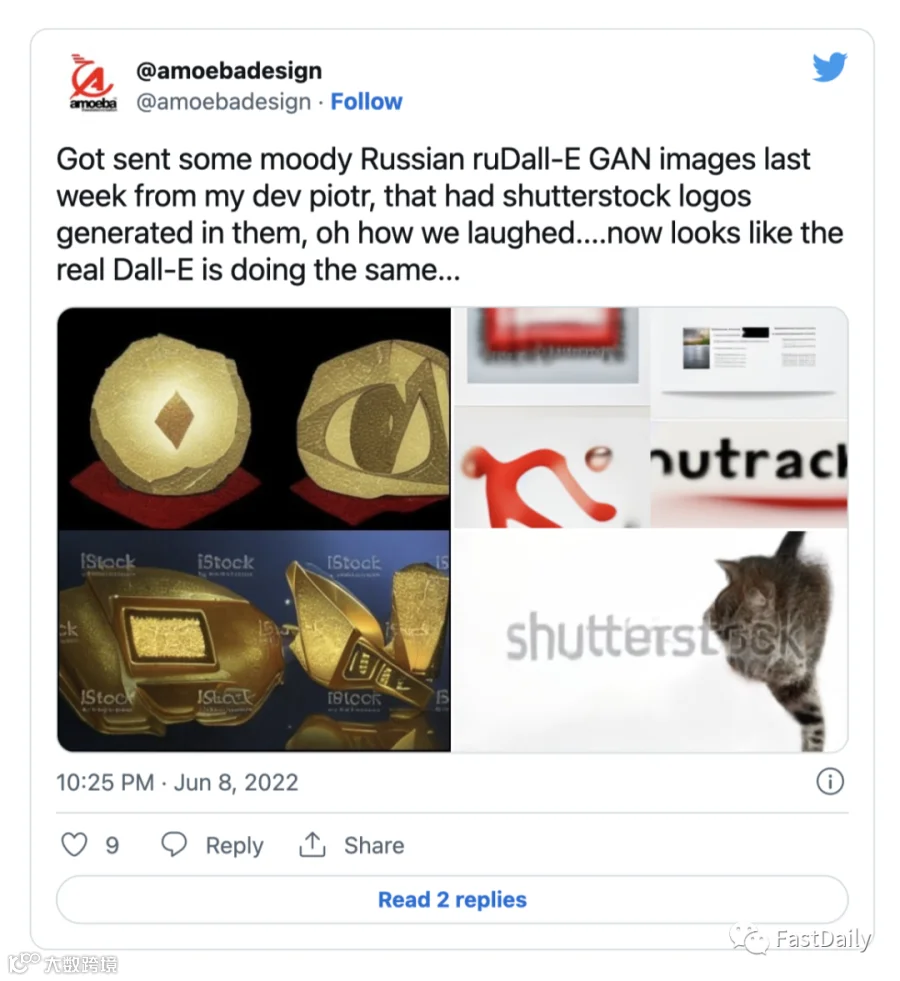
但并不是只有Dayma注意到了Shutterstock等水印经常出现在人工智能生成的艺术作品中。这就引出了一个问题:人们是否只是从Shutterstock面向公众的资料库中翻出一些东西来训练他们的人工智能?谷歌已经将一大批带有水印的Shutterstock图片作为其Conceptual Captions框架的一部分进行索引。深入研究这些数据,你会看到一个可用于训练自己的人工智能模型的图像URL列表,其中有数千张来自Shutterstock。
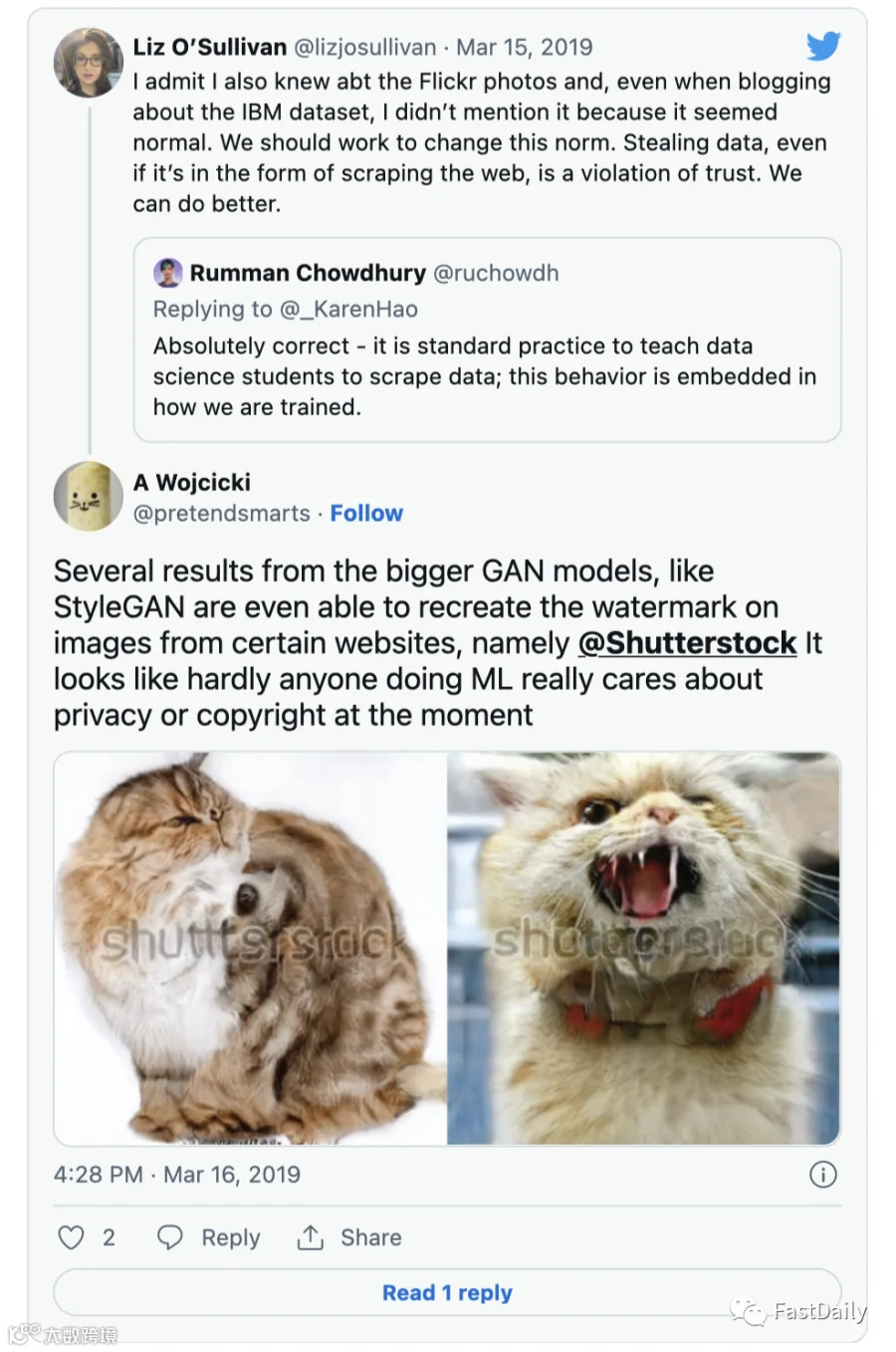
谷歌发言人表示,他们“不认为这对我们所涉及的数据集来说是个问题”。他们还引用了Creative Commons的这份报告,称“假设在输入时对版权作品的访问是合法的,在默认情况下,使用作品来训练AI应该被认为是不侵权的。”尽管Shutterstock本身明确禁止其网站的访问者使用“与该网站或Shutterstock内容有关的任何数据挖掘、机器人或类似的数据和/或图像收集和提取方法”。
人工智能初创公司Article Forge的首席执行官Alex Cardinell表示,他认为在受版权保护的文本上训练模型没有问题,“只要材料本身是合法获得的,而且模型没有剽窃材料。”他将这种情况比作学生阅读知名作家的作品,他们可能会“学习作者的风格或模式,然后找到合适的地方重新使用这些概念。”他补充说,只要一个模型不是“从它们的训练数据中复制和粘贴”,那么它只是重复自文字出现以来就存在的模式。
Dayma说,目前每天有数十万人甚至数百万人在使用他的系统。这一切都会产生托管和处理等成本,他不可能长期自掏腰包维持成本,尤其因为这仍然是一个“爱好”。因此,该网站在页面的顶部和底部都有广告,在广告之间一个由九幅超现实图像组成的网格。“对于商业用户来说,我们总是可以收费的。”但他承认,他对美国版权法的了解不够详细,无法对他自己的模型或该领域其他模型的影响进行讨论。鉴于Open AI现在允许用户出售由DALL-E创作的图片,Open AI或许自己也正在处理这种情况。
艺术相关的法律
该领域的法律情况不特别明确,尤其是在美国,很少有涉及文本和数据挖掘(TDM)的案例。这里的TDM是一个专业术语,指的是通过在大量源材料中寻找样板来训练人工智能的做法。在美国,TDM被广泛包含在合理使用范围内,它允许以访问为目的的各种形式的复制和扫描。然而,这并不是一个既定的主题,但人们认为有一个案例为这种做法树立了足够的先例。
