
阿里通义翻译智能体:实现图文与文档排版一致的精准翻译
中英互译已不再是难题,但翻译后保持原文排版不变仍具挑战。即便使用大模型,传统翻译方式往往只能输出纯文本,无法还原原始布局,影响阅读与使用体验。

输入一张图片,输出仅为文字内容,缺乏直观性与实用性。
阿里通义推出的翻译智能体有效解决了这一问题,能够实现图像与文档翻译前后排版高度一致,尤其适用于含多文本框的复杂结构。
图片翻译操作步骤
访问通义官网,点击页面中的「翻译」功能进入操作界面。
系统可自动识别源语言,目标语言默认为中文,无需手动调整。
将需要翻译的图片拖入聊天框,点击发送即可生成排版一致的译文图片。
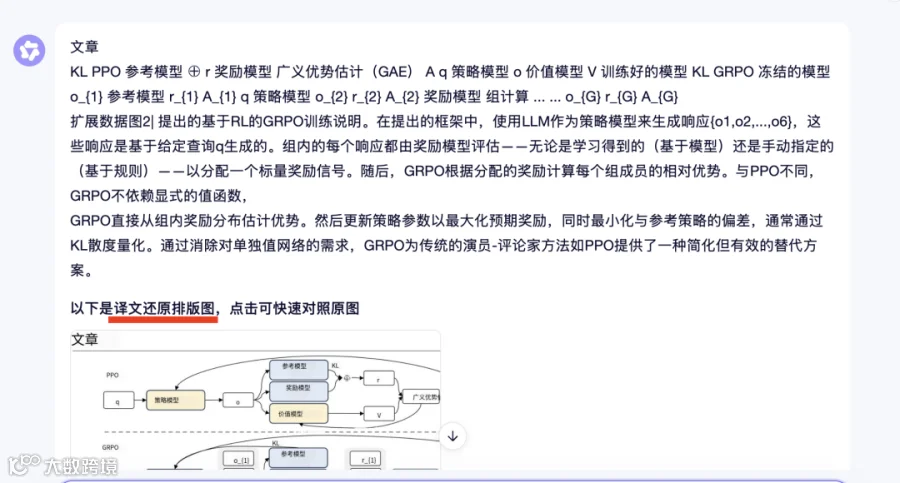
点击查看生成的翻译图,可见原文与译文在布局、字体位置等方面完全对齐。
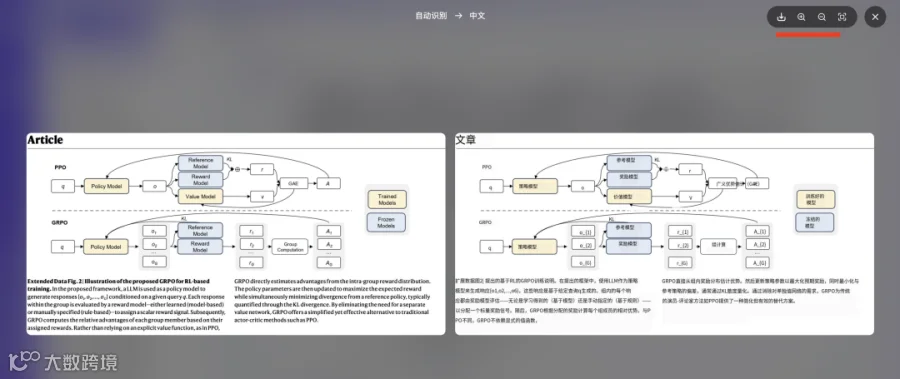
对比展示如下:
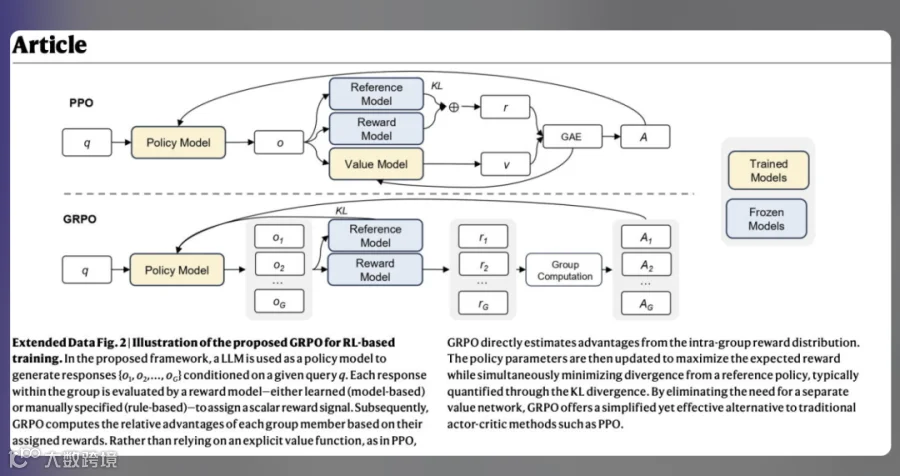
翻译后:
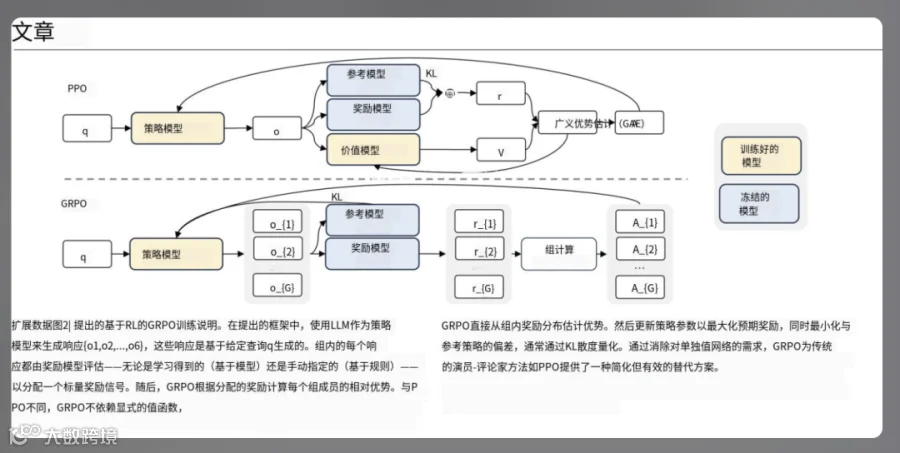
不仅翻译准确,排版还原度高,实用性显著提升。
文档翻译功能演示
通义翻译智能体同样支持PDF等文档格式的翻译,并保持整体排版一致。
上传一份35页的英文PDF文件:
文档第一页内容如下:

