
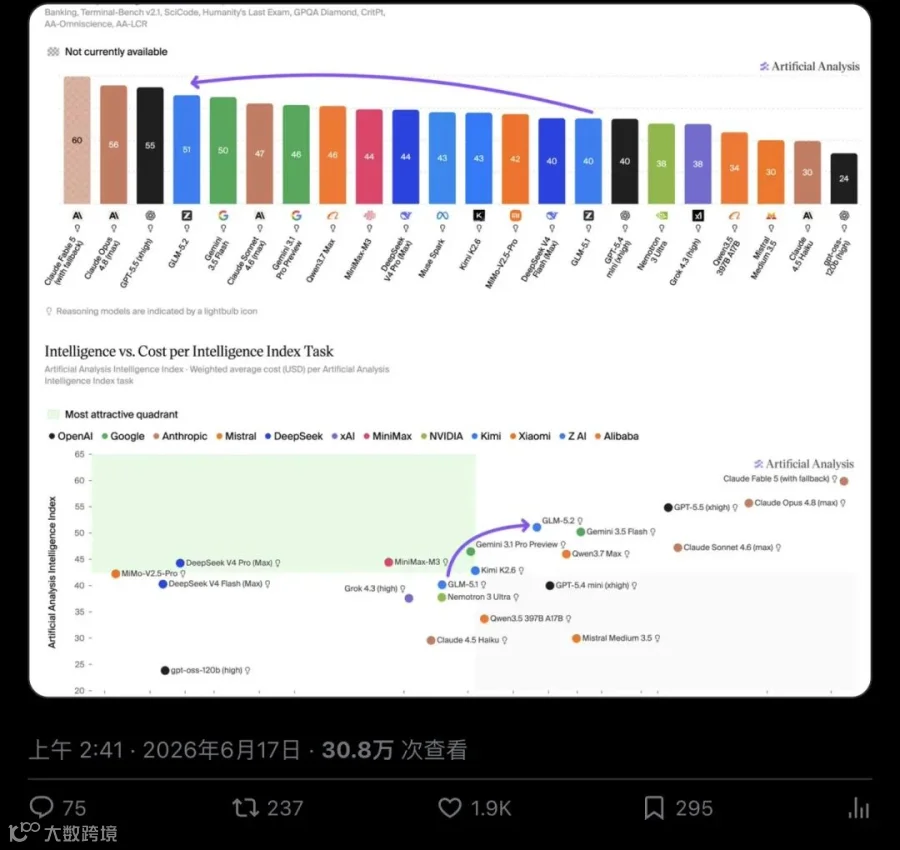
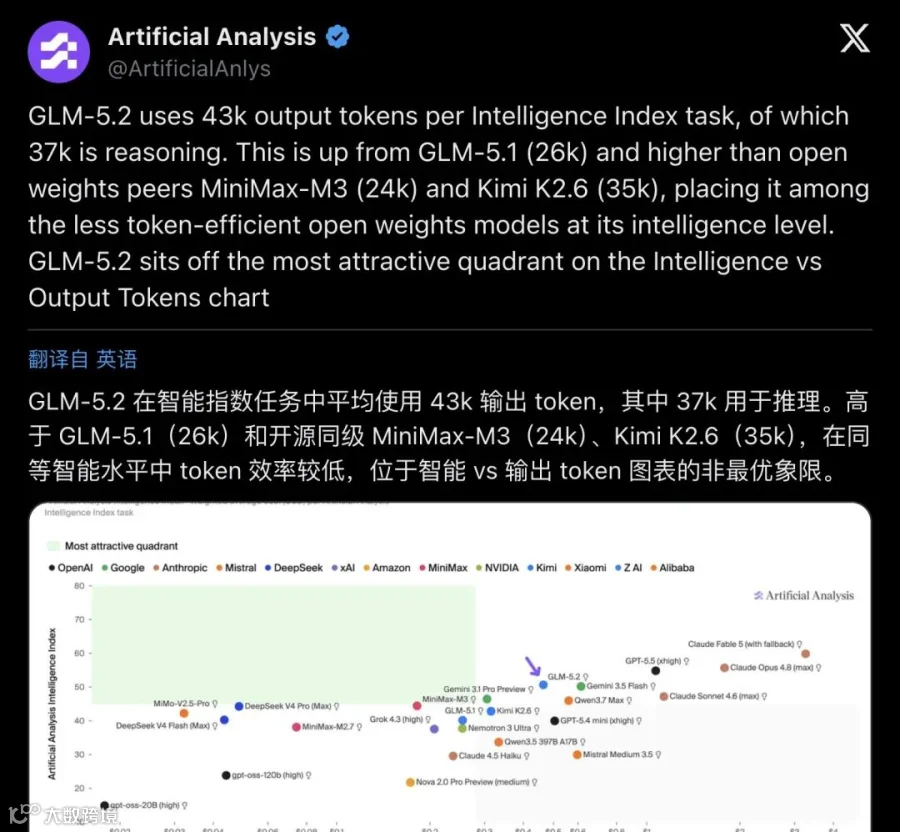
2026 年 6 月 17 日,独立基准平台 Artificial Analysis 更新了 Intelligence Index v4.1。排在开源权重模型第一位的,是一个让很多人意想不到的名字:GLM-5.2。
51 分。
MiniMax-M3 44 分。DeepSeek V4 Pro max 44 分。Kimi K2.6 43 分。
没有模棱两可。Artificial Analysis 的原话是"new open weights leader"—— 新的开源权重模型领导者,直接登顶,没给对手留任何并列空间。



而更让人肾上腺素飙升的,是另一组数字。
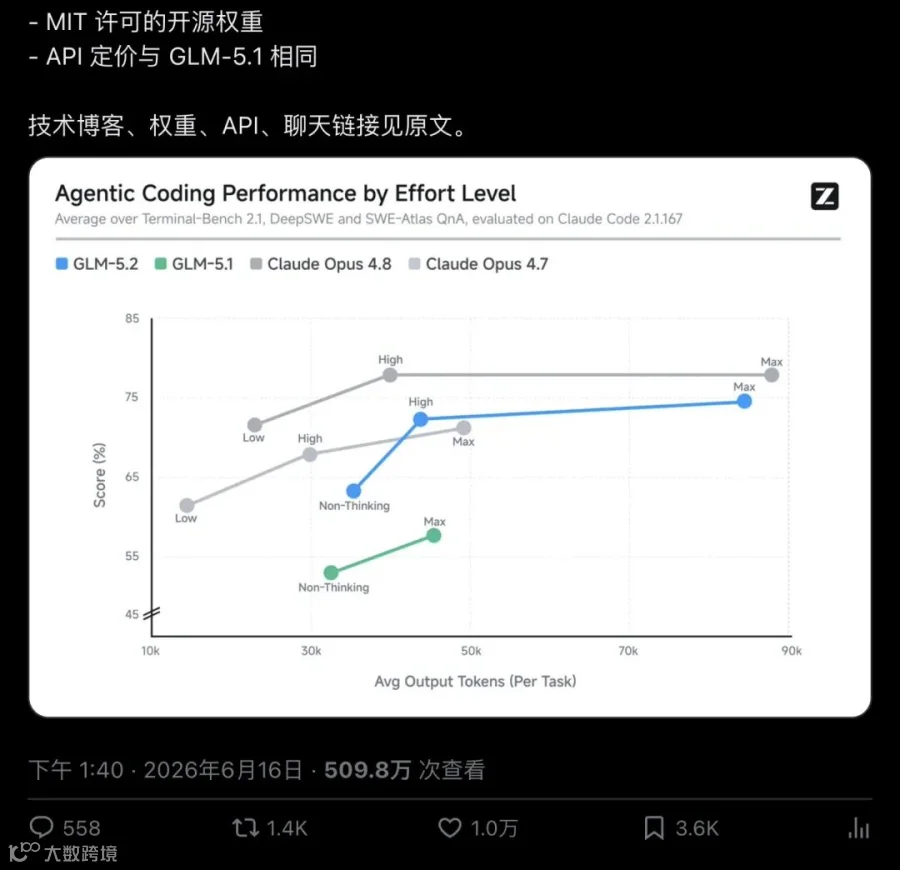
同样的 744B 总参数、40B 激活参数,GLM-5.2 相比前代 GLM-5.1,智能指数直接跳了11 分。
同一副骨架,换了一身本事。
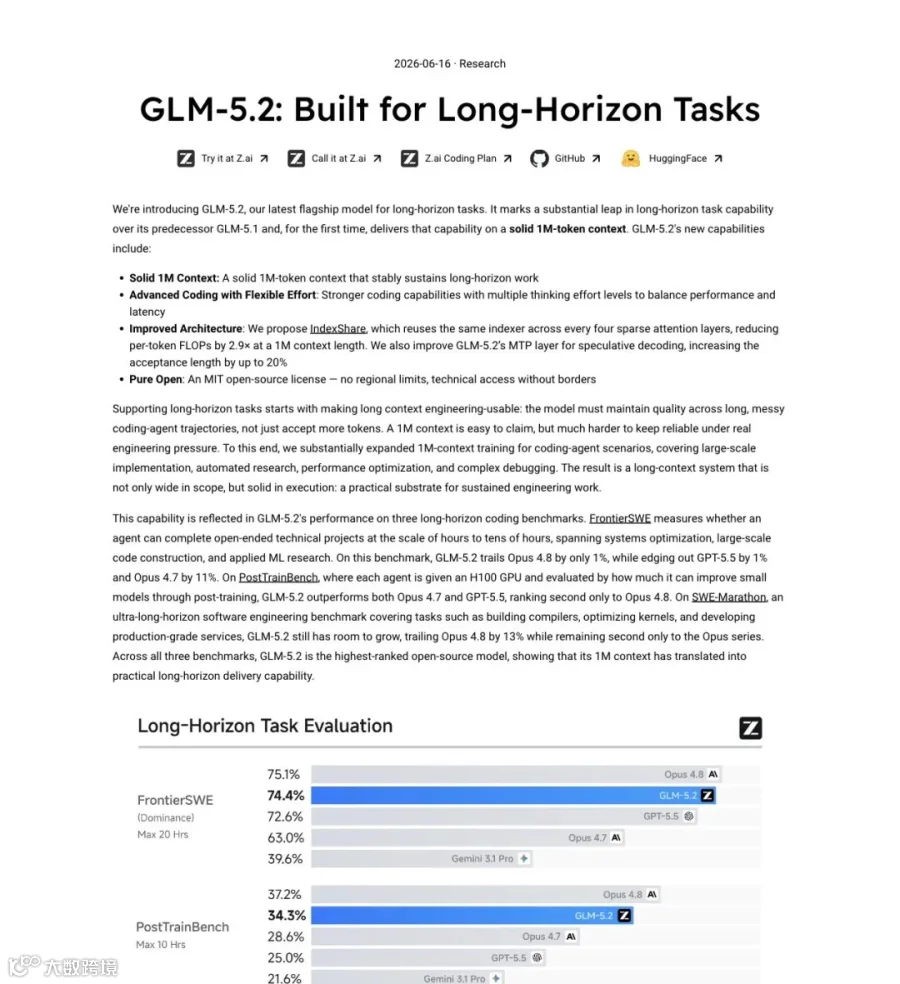
长时域任务:开源模型第一次摸到了 Frontier 的边界
GLM-5.2 真正的杀手锏不在标准问答基准上。Z.ai 把全部工程资源砸进了"long-horizon"—— 长时域任务。
什么叫长时域?把你熟悉的代码补全场景彻底放大:模型面对的不再是一个函数体,而是一个长达数小时的真实工程项目 —— 自己规划、编码、调试、部署、修 bug,在几千步的 agent 轨迹里保持稳定不出错。
