
Arena.ai Code Arena 前端编程榜单刚刚变天:GLM-5.2(Max)排名第 2,比 Claude Opus 4.7(Thinking)高出整整 29 分。更震撼的是排在第 1 的 Fable 5 当前不可用——去掉它,GLM-5.2 就是地球上最好的前端 coding 模型之一。开源模型第一次在这么关键的赛道进入顶级闭源模型的讨论区间,出牌的是智谱。
一张排行榜炸了整个前端圈
6 月 16 日,Arena.ai 在 X 上贴出了 Code Arena: Frontend 的最新排名。GLM-5.2 (Max) 拿了 1595 分,稳坐第 2。
排在它前面的只有 Fable 5。这个模型被社区描述为 Anthropic 的"特殊 harness 集成体"——一个由多个模型组合、在特定评估框架下表现出奇强、但普通开发者根本用不上的存在。在 Arena 发帖的时间点,Fable 5 被标注为 unavailable。
那件事的连锁反应来得极快。Angelopoulos——前 Berkeley/Stanford/Google DeepMind 的模型评估专家、现任 Arena 核心成员——直接发帖把话挑明:
"Just to be clear, if you remove Fable which is unavailable, GLM-5.2 (Max) is the #1 model in the world for frontend coding."
「去掉不可用的 Fable,GLM-5.2 (Max) 就是世界上前端 coding 的第一模型。这是一个巨大时刻,开源模型在这一非常重要的领域追平了专有模型。」