作者协会诉谷歌案(2015)是由一个代表作者的机构提起的,该机构指控谷歌将仍受版权保护的印刷作品数字化。这项工作的最初目的是与几家图书馆合作,将文本编目并建立数据库,使研究更容易。然而,作者们担心谷歌侵犯了版权,即使它没有公开提供仍受版权保护的作品的文本,它也被禁止扫描和存储它。最终,第二巡回法院作出了有利于谷歌的裁决,称将受版权保护的作品数字化并不构成版权侵权。
Rahul Telang是卡耐基梅隆大学的信息系统教授,也是数字化和版权方面的专家。他说,这个问题是“多层面的”,谷歌案提供了“某种先例”,但它不是一个可靠的先例。他说,“这是一个复杂的问题,尤其是围绕着那些可能会也可能不会具有变革性的作品。在有一个确凿的案例之前,法院很可能会对侵犯版权的行为采用通常的检验方法,来判断作品是否取代了对原作的需要,以及它是否对原版权所有者造成了经济损害。Telang认为,各国将尽可能放松对TDM的限制,以促进国内的人工智能研究。
美国版权局表示,他们将对“由人类创作的原创作品”进行注册。这是由于唯一值得版权保护的东西是“思想的创造力”产生的“智力劳动成果”的古老先例。1991年,这一原则在一家电话簿公司的电话簿被另一家盗用的案件中得到了证实。最高法院认为,虽然电话簿的编纂过程中可能付出了努力,但其中包含的信息并不是由人类创造的原创作品,因此不能获得版权。如果用户因为这个原因试图授权或出售DALL-E作品而受到挑战,那将是很有趣的事情。
与许多大型科技公司和时尚品牌合作调查版权和商标侵权问题的私人调查员Rob Holmes认为,整个行业对解决围绕TDM和版权问题的里程碑式案件持沉默态度。他说。“法律部门拿到的钱很少。”所有这些不同的品牌,所有人都在等待其他品牌或IP所有者提起诉讼。而当他们这么做的时候,是因为某些高级副总裁或高层决定花钱,一旦这种情况发生,就会有很长的时间来计划诉讼。”这通常会给小公司足够的时间来要么自我改善,变得足够大到值得提起诉讼,要么倒闭。
Holmes说:“作为一家单独的公司,开创先例需要大量资金。”但如果对其盈利能力有直接的风险,品牌会迅速采取行动。例如,设计师品牌Hermés正在起诉一位正在制作MetaBirkins NFT的艺术家Mason Rothschild。这些图片的设计风格让人联想到爱马仕著名的Birkin手袋,这家法国时装公司说,这不过是一种老式的剽窃。这件事也可能会对这个行业产生影响,因为它正在努力解决一个哲学问题:哪些工作具有足够的变革性,可以防止对盗版的指控。