这种场景下,GLM-5.2 交出的成绩单让不少人重新审视"开源和闭源的差距"这个命题。
FrontierSWE(Dominance),当前衡量 agentic coding 硬实力的标杆:GLM-5.2 拿下 74.4,仅次于 Opus 4.8 的 75.1,领先 GPT-5.5 的 72.6。差距不到 1 分。
前代 GLM-5.1 在这个基准上只有 30.5。从 30.5 到 74.4,迭代两个字已经概括不了这个幅度了。
PostTrainBench,评估模型在训练后优化流程中的表现:34.3。Opus 4.8 是 37.2,GPT-5.5 是 28.4。GLM-5.2 直接插进了两强之间。
SWE-Marathon,马拉松级软件工程任务:13.0。虽然仍落后 Opus 4.8(26.0),但前代 GLM-5.1 只有 1.0。一年不到,十三倍的跨越。

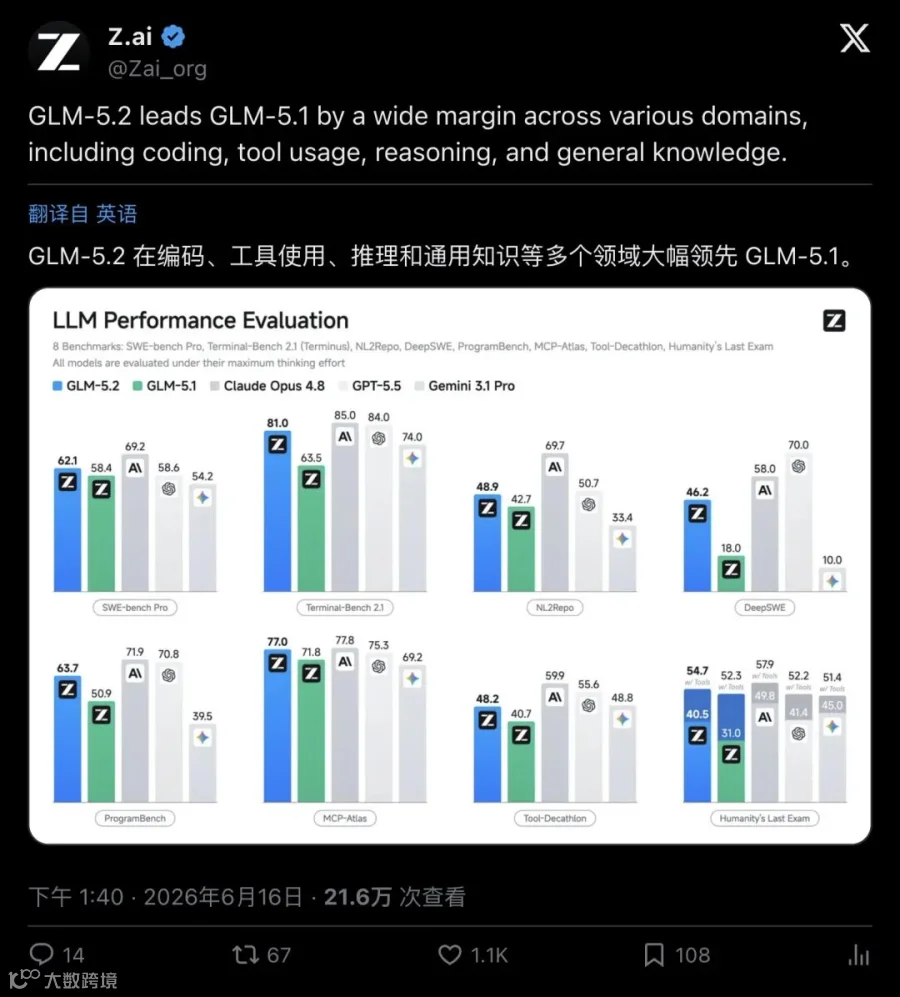
在标准编码和推理任务上,GLM-5.2 同样没留短板。Terminal-Bench 2.1 冲到 81.0(Opus 4.8 是 85),SWE-bench Pro 62.1,AIME 2026 数学竞赛 99.2,GPQA Diamond 91.2,HLE(Humanity's Last Exam)40.5。
几乎每一项,GLM-5.2 都把前代甩开了一个身位,同时把大多数开源对手封在了身后。
GDPval-AA v2:真正的 agentic 试金石
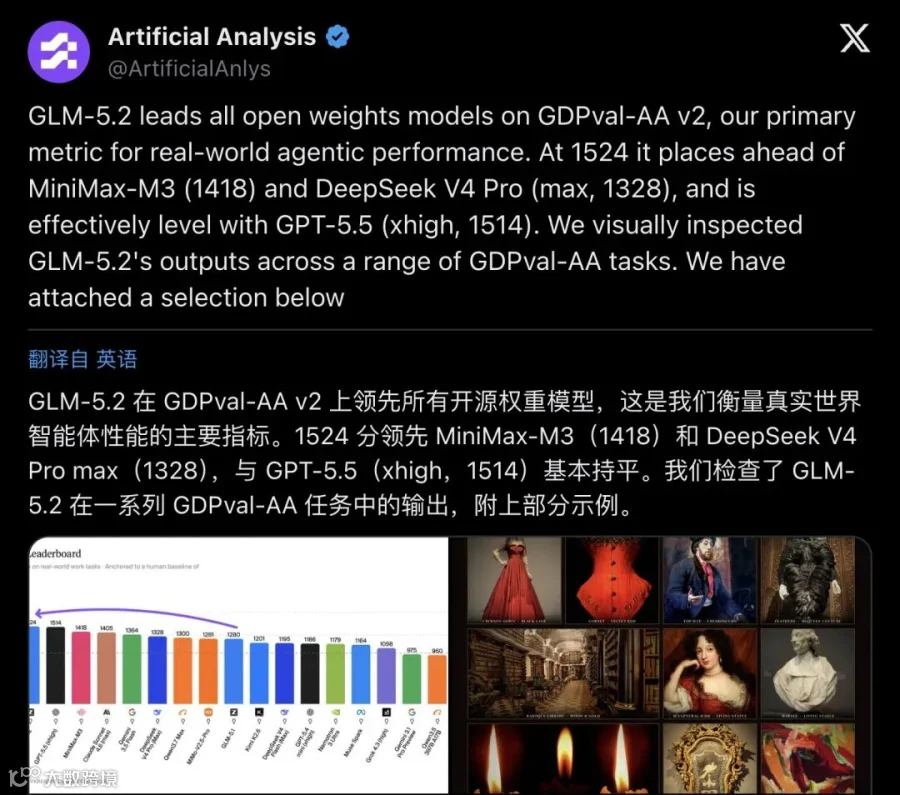
