
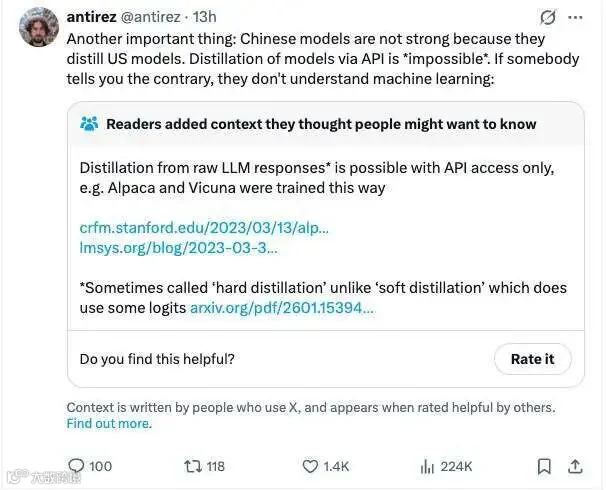
2026 年 6 月 15 日,Redis 之父 Salvatore Sanfilippo(antirez)在 X 平台发表了一系列激烈言辞,直指当前 AI 圈关于“中国模型通过 API 蒸馏美国模型”的论调。
他明确表示:“中国模型的强大绝非源于对美国模型的‘蒸馏’。通过 API 进行模型蒸馏在技术上是不可能的。持相反观点者,显然缺乏对机器学习的基本认知。”
这一言论迅速引发热议,将关于技术来源的争论推向新高。背景在于,过去一年间,"DeepSeek、Qwen 等中国模型进步神速是靠套取美国顶级模型回答进行训练”的说法在美国 AI 圈甚嚣尘上。而在 antirez 发声前几日,Anthropic 暂停了部分前沿模型对海外用户的访问,进一步加剧了关于“模型蒸馏”的敏感情绪。
面对争议,这位德高望重的意大利技术专家选择公开澄清事实,驳斥谬误。
Redis 之父的“不可能三角”
antirez 通过长篇推文系统反驳了"API 蒸馏论”,其核心逻辑可归纳为三点:
首先,数据维度缺失。真正的模型蒸馏需要海量带有完整 logits(包括思维链中间输出)的请求数据。而公开 API 仅返回最终文本结果,如同只看到答案却妄想反推完整的推导过程,这在信息量上是匮乏的。
其次,数学逻辑不成立。他比喻道,试图仅凭复杂曲面上的几个离散点来复原整个曲面,在数学上纯属科幻。
最后,信息路径不明。预训练依赖数万亿 token,强化学习(RL)需要探索过程中的奖励信号,而自 o1 模型起,完整的 logits 分布已不再对外提供。若 lacking 这些关键要素,“蒸馏”的信息通道究竟何在?
针对 DeepSeek,antirez 指出其已公开预训练、SFT 及 RL 管线的详细方法,且社区已成功复现部分成果。既然有公开方法论和可验证结果,为何业界仍倾向于相信“抄袭论”而非承认其真实的工程能力?
以下是 antirez 推文的核心观点梳理:
第一,真正的蒸馏需访问海量带完整 logits 的请求,包括思维链全过程。目前 API 输出的思维链多为总结版,无法获取完整过程。
第二,仅凭 API 调用复原模型,如同通过曲面上少数点重建复杂曲面,数学上不可行。
第三,DeepSeek R1 论文中的蒸馏确实提升了目标模型能力,但前提是目标模型已在海量 token 上完成预训练,仅缺“思考”训练。即便经过蒸馏,其能力上限也受限于基座模型。
第四,API 数据仅能为强化学习提供有限的高质量信号,非决定性因素。构建有效的 RL 流程才是工程能力的核心。
第五,即便拥有模型权重,蒸馏依然困难重重。众多中国前沿模型已开源,但包括欧洲在内的多个实验室仍难以复现对齐效果。
第六,DeepSeek 已公开预训练、SFT 和 RL 管线细节并被复现。业界应尊重可验证的工程成果,而非盲从无据猜测。
第七,若坚持“蒸馏论”,请明确指出信息路径:预训练需数万亿 token,RL 需奖励信号,完整 logits 已不再开放。所谓的“信息通道”究竟存在于何处?
