
whichllm 简介
whichllm[1] 是一款专为本地运行大语言模型(LLM)设计的智能推荐工具。它能自动检测你的 CPU、GPU 和内存配置,结合 HuggingFace 上的最新模型数据与多维度真实评测基准,为你精准推荐“不仅装得下、而且跑得快、效果好”的最佳本地模型,而非简单地选择体积最大的可运行模型。
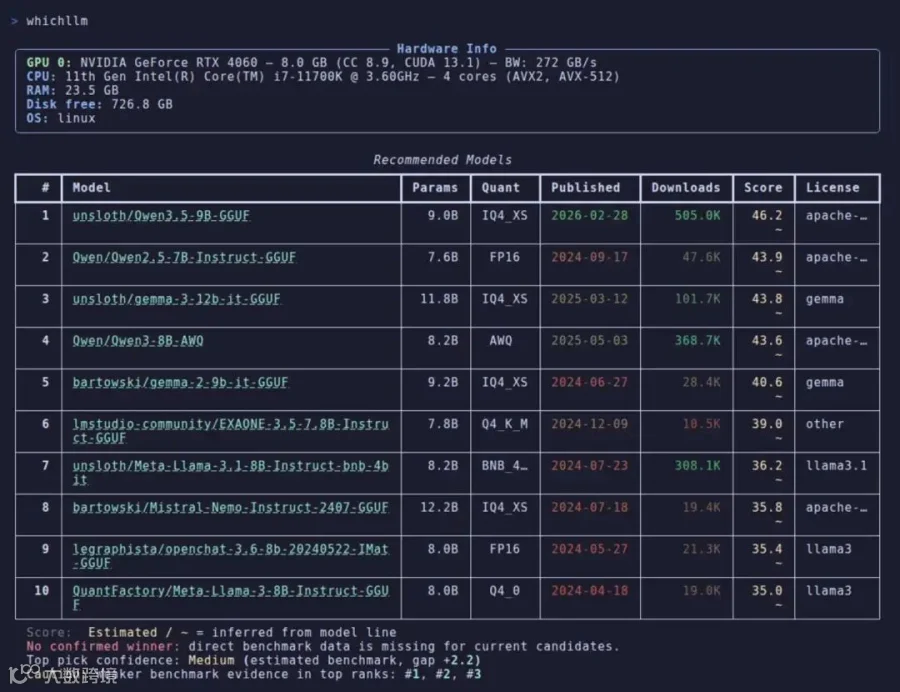
项目采用模块化架构,核心由 硬件检测层、模型与评测数据管道、资源估算与兼容性引擎 和 智能排序系统 组成。通过整合 LiveBench、Artificial Analysis、Chatbot Arena 等权威评测数据,并结合量化精度、显存占用、推理速度、模型代际等因子进行加权评分,确保推荐结果既科学又实用。同时支持 GPU 模拟、硬件规划、一键聊天和代码生成等高级功能。
项目特点
核心特性
-
智能硬件感知:自动识别 NVIDIA、AMD、Apple Silicon 或纯 CPU 环境,精确估算可用 VRAM 与计算能力。 -
证据驱动的模型评分:融合多个权威评测基准(如 LiveBench、Arena ELO),拒绝仅凭模型大小或上传者自述打分。 -
动态实时数据:直接从 HuggingFace API 获取最新模型信息,缓存机制兼顾性能与新鲜度。 -
一键启动聊天: whichllm run自动下载模型、配置环境并开启交互式对话,无需手动安装依赖。 -
生成即用代码: whichllm snippet输出可直接复制粘贴的 Python 推理代码,支持 GGUF/AWQ/GPTQ 等多种格式。 -
GPU 模拟与硬件规划:通过 --gpu模拟目标显卡,或使用plan命令反向查询运行某模型所需的最低硬件配置。 -
脚本友好输出:支持 --json输出,便于集成到自动化流程或与其他工具(如 Ollama)联动。 -
任务场景过滤:按通用、编程、视觉、数学等任务类型筛选最优模型。
使用场景
-
个人开发者选型:快速找到在自己笔记本或台式机上表现最佳的开源 LLM,避免盲目尝试。 -
硬件升级决策:在购买新显卡前,模拟不同 GPU 下的模型推荐结果,评估性价比。 -
AI 应用原型开发:通过 snippet功能快速获取推理代码,加速本地 LLM 集成到项目中。 -
教育或演示用途:一键启动高质量本地模型进行教学或技术分享,无需复杂部署。 -
自动化模型调度:在 CI/CD 或批处理脚本中调用 JSON 输出,动态选择最适合当前机器的模型。
项目使用
-
编程语言版本:Python 3.11 或更高版本 -
操作系统要求:Linux、macOS、Windows(支持主流平台) -
依赖的框架或工具: -
自动依赖管理(通过 uv或pip安装时自动处理) -
GPU 支持:NVIDIA(需 nvidia-ml-py)、AMD(Linux 下 ROCm)、Apple Silicon(Metal) -
其他必要的配置:建议具备网络访问权限以获取 HuggingFace 模型数据(离线时使用缓存)
安装步骤
-
推荐方式(使用 uv 工具):
# 一次性运行(无需安装)
uvx whichllm@latest
# 安装为全局工具
uv tool install whichllm