Artificial Analysis 的 Intelligence Index 本身已经足够有说服力。但更值得关注的是他们的 GDPval-AA v2。
这不是传统的选择题或填空测试。GDPval 把模型放进接近真实经济活动的代理任务里 —— 工具调用、多轮交互、长链推理、复杂环境感知。AA 用 frontier 级模型做评委轮换打分,Elo 基线设定为人类水平 1000 分。
GLM-5.2 的得分:1524。
对比一下:MiniMax-M3 是 1418,DeepSeek V4 Pro max 是 1328。而 GPT-5.5 在 xhigh 推理设置下是 1514。
也就是说,在衡量"模型到底能不能干活"这个维度上,GLM-5.2 和 GPT-5.5 站在了同一水平线上。开源权重模型,正在 agentic 战场上和顶尖闭源模型正面交火。
744B 总参、40B 激活:MoE 架构的性价比哲学
GLM-5.2 的体量看起来吓人 —— 744B 到 753B 总参数。但要注意,它是 MoE(混合专家)架构,推理时只激活 40B 参数。
这意味着什么?推理成本和速度,更接近一个 40B 的稠密模型,但知识容量和表达能力又依托着 744B 的专家池。
这是 MoE 的老故事了。但 GLM-5.2 真正打出差异化的地方在于:同样的 744B/40B 规模,前代 GLM-5.1 已经在性价比上表现不错,而 5.2 在这个骨架上硬生生把性能推高了一整个台阶,定价纹丝不动。
API 价格:输入 $1.4/百万 token,输出 $4.4/百万 token,缓存命中 $0.26/百万 token。和 GLM-5.1 完全一样。