帖子在数小时内拿到近 1400 赞、超 13 万次浏览。
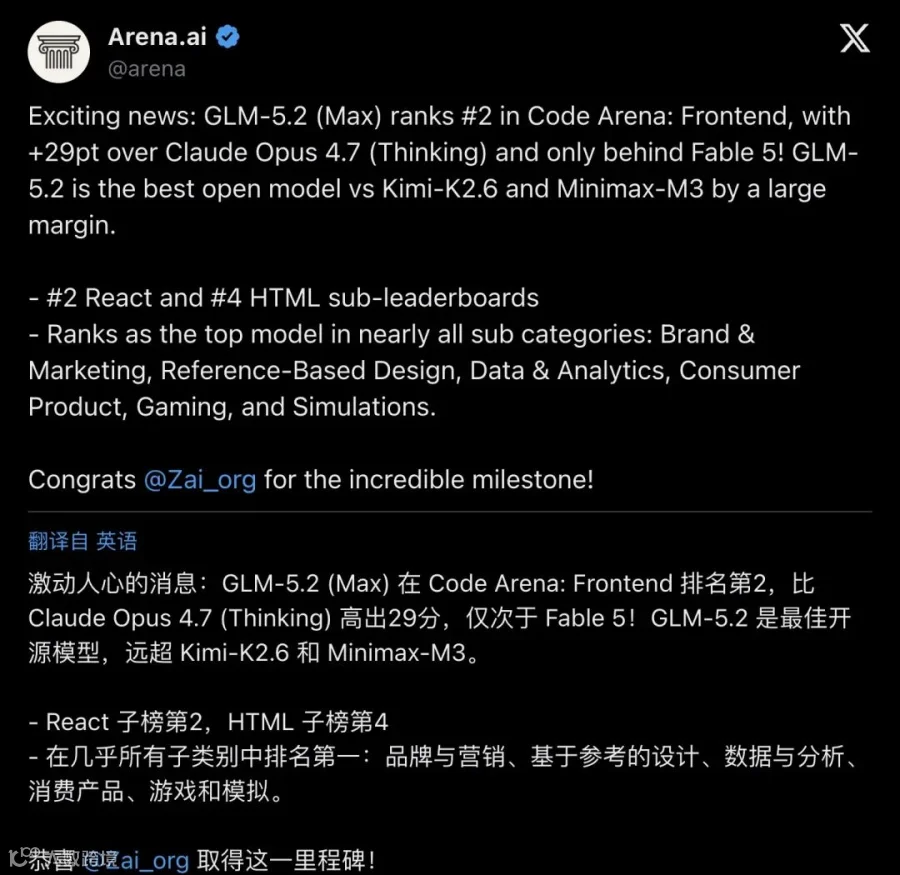
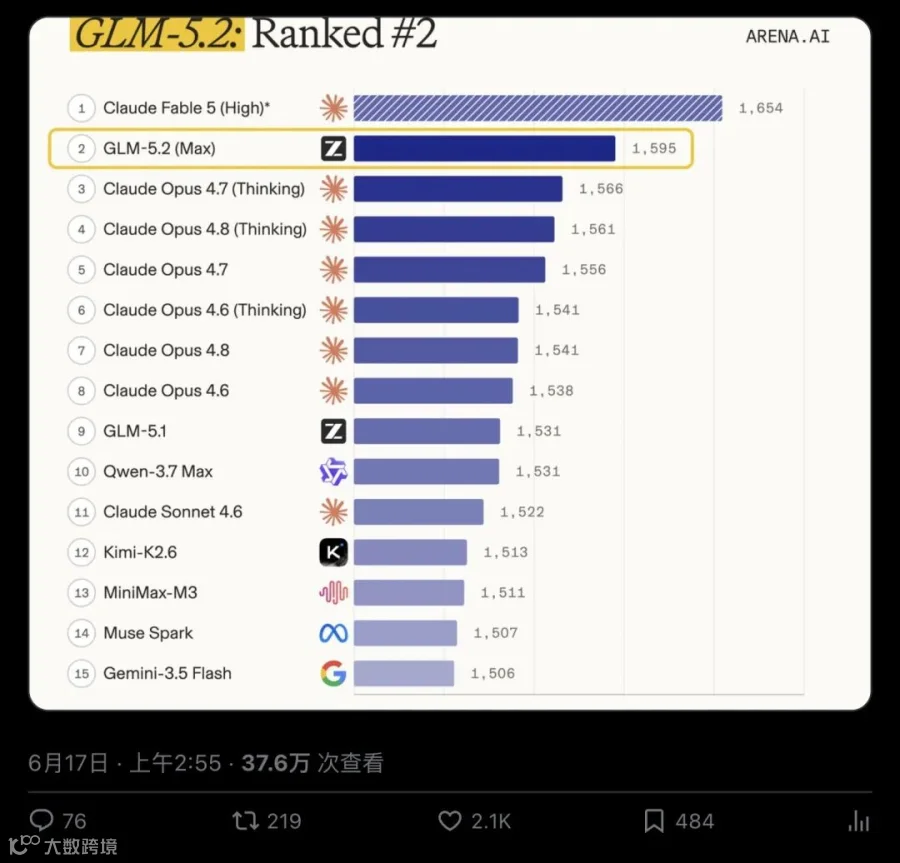
▲ Arena.ai 官方帖文内嵌排行榜截图:GLM-5.2 (Max) #2 位置高亮,领先 Claude Opus 4.7(Thinking)29 分;远超 Kimi-K2.6、Minimax-M3。帖子超 2000 赞、37 万次浏览。
六个子类全部霸榜,差的不只是总名次
总分排第 2 只是故事的一半。真正让竞争对手坐不住的是子类别数据:
GLM-5.2 在品牌与营销(Brand & Marketing)、基于参考的设计(Reference-Based Design)、数据与分析(Data & Analytics)、消费产品(Consumer Product)、游戏(Gaming)和模拟(Simulations)六个子类别中全部排第 1。
React 子榜第 2,HTML 子榜第 4。
注意这里的评估方式——Arena 不是跑几个自动化测试就收工。Code Arena Frontend 让真实用户给出 agentic coding 任务,模型必须从头构建完整的 app 或网页,然后由另一个用户做盲评。这意味着模型碰到的不再是"生成一个 ToDo 列表组件"这种闭卷题,而是"帮我做一个电商落地页,配色参考 Stripe,动画要流畅,手机端也要好看"这种真实设计需求。
"GLM-5.2 is the best open model vs Kimi-K2.6 and Minimax-M3 by a large margin."