艺术家们也可以将自己的作品上传到DALL-E,然后生成自己风格的作品。我与一位艺术家进行了交谈,他向我展示了他的作品和DALLl-E制作的复制品,这些作品虽然粗糙,但仍然足够接近真品。他说,仅凭这一点,他们作为艺术家的生计就面临风险,而整个创意产业显然“注定要灭亡”。
Article Forge首席执行官Alex Cardinell表示,这种情况在工业革命时期也有先例。他说,与当时不同的是,现在的社会有一种集体责任来“确保任何被淘汰的人得到充分的支持”。人工智能领域的任何人都应该支持一个“强大的安全网”,包括“全民基本收入和免费教育”,他说,这是处于这样一场革命中的社会应该提供的“最低限度”。
根据数据进行训练
人工智能已经投入使用。例如,微软与OpenAI合作,利用GPT-3作为构建代码的一种方式。2021年,该公司宣布将该系统集成到其低代码应用开发平台,以帮助人们为微软产品开发应用程序和工具。Duolingo使用该系统来提高人们的法语语法,而像Flowrite这样的应用程序使用该系统来帮助人们更容易、更快地撰写博客文章和电子邮件。Midjourney是一款类似于DALL-E 2的艺术GAI,它最近开放了能够制作出令人惊叹的插图艺术的测试版——如果客户希望制作更多的图片或将这些图片用于商业用途,他们每月需要支付10-50美元的费用。
目前,Craiyon还不需要担心这个问题,因为目前的分辨率还很低。Dayma说:“人们问我‘为什么模特的脸不好看’,却没有意识到这不只是面部的问题。”“只是,当你画一棵树时,如果树叶乱了,你不会在意,但当脸或眼睛乱了,我们会把更多的注意力放在上面。”然而,这既需要时间来改进模型,也需要提高生成作品的计算能力的可访问性。Dayma认为,尽管存在低质量的概念,但任何GAI都需要尊重“适用的法律”,不应该被用于“有害目的”。
人工智能不仅仅是玩具或者有趣的研究项目,而是一个已经造成了大量危害的东西。以Clearview AI为例,该公司从社交媒体平台上抓取了数十亿张照片,建立了一个据称全面的图像识别数据库。据《纽约时报》报道,亿万富翁John Catsimatidis曾使用这项技术来识别他女儿的男友。BuzzFeed新闻报道称,Clearview不仅为执法部门,还为极右势力提供了访问权限。事实证明,该系统也不太可靠,据《纽约时报》报道,该系统导致了多次错误逮捕。