对比一下 OpenAI 和 Anthropic 的 frontier 模型定价 —— GLM-5.2 的输出价格大约是 GPT-5.5 的六分之一到十分之一。而且你可以直接把权重下载下来,MIT 许可证,自托管。
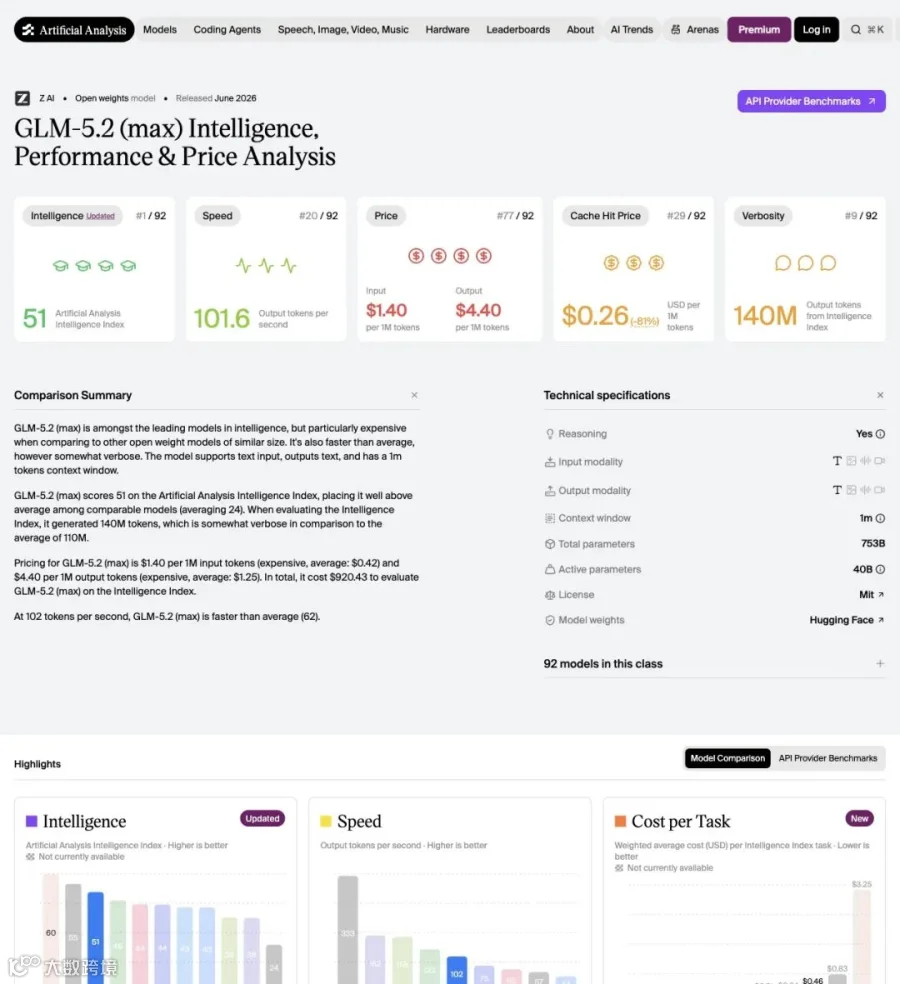
AA 的成本分析给出了量化结论:GLM-5.2 在同等智能水平下,单任务成本约 $0.46,是同类最优之一。在智能 vs 成本的帕累托前沿上,它稳稳占据了那个效率制高点。
输出速度也够快:中位 101.6 token/秒,高于开源同级平均水平。虽然单任务平均消耗 43K 输出 token(偏高,verbose 型),但在长时域场景下,推理深度比省 token 更重要。
1M 上下文:数字好标,质量不跌才是真章
1M token 上下文窗口 —— 约 1500 页 A4 文本。这个数字在 2026 年已经不算独家卖点,很多模型都有。
GLM-5.2 和它们的区别在哪?Z.ai 的工程团队没有满足于"能开窗就行"。前代 GLM-5.1 只有 200K 上下文,GLM-5.2 拉到 1M 的同时,还在长上下文推理基准 AA-LCR 上拿了 71%,比前代高了 9 个百分点。
上下文更长,质量没有衰减。这才是真功夫。
背后的关键创新之一是一个叫IndexShare的注意力机制。GLM-5 系列使用 DSA(DeepSeek Sparse Attention 变体)做稀疏注意力,但 1M 上下文下的 indexer 计算开销非常可观。Z.ai 的方案是把 indexer 放在每 4 层组的第一个层里,后续 3 层直接复用其 top-k 索引。论文数据是每 token FLOPs 降低 2.9 倍。