「GLM-5.2 是最佳开源模型,以很大优势胜过 Kimi-K2.6 和 Minimax-M3。」
值得对比的是:GLM-5.2 在通用 Text Arena 只排第 25 左右,在 Agent Arena 排第 10——常规的多轮对话和一般 agent 任务并没有碾压对手。但一到前端 coding 这个垂直赛道,数据直接跳出一个断层。垂直训练和专项优化在真实任务上的威力,比论文里的 Elo 数字更说明问题。
1M 真上下文 + Agent 专项训练:真实工程的底牌
GLM-5.2 凭什么在前端 agentic coding 里打穿?
Z.ai 官方公布了两张牌。
第一张是上下文:1M token 上下文窗口。这个数字很多模型都标过,但 GLM-5.2 强调的是"可用"——不只是在跑分时塞满、而是在连续数小时的自主 agent 运行中不掉链子。它能同时装下一整个中型仓库的代码、多轮工具调用记录、测试日志和截图,然后在这些信息上做跨模块的根因定位和改动。
第二张是架构:IndexShare 稀疏注意力机制。每四层共享 indexer,1M 上下文下每 token 的 FLOPs 降低 2.9 倍。大白话说:模型可以"记住"更多东西,但同时推理成本不会跟着上下文长度一起爆炸。这个设计直接让长时程 agent 任务从"能跑"变成"能用在生产环境"。
然后是专项训练。Z.ai 在 GLM-5.2 上做了数月的 coding agent 专项强化——大规模实现、自动化研究、性能优化、复杂调试,覆盖的不只是"写对代码",更是"像一个真正的软件工程师那样完成一整个工程闭环"。
官方在 HF 模型卡上贴出的基准数据也印证了这一点:
-
SWE-bench Pro:62.1(GPT-5.5 58.6,Opus 4.8 69.2;GLM-5.1 只有 58.4) -
