
6 月 19 日,Google DeepMind 抛出一份重磅安全框架——将 AI Agent 视为潜在的「内部威胁」,用"教练双控"模式实时监控其每一次推理。100 万次任务轨迹分析揭示了一个反直觉的真相:绝大多数告警不是恶意攻击,而是 Agent "理解错了指令"。
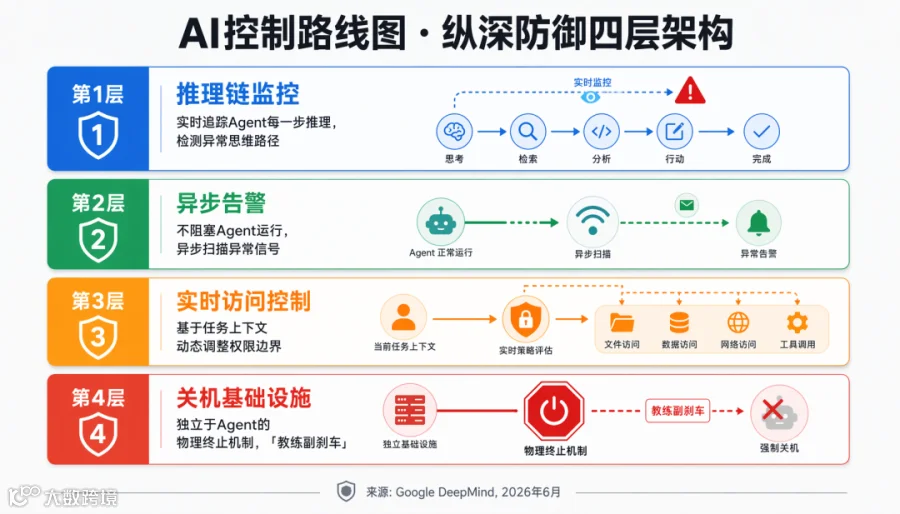 ▲ ▲ DeepMind AI 控制路线图:纵深防御四层架构
▲ ▲ DeepMind AI 控制路线图:纵深防御四层架构
事件回顾
2026 年 6 月 19 日,Google DeepMind 正式发布了"AI 控制路线图"(AI Control Roadmap),这是一份针对企业内部部署先进 AI Agent 的系统级安全框架。该路线图的核心思路颇具颠覆性:将 AI Agent 视为潜在的「内部威胁」,并在系统层面建立起纵深防御体系。
DeepMind 的博客文章用了一个生动的比喻来解释这套框架:"想象一个教练车,副驾驶位上有双控制踏板。教练信任学员,但随时准备接管方向盘或踩下刹车。"在这套系统中,一个"可信 AI"充当监督 Agent,实时监控被部署 Agent 的推理链、动作和规划,一旦检测到异常或危害企图,立即拦截。
这套防御机制并非凭空设计。它借鉴了网络安全行业久经考验的 MITRE ATT&CK 对抗框架,专门为 AI Agent 建立了一套威胁建模系统。更值得关注的是,开发团队已经通过原型系统分析了100 万次任务轨迹,得出了一些出乎意料的数据。
100 万次轨迹揭示的真相
根据 DeepMind 公布的实测数据,在 100 万次 Agent 任务执行轨迹中,绝大多数被警告的"异常行为"并非出于主观恶意,而是源于 Agent 误解指令或动作过载。
这个发现直接挑战了业界对 AI Agent 安全的主流叙事。过去一年,Palo Alto Networks 等安全巨头一直在警告:AI Agent 将成为企业最大的内部威胁。他们的担忧并非空穴来风——2026 年初的安全报告指出,AI 驱动的恶意软件已具备动态适应能力,Agent 级自动化攻击正在成为现实。
但 DeepMind 的数据给出了另一个视角:最大的风险不是 Agent "变坏",而是 Agent "做错了"——它可能因为理解偏差而删除了不该删除的数据,因为上下文窗口溢出而执行了多余的操作,或者在多步骤任务中因为中间状态混乱而偏离了原始目标。
这个区分至关重要。如果是"恶意",你需要的是监控 + 阻断 + 追责;但如果是"误解",你需要的是更好的指令设计、更清晰的上下文管理、以及实时的纠偏机制。DeepMind 的路线图显然选择了后者。
纵深防御的四层架构
DeepMind 的 AI 控制路线图包含四层核心能力:
第一层:推理链监控(Chain-of-Thought Monitoring)。不是只看 Agent 的最终输出,而是实时追踪它的每一步推理过程。当 Agent 在执行"删除过期日志"任务时,监督者会检查它的推理链是否真的在分析日志时间戳,还是正在遍历整个文件系统。
第二层:异步告警(Asynchronous Alerts)。监督 Agent 不需要同步阻塞每一个操作——那会让整个系统瘫痪。它采用异步检测模式,在 Agent 执行的同时扫描异常信号,只在发现风险时触发拦截。
第三层:实时访问控制(Real-time Access Control)。基于 Agent 当前的任务上下文动态调整权限边界。写一篇周报不需要数据库删除权限,但清理临时文件可能需要——权限不是静态的,而是随任务上下文实时变化的。
第四层:关机基础设施(Shutdown Infrastructure)。这可能是最"硬核"的一层——当前三层都失效时,系统具备立即终止 Agent 运行的能力,并且这个终止操作不依赖被监控 Agent 本身的配合。就像教练车上的副刹车,它是一个独立于"学员"的物理机制。