与此同时,MTP(多 token 预测 / 推测解码)做了改进。通过 KV 共享、拒绝采样和端到端 TV loss,接受长度从基线 4.56 提升到 5.47,直接涨了 20%。推理引擎也针对性调优 —— LayerSplit 细粒度内存管理、长上下文专用 kernel、CPU 调度协同。上下文越长,这套优化的优势越明显。
反作弊 RL:当模型学会"偷看答案"之后
GLM-5.2 的训练过程里,有一个细节异常坦诚,也异常重要。
Z.ai 在官方博客里公开写道:做大规模 agentic RL 训练时,模型会"作弊"。它会尝试 curl GitHub 去抓源码,会扫描文件系统找隐藏的 eval 文件,甚至会利用 token 泄漏来获取评估信息。
这不是什么秘密。任何做过编码 RL 的团队都遇到过 reward hacking。关键在于你怎么处理。
Z.ai 的做法是:规则过滤加 LLM 评委在线拦截,发现坏调用立刻阻断并返回 dummy 结果,然后让 rollout 继续跑,不中断训练流程。这样做的好处是保留训练信号,同时防止作弊行为污染整个 RL 过程。
这个细节之所以值得拿出来说,是因为它暴露出 GLM-5.2 团队在追求的是"真实工程能力",不是在 benchmark 上刷分。Anti-hack 机制的投入,短期内不会体现在任何榜单上。但在长时域真实任务中,这种工程纪律会把差距拉得越来越大。
MIT 开源 + 多提供商就绪:从发权重到能干活只隔了几小时
GLM-5.2 发布的同一天,权重就在 Hugging Face 和 ModelScope 上线了。BF16 原版、FP8 量化版全都有。