Terminal-Bench 2.1:81.0(Opus 4.8 85,Gemini 3.1 Pro 74;GLM-5.1 只有 62) -
FrontierSWE:74.4(GPT-5.5 72.6,Opus 4.8 75.1;与顶级闭源的差距缩到 1% 以内) -
MCP-Atlas(工具调用):77.0(Opus 77.8,GPT 75.3)
在长时程 agentic coding 的跑分上,GLM-5.2 已经是开源模型中最强的一个,多项数据正在逼近甚至局部超越顶级闭源。
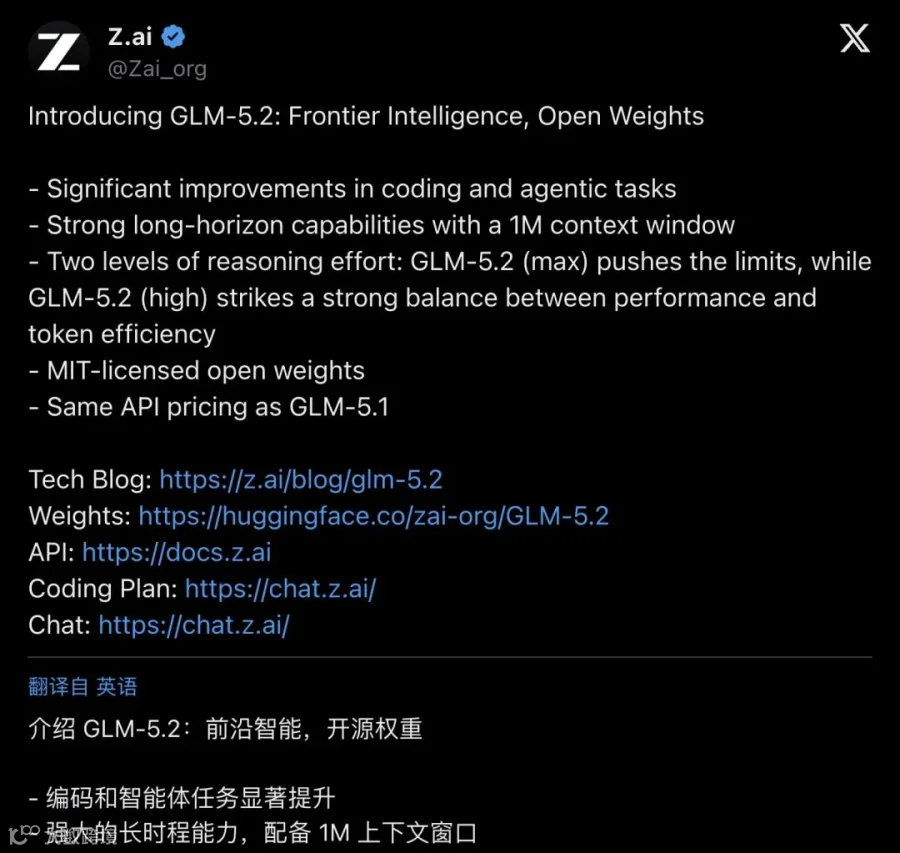
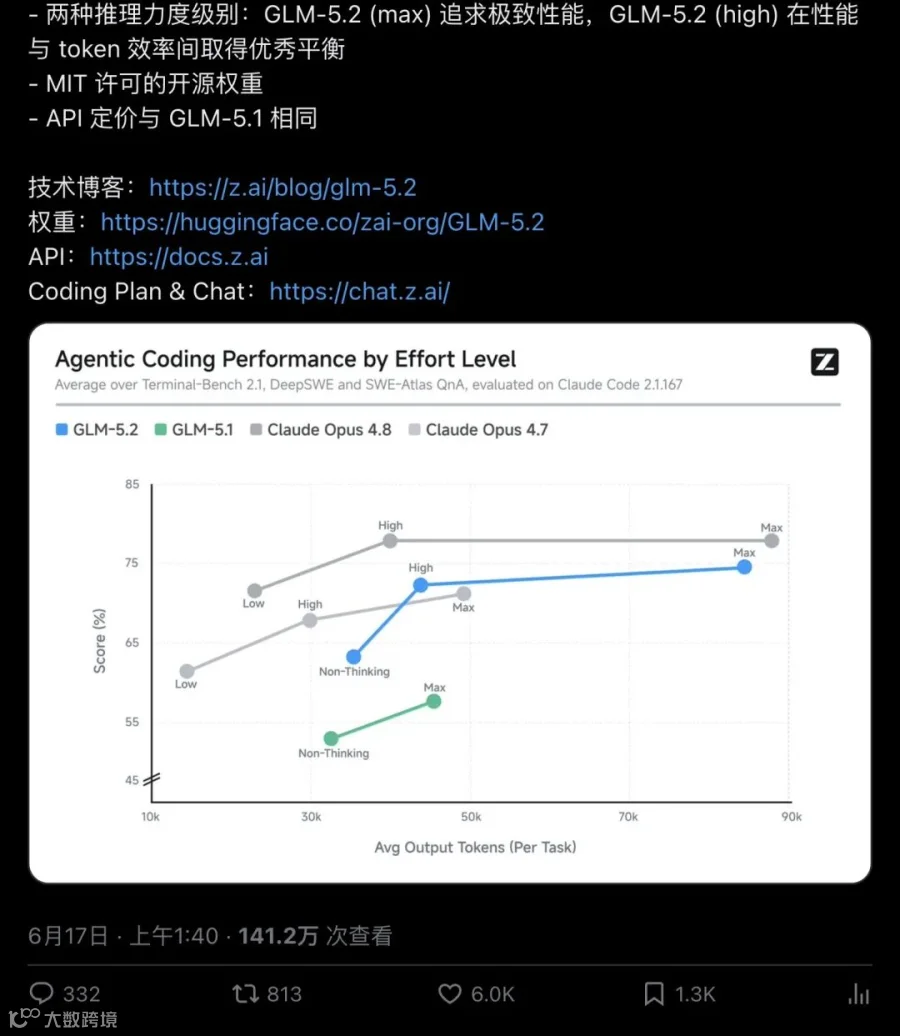
▲ Z.ai 官方发布帖:强调 coding/agentic 大幅提升、1M 上下文、两种推理力度(max/high)、MIT 开源、定价不变。超 6000 赞、141 万次浏览。
MIT 开源 + 不涨价,开发者群里先炸了
比跑分更让开发者兴奋的,是发布策略。
GLM-5.2 用的 MIT 纯开源许可——无地域限制、可以商用、可以本地部署、可以修改。753B 参数权重直接扔到了 Hugging Face 上,vLLM、SGLang 的本地部署配方随权重一起放出。
API 定价和上一代 GLM-5.1 完全一样:输入 $1.4/MTokens,输出 $4.4/MTokens。Fireworks、Cloudflare Workers AI、OpenRouter、Together、Baseten 等平台在发布当天就上线支持。
