
AI 新潮流:流式音视频模型“缅因猫”问世
全球流式音视频模型赛道迎来重大突破,一款名为缅因猫(MaineCoon)的 SOTA 级模型正式亮相。该模型由来自中国的初创团队 Catnip(猫薄荷)研发,其核心特性在于能够像粘人的宠物一样,实时跟随用户状态进行连续互动,实现真正的“边生成边播放”与“音画同出”。
MaineCoon 不仅支持长达 30 分钟以上的连续生成,更在推理速度与成本控制上创下行业纪录。在单张 H100 显卡上,22B 参数量的模型可跑出 47.5 FPS 的帧率,位居同赛道第一;即便在成本较低的 RTX Pro 6000 上,也能稳定保持 30 FPS 以上的实时运行速度。其推理成本极低,满负载状态下每秒仅需 0.00025 美元,大幅降低了应用门槛。

该技术报告发布后迅速引发关注,连 LTX 官方也主动寻求合作。以下将从效果表现、技术架构及团队背景三个维度深入解析。
效果展示:重新定义社交交互“活人感”
与侧重物理规律模拟的通用音视频模型不同,MaineCoon 专注于社交交互场景,致力于解决人物细节不自然、音画不同步等痛点,打造极致的“活人感”。
亚秒级音视频流式生成
流式生成要求模型在推理过程中实时输出内容。MaineCoon 将生成单元压缩至亚秒级,指令发出后 1 秒内即可呈现首帧,并支持在生成过程中无缝接入新指令。无论是调整角色语气、切换表情,还是进行实时问答,模型均能流畅响应,提供如同真人视频对话般的交互体验。
业界领先的推理速度
实测数据显示,MaineCoon 的生成速度是同类流式模型的 7 倍。即便在持续生成一整天的情况下,其单卡部署能力仍能维持高帧率输出。这种高速推理并未牺牲质量,反而在情感表达丰富度与动作连贯性上表现优异,能够细腻还原光影变化与微表情。
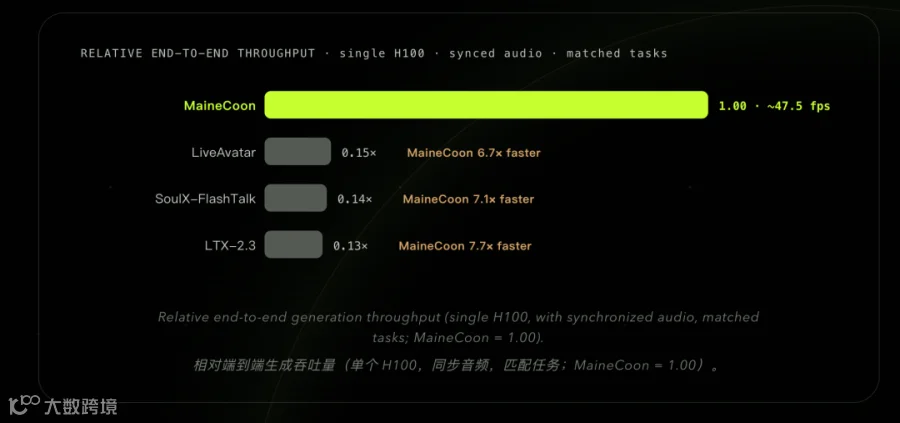
无限时长与高一致性
MaineCoon 实现了连续 10 分钟以上的音视频生成,且全程保持画质清晰、人物一致及音画同步。官方自建的首个社交短视频基准测试SocialVideo Bench显示,该模型在密集演讲、双人互动、情绪表演等七大场景中,综合得分 0.934,超越 SoulX-FlashTalk 等主流模型,刷新 SOTA 纪录。
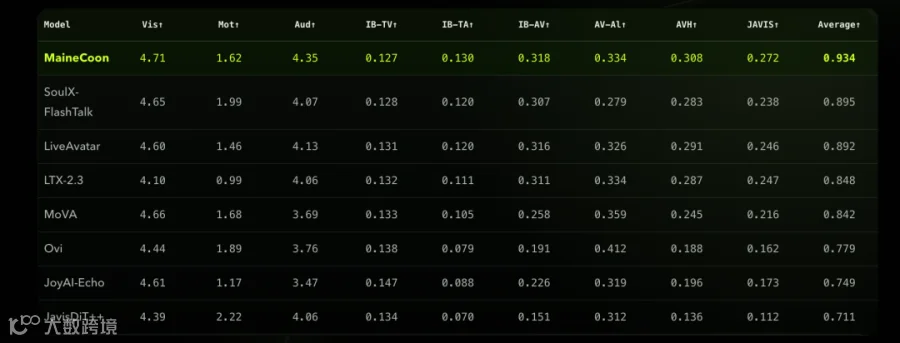
技术揭秘:三层训练与 Agentic 推理框架
MaineCoon 的卓越性能源于其创新的训练策略与工程架构。
三阶段训练框架