antirez 最后总结道:“停止传播此类谬误。即便自称'AI 专家’,若不懂机器学习基本原理,便是在误导公众。”
然而,这一表态使 antirez 自身陷入舆论漩涡。评论区出现大量质疑声,甚至有网友讽刺其违反推特“政治正确”,或质问其是否收受利益。
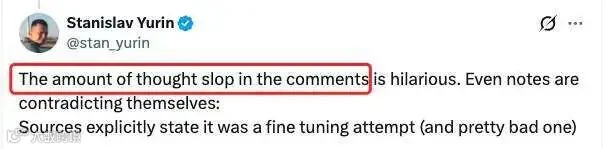
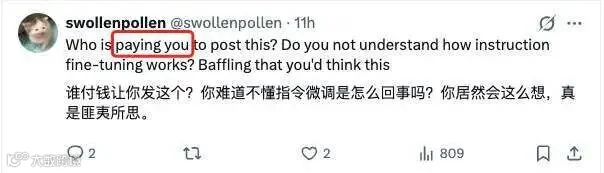
部分反对者以 Alpaca 和 Vicuna 为例,认为通过 API 收集指令数据进行微调即为蒸馏。事实上,这属于“黑盒蒸馏”或“基于模型输出的训练”,无需 logits 即可实现。而 antirez 所指的“蒸馏”是经典的“白盒蒸馏”,即需要教师模型的完整概率分布。在此严格定义下,仅靠 API 确实无法实现。
“蒸馏”概念的武器化
另有观点引用 Anthropic 报告,指控 DeepSeek 等实验室通过大规模查询窃取数据。然而该报告逻辑存在明显漏洞:普通 AI 产品日均交互量即可达十余万次,技术评测(如 SWE-bench)更会产生百万级调用。将正常业务与评测流量定性为“蒸馏攻击”,显然缺乏说服力。

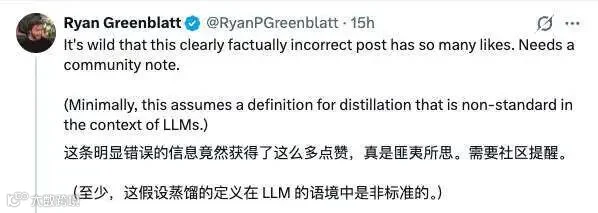
对此,Redwood Research 首席科学家 Ryan Greenblatt 指出 antirez 对“蒸馏”的定义过于狭隘,认为少量轨迹即可蒸馏 RL 策略。但他同时也承认,这并不直接证明 DeepSeek 的能力源自窃取。
AI2 研究员 Nathan Lambert 则提出更深层的见解:业界正刻意将“蒸馏”一词武器化。原本中性的技术术语被加上了“攻击”二字,营造出类似“私酒酿造”的道德污名,旨在维护既得利益者的竞争优势。


Nathan 指出,若将在其他模型输出上训练称为“蒸馏”,那么 Cursor 对 Kimi 的微调乃至多数人类辅助创作均需被问责。他主张使用“基于模型输出的训练”等中性词汇,避免商业利益裹挟道德框架。
工程师文化:中国 AI 崛起的核心
在这场争论爆发前夕,Linux Foundation AI & Data CTO Matt White 与 Nathan Lambert 曾实地考察中国 AI 实验室。两人的观察高度一致:中国 AI 生态并非依靠“抄作业”生存,而是凭借扎实的工程师文化崛起。
Matt White 描述,中国 AI 团队普遍年轻精简,研究员平均年龄约 25 岁。他们不热衷个人包装,专注于模型性能提升。开源已成为默认选项,DeepSeek 更是因 GRPO 算法及推理训练的创新而赢得全行业尊重。
Nathan Lambert 亦表示,中国 LLM 社区更像协作生态系统而非零和博弈的部落。DeepSeek 展现出的研究品味与执行力令人印象深刻。当前大模型的构建日益依赖全栈优化:从数据清洗、架构细节到 RL 算法实现及推理系统,每个环节的精细化工程都可能带来突破。
中国实验室的快速追赶,并非依赖神秘捷径,而是源于团队在密集、复杂且非光鲜的工程优化上的卓越能力。这也解释了为何"API 蒸馏论”站不住脚。
值得一提的是,antirez 不仅是理论辩手,更是实践者。他近期开源了 DS4 项目,专为 DeepSeek V4 Flash 优化的本地推理引擎,深入解决了 MoE 架构、长上下文、KV Cache 及量化等底层难题。作为系统程序员,他深知模型背后真实的工程含量,绝非单纯的数据堆砌。
综上所述,这场争论的实质超越了技术定义的分歧,折射出舆论场中对“中国进步”的刻板预设。将中国在算力受限下的架构创新与算法突破简单归因为“抄袭”,既无视了事实,也低估了中国工程师文化的真正力量。
参考链接:
https://x.com/antirez/status/2066516853497684342
https://www.interconnects.ai/p/notes-from-inside-chinas-ai-labs
https://huggingface.co/blog/matthew-d-white/ai-in-china
声明:本文为 InfoQ 整理,不代表平台观点,未经许可禁止转载。