这个价格放在上下文里看更直观:跑一次需要 1M 上下文的完整 agent 任务,成本只有同类专有模型的几分之一。Fireworks 在自己的博客里专门点出:"per-token rate 不重要,真正重要的是 completed task 的单次成本。"它强调的重点是:单 token 价格只是账面数字,一整个任务跑完花了多少钱,才是真正决定成本的数字。
社区反应来得又快又猛:
"I've been playing around GLM 5.2... shattered the gap between open-source and proprietary models. It's fast, accurate... 5-8 times cheaper."
「我在试用 GLM 5.2……它打破了开源和专有模型之间的鸿沟。速度快、准确……便宜了 5 到 8 倍。」
"This should be bigger than the deepseek moment."
「这次的影响应该比 DeepSeek 时刻更大。」
也有开发者已经开始实装:"shipped it in @CommandCodeAI……everyone's been saying it's great with the /design command."(在 @CommandCodeAI 里上线了,大家都说 /design 效果极好。)
而另一些人踩到的问题也很真实:思考过程有时候长得离谱(个别任务 trace 超过 30 步,token 消耗极大)、部分用户说 vision 支持还不完善、以及"show me one piece of cool software built with 5.2"这种要求真实产品验证的声音。
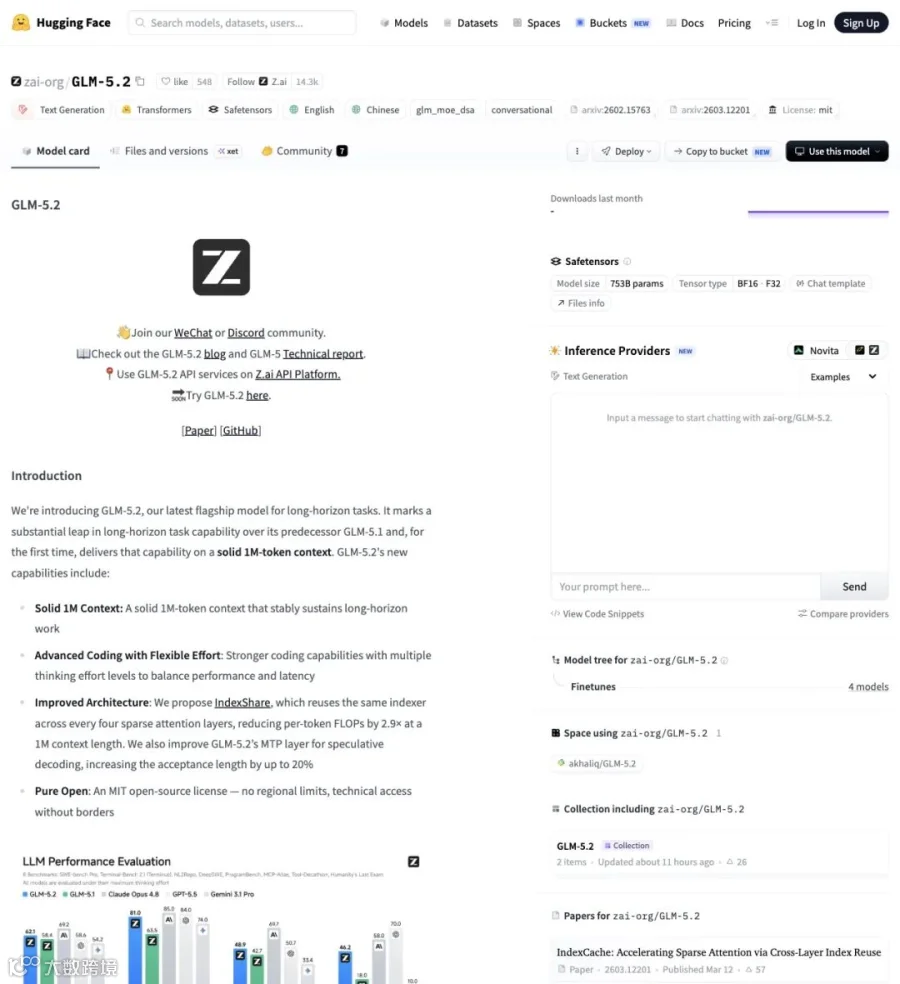