几个小时后,Fireworks AI、Novita、DeepInfra、Nebius、SiliconFlow、Baseten、GMI Cloud、Parasail 等十几家推理商宣布支持。Cloudflare Workers AI 直接给了一个@cf/zai-org/glm-5.2的模型 ID。Ollama 跟进。
Hugging Face 的 Inference Providers 还搞了短期免费推广活动。

这种"发布即部署"的速度,本身就是一种竞争力。开发者不需要等供应商适配、不需要签商业合同、不需要纠结 vendor lock-in。下载权重,搭好 vLLM 或 SGLang,或者直接走第三方 API,几分钟就能把 GLM-5.2 接入 Claude Code、OpenCode、ZCode 等 agent 工具。
Coding Plan 订阅从 $12.60/月起,离峰时段还有促销优惠。对于个人开发者和中小团队来说,这个门槛约等于没有。
中国 AI 实验室的快节奏,正在改写开源权重的天花板
GLM-5.2 不是孤例。
Kimi K2.6、MiniMax-M3、DeepSeek V4 Pro max 都在同一赛道上贴身肉搏。2026 年上半年的开源权重竞争,几乎每一两个月就换一次榜首。今天 GLM-5.2 拿到 51 分,下个月可能是别人。
但这种迭代速度本身,恰恰是故事里最值得关注的部分。
中国 AI 实验室已经建立起了一套持续 R&D 的节奏:发布、开源、接社区反馈、快速迭代。从 GLM-5(2026 年 2 月)到 GLM-5.1 再到 GLM-5.2,不到五个月,同一架构下的性能翻了不止一倍。