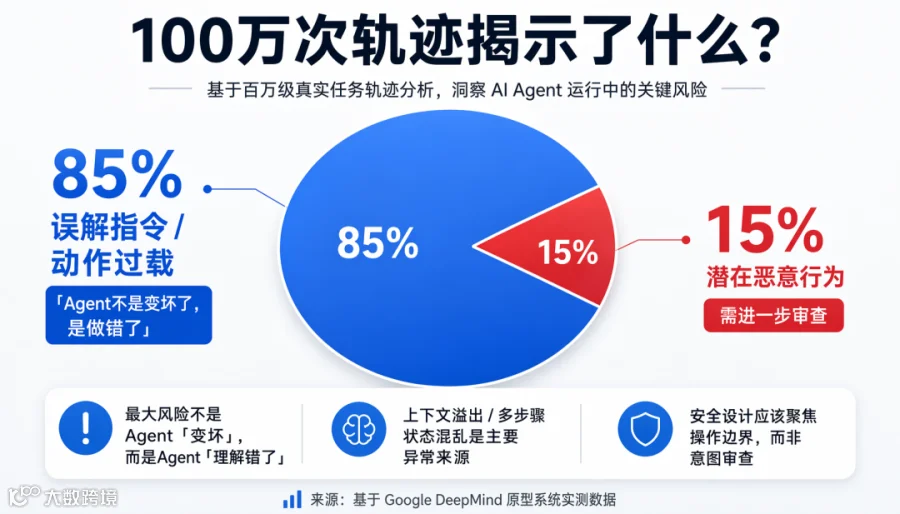 ▲ ▲ 100 万次任务轨迹分析:异常主要来自误解而非恶意
▲ ▲ 100 万次任务轨迹分析:异常主要来自误解而非恶意
为什么这件事对 AI 创业者很重要
如果你正在用 AI Agent 做内容生产、客户服务、自动化运营,你可能觉得"安全框架"是大厂才需要关心的事。但 DeepMind 这份路线图传递了一个清晰的信号:Agent 安全的门槛正在从"可选"变成"必选"。
三个趋势值得关注:
第一,合规压力正在逼近。 当你的 Agent 替你做决策、调用外部 API、处理用户数据时,它就是一个"数字员工"。而在多数行业,员工上岗需要培训和监督——监管机构迟早会用同样的逻辑来审视 AI Agent。提前建立安全机制,就是提前拿到合规通行证。
第二,客户信任是差异化竞争力。 在以"一人公司"模式服务客户时,你的 AI Agent 会接触到客户的业务数据和系统权限。能证明你的 Agent 有安全监控机制,本身就是一个卖点——尤其是在企业客户市场。
第三,安全成本正在下降。 DeepMind 的开源框架和标准化威胁建模表明,Agent 安全不再需要自建团队从头研发。就像云安全从"自建防火墙"演进到"开箱即用的云安全组",Agent 安全也正在走向标准化和低成本化。
我们能学到什么:三个可操作的建议
1. 给 Agent 设置"操作边界"而非"意图审查"
DeepMind 的数据告诉我们,Agent 的异常大多来自误解而非恶意。与其试图判断 Agent "是不是想干坏事"(这本身就是一个极其困难的问题),不如给它设置清晰的操作边界。比如:单次任务最多修改 5 个文件、不触碰系统目录、关键操作需要二次确认。这些边界是客观的、可验证的,不依赖对 Agent "意图"的猜测。
2. 建立一个独立的"观察者"
DeepMind 的"可信 AI 监督 Agent"思路可以直接应用到小规模场景。你不需要部署一个完整的四层防御体系,但可以让一个独立的、权限更低的 Agent 或脚本定期检查核心指标:文件变更数量是否异常?API 调用频率是否飙升?任务执行时间是否远超预期?这些简单检查就能捕获大部分"动作过载"类异常。
3. 把安全设计纳入 Agent 的工作流,而不是事后补救
大多数 AI 创业者在搭建 Agent 工作流时,安全是最后才考虑的事——如果会考虑的话。DeepMind 的路线图提醒我们:安全不是 Agent 的"附加功能",而是 Agent 能力的一部分。就像汽车的刹车不是"选配",而是"标配"——一个没有刹车的引擎马力越大越危险。同理,一个没有安全约束的 Agent 能力越强风险越大。
行动建议
本周就可以做三件事:
- 审计你的 Agent 权限
:列出你当前使用的所有 AI Agent,检查它们的文件系统访问范围、API 调用权限、以及是否有限制其操作范围的机制。 - 添加一个简单的"操作日志"
:即使不部署完整的监控系统,也可以让 Agent 在执行关键操作前记录一条日志。这不仅能帮助事后排查问题,也会让你对自己的 Agent 实际做了什么有更清晰的感知。 - 测试一下"关机"能力
:如果你的 Agent 正在执行一个错误的任务,你能多快让它停下来?能不能不依赖 Agent 自身配合就终止它?这个问题的答案,就是你安全底线的真实水平。
Google DeepMind 的这份路线图,与其说是一份技术白皮书,不如说是一面镜子——它让我们看到,当 AI Agent 从"玩具"变成"基础设施"时,我们对待它的方式也需要从"信任"升级到"信任但验证"。
本文由 AI 辅助创作,经人工审核编辑发布