第一步:自重采样(Self-Resampling)。通过在训练中引入降质版历史帧,消除推训偏差,确保模型在长序列生成中保持稳定。
第二步:流式表征对齐。利用冻结的 V-JEPA 2 视觉编码器进行蒸馏监督,加速跨模态语义结构的学习,提升训练效率。
第三步:域感知偏好优化(DPO)+ 强化在线策略蒸馏(ROPD)。针对舞蹈、对话等不同场景训练偏好专家模型,并通过强化蒸馏整合为轻量化的流式策略。
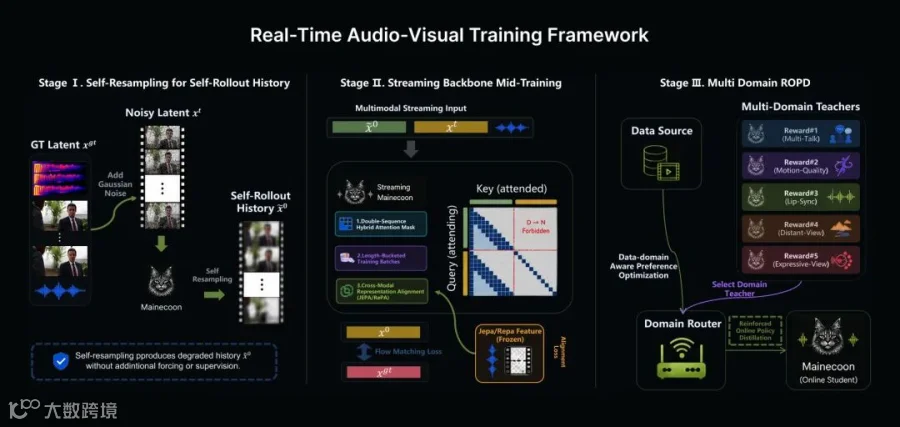
在基础设施方面,团队通过参数分摊、序列并行及预计算存储等工程优化,仅用 10k GPU 小时和不到 100 万条数据便完成了 22B 模型的训练。
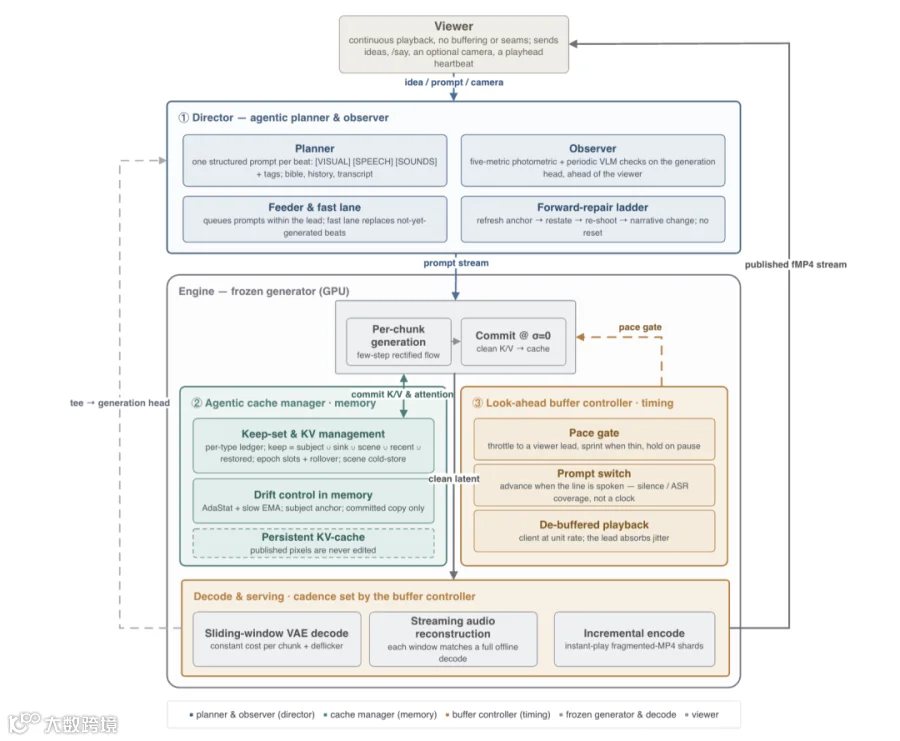
Agentic 推理框架
推理端采用了由Director、Cache Manager和Buffer Controller构成的智能控制系统:
- Director(导演):负责叙事规划与实时纠错,通过前向修复机制遏制长视频生成中的畸变问题。
- Cache Manager(缓存管理器):管理 KV 缓存,保留关键记忆锚点并定期修正全局外观漂移。
- Buffer Controller(缓冲控制器):平衡生成速度与播放节奏,确保交互指令的低延迟响应。
未来愿景:构建社交世界模型
Catnip 团队将 MaineCoon 定位为“社交世界模型”的渲染层突破。与传统模拟物理世界的模型不同,社交世界模型以人为中心,旨在实现感知用户情绪、预测社交行为并实时生成反馈的闭环。
下一步,团队计划摆脱半双工交互模式,实现人类式的连续、多模态双向实时互动,并将该技术落地为可交互的内容平台。

Catnip 是一支低调而高效的团队,成立大半年未曾公开露面,却已获得红杉、明势等头部机构投资。创始人杨姝瑞拥有 TikTok 及 PixVerse 产品经验,首席科学家谢泽柯教授则在百度研究院及顶级 AI 会议中有深厚积累。团队采用"AI Native"研发模式,仅用 2 个月便完成了从训练到全栈交付的过程。
MaineCoon 的出现标志着生成式 AI 正从被动工具转向主动社交参与者,下一代社交平台的底层引擎已然启动。
相关资源链接:
论文链接:https://arxiv.org/abs/2606.17800
官网链接:https://mainecoon.tech/
模型 Blog:https://mainecoon.tech/blogs