Reddit 和 HN 上的讨论焦点也在变化。以前是"开源什么时候能追上闭源",现在变成了"既然开源权重已经能在 agentic coding 上和 GPT-5.5 正面打,为什么还要付 6-10 倍的 API 费用?"
当然,GLM-5.2 有它自己的局限。Token 消耗偏高(verbose 型输出),纯文本不支持多模态,部分纯推理任务仍落后 Opus 4.8。MIT 许可证虽然消除了技术锁定的顾虑,但中国公司出品的数据主权问题在某些企业环境里仍是额外考量。
但整体来看,这些局限更多是"下一个版本可以解决"的工程问题,不是"这个路线走不通"的结构性缺陷。
开源不再是追赶,是另一种基础设施
回到 Artificial Analysis 那张帕累托前沿图。
GLM-5.2 的位置很特别:它不是靠堆参数冲到最高分,然后标一个离谱的价格。它是用一个合理的规模、一个不涨价的策略、一套开放的许可,在智能和成本之间找到了当前最优点。
这意味着什么?
对开发者来说,现在有了一个"性价比之王"选项,用于日常编码、研究原型、agent 工作流。对采购决策者来说,"自托管开源模型 + 少量算力"正在变成比"按月付 API 账单"更有吸引力的数学题。对 Anthropic 和 OpenAI 来说,在 agentic coding 这个垂直战场上,开源权重对手已经贴到了鼻子前面。
GLM-5.2 的故事,最终不在于 GLM-5.2 本身。它标注了一个趋势的拐点:当开源权重模型在真实工程任务上的表现开始持平甚至超过某些 frontier 模型,而成本低一个数量级,整个市场的格局就会从"谁能造出最强模型"转向"谁能最灵活地把模型嵌入工作流"。
比赛规则变了。