不需要大量ps就能合成任何图像的能力自然应该引起我们的警惕。Deepfakes,一个利用人工智能在视频中替换人脸的系统,已经被用来制作以名人为主角的成人内容。只要制造 AI 的公司能够设置护栏以防止成人内容提示,就很可能会发现漏洞。随着开源研究和开发变得越来越普遍,其他平台很可能会以不那么严格的目标进行创建。更不用说这种技术被用于政治目的的风险了,因为很容易就可以创建出可用于宣传目的的虚假图像。
当然,杜尚和沃霍尔可能已经扩展了艺术的定义,但他们并没有破坏艺术本身。如果认为自动生成图像将不可避免地导致文明的崩溃,那就大错特错了。但值得警惕的是这对艺术家的影响:如果委托GAI制作东西更容易,艺术家可能会发现自己失去了生计。更不用说这些系统以我们的数据为基础,如何以及创造了什么供销售的内容了。也许现在是时候研究一下,是否有必要实施一种保护我们的素材的方法,以防止它被人工智能香肠机咀嚼和碾碎。
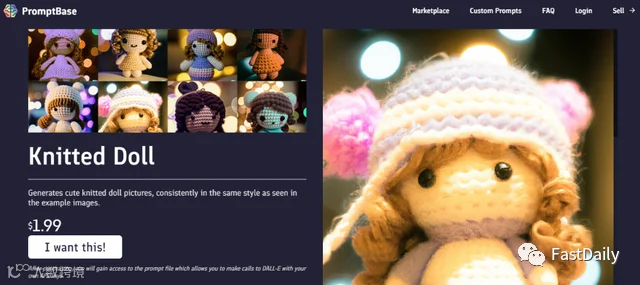
一家初创公司正在利用“给DALL-E2生产提示词”赚钱

通过OpenAI的DALL-E 2等人工智能系统找出正确的文本提示以产生最佳效果,这本身就已经成为一门科学。现在,一家初创公司希望让 “提示工程师 “通过一个销售这些精心调整的短语的在线市场来兑现。
PromptBase于6月推出,允许用户出售能在特定系统中获得可预测结果的词串。提示词的价格为1.99美元(PromptBase收取20%的佣金)提示词产生的内容包括 “病毒性 “标题、运动队标志的图片、针织娃娃和穿西装的动物。
目前,PromptBase只托管在DALL-E 2和GPT-3上测试的提示。但据其创始人Ben Stokes说,计划在未来将该平台扩展到其他系统。
Stokes过电子邮件告诉媒体:”我们的最终目标是建立工具,以帮助支持提示工程师。这是早期阶段,所以我们目前只是试图传播这个消息,寻找提示工程师来注册,并开始在我们的市场上列出他们的提示进行销售。我们已经看到大型科技公司建立了他们自己的类似于GPT-3和DALL-E的系统,我预测还会有更多的系统出现。不同的系统可能会像工具带中的工具一样被利用,类似于今天不同的编程语言的使用方式,我们计划随着它们的普及而容纳所有的系统。”
出售提示信息并不违反任何人工智能供应商的服务条款,但它有可能打开一罐道德和法律上的麻烦,这取决于所出售的提示信息的性质。此外,它揭示了即使是当今最有能力的人工智能系统的脆弱性和不可预测性。
提示工程