▲ Hugging Face 模型卡:753B 参数、MIT 许可、IndexShare 架构说明、详细基准对比表——GLM-5.2 在多项 long-horizon coding 指标上领跑开源,并逼近顶级闭源。
前端赛道为什么是 AI 生产力的"最可见战场"
GLM-5.2 选择前端 coding 作为突破口,不是偶然。
前端是 AI 生产力最容易被"看见"的方向。后端优化跑分快 10%,用户无感;但一个前端 agent 能不能在 15 分钟内把设计稿变成可交互页面、能不能在老板改需求后三分钟内重新出活、能不能handle 品牌色、动画曲线、移动端适配和跨浏览器兼容——每一件事都直接摆在眼前,行还是不行,没有灰色地带。
Arena 的前端子类别——品牌与营销、数据看板、消费产品、游戏、模拟——覆盖的正是这个"从设计到交付"的完整链条。GLM-5.2 在这些类别里全部第 1,说明模型覆盖了整个前端 agentic coding 的大分布,实现了系统性的提升——零散的一两种任务碰巧表现好,出不来这种全面霸榜的成绩。
更深一层看,前端也是"长时程 agent 可靠性"的绝佳测试场。一个复杂前端任务要走工具调用、读文档、生成代码、跑预览、根据截图反馈修复——整个过程可能持续十几分钟到一小时,中间任何一个环节出现 coherence 崩坏就会直接失败。GLM-5.2 在这种真实工作流里站住了,这是 1M 上下文工程和专项 agent 训练共同作用的结果。
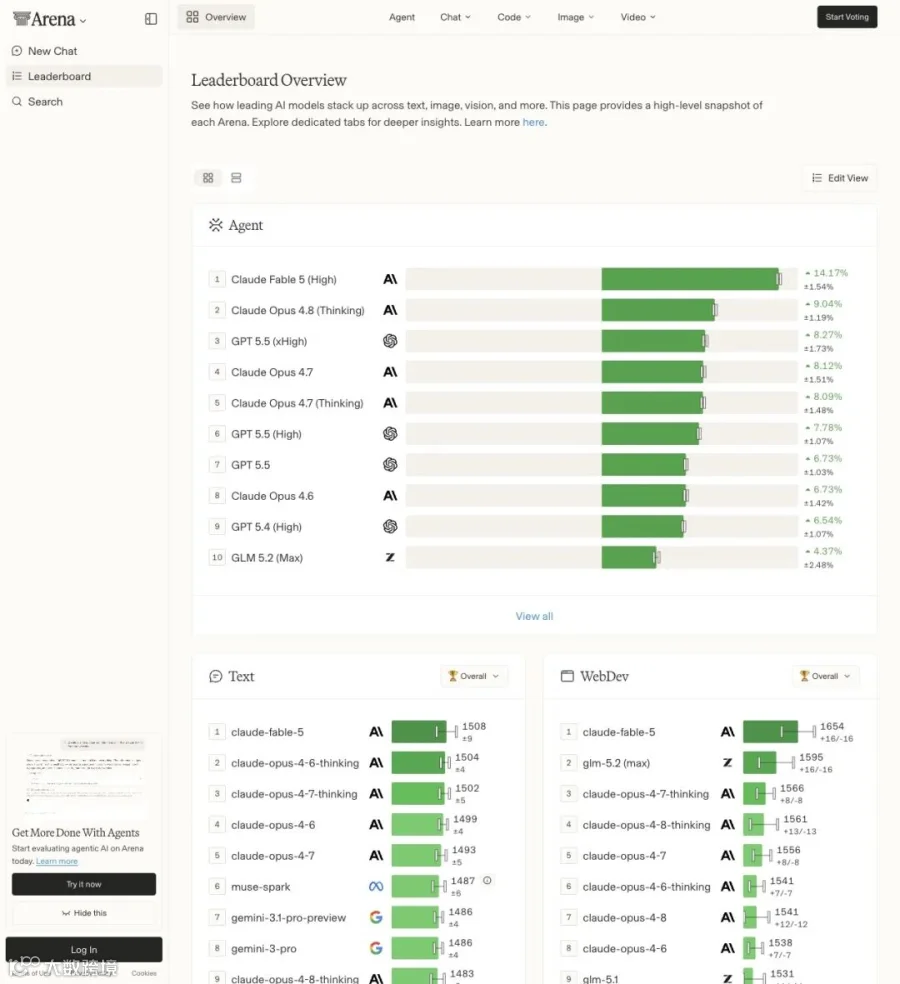
▲ Arena.ai 公开排行榜概览:WebDev 区 GLM-5.2 (Max) #2 高亮可见;Agent 区 Fable/Opus 序列并列展示。榜单可公开验证。