系统在2-3分钟内完成全文翻译,点击「还原排版」后,第一页译文效果如下:

译文在字体、段落、标题位置等方面均与原文高度匹配,视觉一致性极佳。
排版还原技术原理
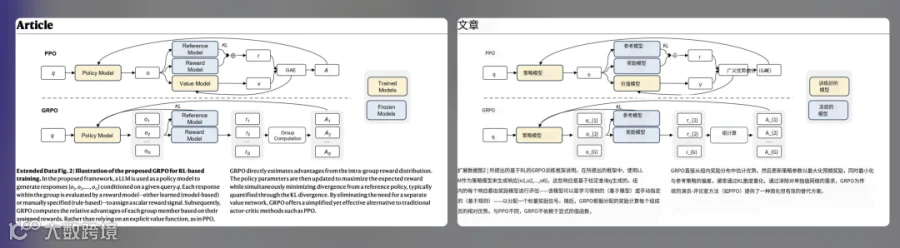
PDF文档可视为由多个“文字盒子”组成的画板,每个标题、段落均为具有坐标、大小和字体信息的矩形区域(bbox)。
通过Python库(如PyMuPDF)可提取每个文本块的位置与内容,进行分段翻译后,再按原格式回填至对应位置。示例代码如下:
import fitzdoc = fitz.open("input.pdf")for page in doc:blocks = page.get_text("blocks")for b in blocks:rect = fitz.Rect(b[:4])src_text = b[4]tgt_text = translate(src_text) # 你的翻译函数page.insert_textbox(rect, tgt_text,fontname="helv", fontsize=12,color=(0,0,0), align=0)doc.save("translated.pdf")
翻译前后文本长度差异是排版主要难点。系统通过自动换行、微调字号或字间距,确保译文恰好填充原文字框,避免溢出或空白。
该技术虽原理清晰,但实现精准需大量优化与调试。
总结
阿里通义翻译智能体在图文与多页PDF翻译中表现出色,不仅能准确翻译内容,更能保持原文排版结构高度一致,极大提升翻译成果的可用性与专业性。
其核心技术在于将文档分解为可定位的文字区块,逐块翻译后精确还原,结合智能排版调整策略,实现高质量输出。对于有图文本地化、跨境文档处理需求的用户,具备较高应用价值。