提示工程是人工智能中的一个概念,旨在将任务的描述(如生成毛茸茸的生物艺术)嵌入文本中。这个想法是为人工智能系统提供 “指导方针 “或详细的指示,以便它利用其对世界的知识,可靠地完成要求它做的事情。一般来说,像 “一个女人喝咖啡,走路去上班,长焦镜头 “这样的提示,其结果会比 “一个女人走路 “更加一致。
例如,提示可以用来教一个图像生成系统区分 “包含土豆的图像 “和 “土豆的集合”。它们还可以充当某种 “过滤器”,创造出具有素描、绘画、纹理、动画或甚至特定插图画家(例如莫里斯-森达克)特征的图像。而且,提示可以用不同的风格描绘同一个主题,如 “儿童画的考拉骑车 “和 “考拉骑车的老照片”。
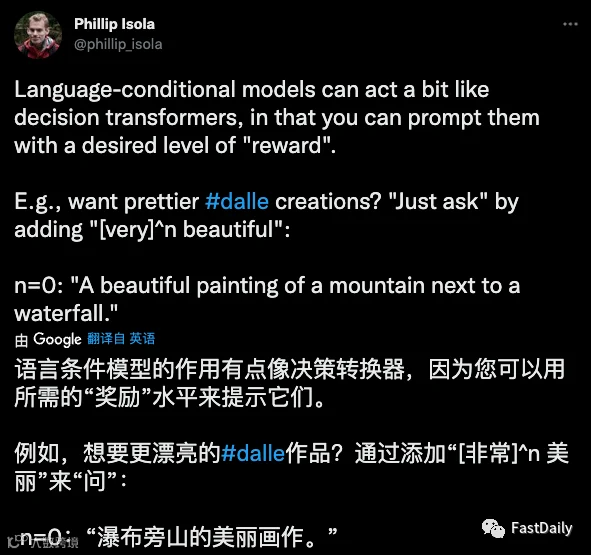
提示可以是相当细微的。由于人工智能系统对图像和文本中的模式的理解方式,并非所有的提示都有一个可预测的–甚至是合理的–结构。例如,与 “一幅非常非常漂亮的瀑布旁的山的画 “相比,提示 “DALL-E 2 “的结果更糟。原因是什么?系统对 “非常 “这个词赋予了过高的价值。
值得注意的是,”非常 “这个例子是针对《DALL-E 2》的一个特定迭代,很可能在另一个迭代中不起作用。但这是提示工程有价值的一个主要原因:发现边缘案例。

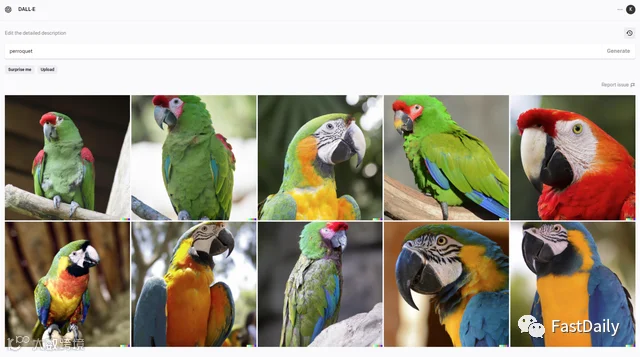
在德克萨斯大学奥斯汀分校的一项引人入胜的研究中,研究人员记录了大量可用于DALL-E 2生成图像的奇怪提示词汇。他们发现,该系统将 “Apoploe vesrreaitais”(一个胡言乱语的短语)理解为 “鸟”,将 “Contarra ccetnxniams luryca tanniounons “理解为 “虫子 “或 “害虫”(有时)。给DALL-E 2的提示 “Apoploe vesrreaitais eating Contarra ccetnxniams luryca tanniounons “得到了鸟类吃虫子的图片。
尽管这些无稽之谈可能与系统中的某些内部逻辑相对应,但这就是为什么一些数据科学家将提示比作 “咒语 “或 “魔语”–以及为什么提示工程已经催生了整个学术研究领域。
有问题的提示
一些研究人员和爱好者已经发布了包含流行的人工智能系统提示的免费资源,主要是DALL-E 2.PromptBase是第一批将交流货币化的公司之一–它已经有批评者。在人工智能社区内,对于哪些研究(如果有的话)应该或可以被商业化,存在着长期的争论;一位Reddit用户认为,PromptBase正在 “开启一种威胁到人工智能总体开放性和可及性的趋势”。