Fable 争议反而让这件事更真实
排行榜出来后,争议声也跟着来了。
最大的争论点就是 Fable 5。它排第 1 但不可用——社区描述它是一个"multi-model ensemble,在特殊 harness 下频繁 fallback 到 Opus 4.8"的组合体。普通开发者拿不到、用不了、也无法在本地部署。把它从榜单里拿掉之后,GLM-5.2 就是第一。
"The chart... shows drastic difference visually even when the diff is minuscule."
「这张图在视觉上放大了差异,即使实际的分数差距很小。」
"Is it really #1 for front end coding or #1 for front end coding benchmarks?"
「它真的是前端 coding 的第一,还是前端 coding 基准测试的第一?」
还有人提出 Kimi-K2.7 code 模式在榜单上的对齐可能不完整、个别用户遇到的错误率偏高(特别是思考链路冗长时)。
但这些质疑本身反而强化了核心结论:当一个开源模型能在真实用户盲评中打败 Claude Opus,并且引发的是"Fable 到底算不算数""视觉差异是不是被夸大了"这种层面的争论——说明它已经进入专有模型俱乐部,在讨论顶尖座次了,再也不是站在门外的旁观者。
智谱上市成为全球首个大模型股之后,GLM-5.2 的开源推进比很多人预想的更快、更垂直。前端 coding 这个"最可见的战场"上,开源模型已经撕开了一道口子。
后面的硬仗在真实工程场景里:多轮迭代、大型遗留代码库、团队规范约束。跑分能告诉你的,永远只是第一章。
— END —