-
Homebrew 安装(macOS/Linux):
brew install andyyyy64/whichllm/whichllm
-
传统 pip 安装:
pip install whichllm
-
更新已安装版本:
uv tool upgrade whichllm # 若通过 uv 安装
pip install --upgrade whichllm # 若通过 pip 安装
代码示例
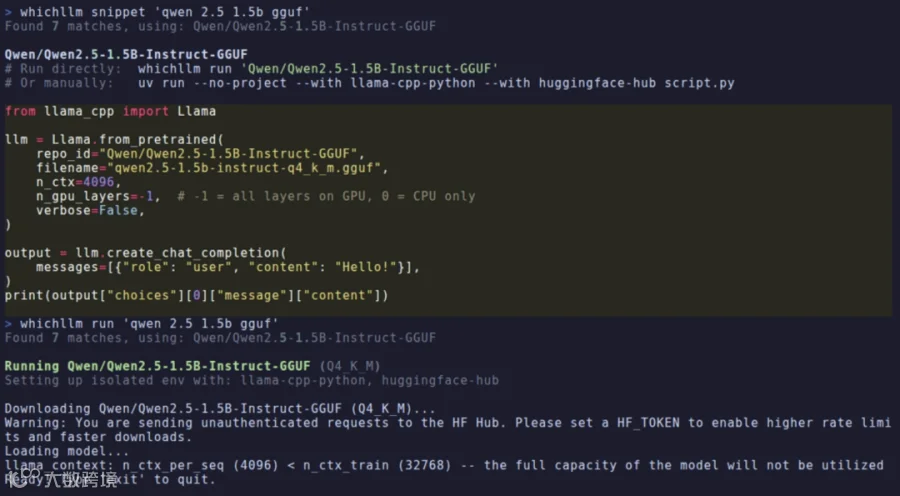
场景一:获取指定模型的 Python 推理代码
whichllm snippet "qwen 7b"
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="Qwen/Qwen2.5-7B-Instruct-GGUF",
filename="qwen2.5-7b-instruct-q4_k_m.gguf",
n_ctx=4096,
n_gpu_layers=-1,
verbose=False,
)
output = llm.create_chat_completion(
messages=[{"role": "user", "content": "Hello!"}],
)
print(output["choices"][0]["message"]["content"])
此代码可直接运行,自动加载适配你硬件的 GGUF 量化版本。
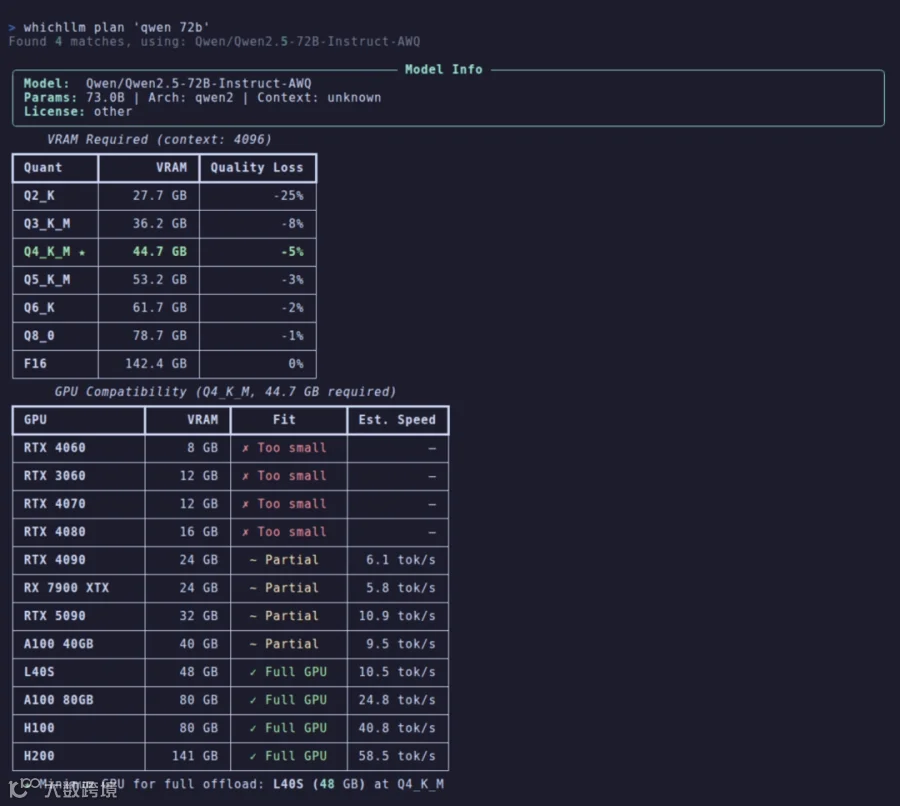
场景二:模拟高端显卡并查看推荐
whichllm --gpu "RTX 4090"
输出将显示在 RTX 4090(24GB VRAM)上综合评分最高的几个模型,包含速度、量化格式和得分依据。
场景三:一键启动本地聊天
whichllm run
自动选择当前机器上最优模型,下载后立即进入交互式聊天界面。
相关资源
-
CLI 命令参考[2] -
工作原理详解[3] -
评分机制说明[4] -
演示动画: -
demo.gif[5] -
run demo[6]
注:本文内容仅供参考,具体项目特性请参照官方 GitHub 页面的最新说明。
欢迎关注&点赞&在看,感谢你的阅读~
GitHub仓库: https://github.com/Andyyyy64/whichllm
[2]CLI 命令参考: https://github.com/Andyyyy64/whichllm/blob/main/docs/cli.md
[3]工作原理详解: https://github.com/Andyyyy64/whichllm/blob/main/docs/how-it-works.md
[4]评分机制说明: https://github.com/Andyyyy64/whichllm/blob/main/docs/scoring.md
[5]demo.gif: https://github.com/Andyyyy64/whichllm/blob/main/assets/demo.gif
[6]run demo: https://github.com/Andyyyy64/whichllm/blob/main/assets/demo-run.gif