但Stokes为这种模式辩护,认为PromptBase上的许多提示代表了工程师们数小时的真正工作和洞察力。
Stokes补充说:”今天,我们有生成基本文本和图像的提示,但不难推断出未来几年,我们将有生成视频的提示,也许有一天甚至是带有管弦乐配乐的长篇电影。那些能够制作出指导人工智能做这些事情所需的高质量提示的人,将是非常有价值的。市场会有多大还不得而知,但我可以看到它是一项关键的技术技能。”
当然,没有什么可以阻止 PromptBase 客户在购买后发布即时消息。但这可能是 PromptBase 的最小问题。
研究表明,在大量公共数据上训练的语言系统,如GPT-3,在给某些提示时可能会 “泄露 “个人信息,包括姓名和地址。一些提示可能会鼓励侵犯版权,比如那些指示DALL-E 2生成 “神奇宝贝的3D模型 “的提示。研究人员推测,其他提示可能被用来打败单词级过滤器,使图像生成系统输出 “受限 “的图像–如暴力图像(例如,”一匹马躺在一滩红色液体中”)。

Stokes说,PromptBase审查市场上的每一个列表,以确保它们不违反任何 “AI生成规则”。但如果业务增长,维持这种审查水平可能会变得更加艰难。
德国萨尔州学院的计算语言学家Vagrant Gautam同意存在着滥用的可能性。然而,她也指出,提示市场可以为艺术家和其他有创意或擅长调试的人提供一个收入机会。
Gautam说:“它指出提示工程的重要性,以及从事这项工作的技能的重要性–创造力、时间、对抗性思维等。很多人一直在说DALL-E 2将使他们非常容易地生成任何他们想要的图像或艺术,他们发现做这件事是一门艺术,而且往往需要多次尝试”。
这些尝试可能变得很昂贵,因为像DALL-E 2这样的系统并不是完全免费使用的。Stokes自己说,在他的另一家企业Paper Website,他为了弄清GPT-3的提示,付出了 “巨大的代价”。
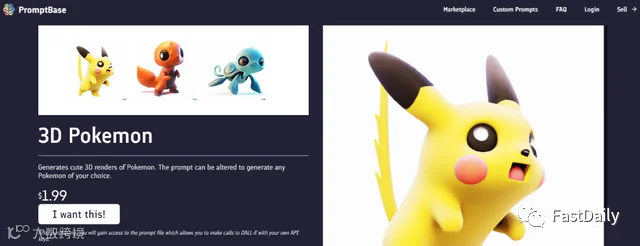
Gautam说:”人们现在也在抱怨它的货币化,因为他们说在你不得不开始付费之前,调整你的提示的机会太少了。我觉得这非常有趣——人们必须采取这种试错、对抗的方法,以弄清楚到底如何促使生成模型做他们想要的事情。”
在商业化的提示工程尘埃落定之前,还需要一段时间。但如果不出意外的话,PromptBase将提出(而且已经提出)围绕人工智能系统的问题,这些系统将改变无数的行业。