
只要 16GB 内存,一台普通笔记本就能跑起多模态 AI Agent——Google 刚发布的 Gemma 4 12B 把这件事变成了现实。更炸裂的是,这个 12B 参数的模型在标准 benchmark 上逼近了自家 26B 模型的表现,还砍掉了传统多模态模型里的视觉和音频编码器,把延迟和内存占用压到了前所未有的低。当云端大模型还在按 token 收费的时候,Google 正在悄悄把 Agent 的战场搬到你的桌面上。
16GB,这是 Google 画的一条线
6 月 3 日,Google 正式发布 Gemma 4 12B。
在官方博客里,Google 开门见山地写了一句话:
"Gemma 4 12B is designed to bring high-performance multimodal intelligence directly to your laptop."
「Gemma 4 12B 旨在将高性能多模态智能直接带到你的笔记本电脑上。」
▲ Google 官方博客宣布 Gemma 4 12B 发布
注意这里的措辞——directly to your laptop。不是工作站,不是云服务器,是笔记本。
Google 给出的硬件门槛是16GB VRAM 或统一内存。这意味着什么?一台 M1/M2/M3 MacBook Air,一台带 RTX 4060 的 Windows 笔记本,甚至很多两三年前的中端机器,都在这条线以上。
过去一年,本地模型的讨论一直困在一个循环里:能不能跑?跑得动吗?量化之后还剩多少智商?Google 这次直接把问题往前推了一大步——能跑只是起点,关键是跑了之后能干什么。
12B 打 26B?Google 说「接近了」
Gemma 4 12B 在官方定位中有一个非常大胆的说法:
"Benchmark performance nearing our 26B model, unlocking powerful multi-step reasoning and agentic workflows."
「在标准 benchmark 上接近 26B 模型的表现,解锁强大的多步推理和 Agent 工作流。」
The New Stack 在报道中直接用了「nearly matches 26B benchmarks and runs on your laptop」做标题。Ars Technica 则写道,Gemma 4 12B 使用了新的编码方案和 token 预测技术,让它能够以小博大。
▲ The New Stack 报道称 Gemma 4 12B 接近 26B benchmark 表现
▲ Ars Technica 称其用新编码方案和 token 预测「以小博大」
但这里需要冷静一秒钟。
所谓「接近 26B」,指的是标准 benchmark 分数。真实世界里的 Agent 工作流——工具调用的稳定性、长任务中的上下文管理、出错后的自我修复——这些远比单次 benchmark 更难。12B 的真正优势不在于「打赢 26B」,而在于用一半不到的内存,拿到了接近的分数。
换句话说,Google 赌的不是绝对性能,而是性价比曲线上的甜蜜点。
砍掉编码器:一个激进的架构选择
Gemma 4 12B 的架构里藏着一个相当激进的决定:把传统多模态模型里的视觉编码器和音频编码器全部移除。
Google 官方这样描述:
"No multimodal encoders. The vision and audio inputs flow directly into the LLM backbone."
「没有多模态编码器。视觉和音频输入直接流入 LLM 主干网络。」
传统的多模态大模型长什么样?一个语言模型主干,外挂一个视觉 encoder,再挂一个音频 encoder。图片先过视觉 encoder 转成视觉 token,音频先过音频 encoder 转成音频 token,然后再喂给语言模型。好处是模块化清晰,坏处是每个 encoder 都在吃参数、吃内存、加延迟。
技术博主 Maarten Grootendorst 在他的架构图解中给出了一个关键数据:之前 Gemma 4 E2B/E4B 的视觉 encoder 大约1.5 亿参数,26B/31B 的视觉 encoder 约5.5 亿参数,音频 encoder 还要额外加。Gemma 4 12B 把这些处理全部压进了轻量 embedding 模块和 LLM 的 attention 层。

▲ 技术博主 Maarten Grootendorst 的 Gemma 4 12B 架构图解
这带来了两个直接好处:更低的延迟和更少的内存占用。视觉和音频信号不再需要排队等编码器处理完毕,而是直接进入推理流水线。
但这绝对不是免费午餐。encoder-free 架构本质上是把感知和对齐的压力全部转嫁给了 LLM 主干——12B 的模型主干必须自己学会「看图」和「听声音」。在复杂的视觉空间关系、细粒度音频理解这些任务上,它能不能比得过专门的 encoder 架构,还需要更多实测。
Google 在赌一件事:对于本地部署的场景,低延迟和低内存比极致感知精度更重要。
Agent 工作流:这才是真正的野心
如果你仔细看 Google 的发布材料,会发现一个词反复出现:agentic。
"Today, we are introducing Gemma 4 12B, our latest model designed to bring agentic multimodal intelligence directly to laptops."
「今天我们推出 Gemma 4 12B,我们最新的模型,旨在将 Agent 式多模态智能直接带到笔记本上。」

▲ Google DeepMind 将 Gemma 4 定位为面向 Agent 工作流的开放模型
Google 不只是在发布一个聊天模型。它想让 12B 成为你笔记本里常驻的 AI 代理——接进本地 IDE 帮你审代码,连接文件系统帮你整理笔记,处理截图和图表做数据分析,甚至听一段会议录音自动生成摘要。
这背后的逻辑很清晰:如果模型足够小、足够快,它就可以从「按需调用」变成「常驻后台」。
你不再需要每次打开一个网页、输入一段 prompt、等待云端响应。一个 12B 模型挂在后台,随时待命,接收文本、图片、音频输入,执行多步推理,调用本地工具——这就是 Google 描述的「agentic workflow」。
对企业来说,这意味着隐私敏感数据不用出本地。对学生和独立开发者来说,这意味着零 API 成本。对离线或弱联网场景来说,这是唯一的选择。
Gemma 家族的「中间层」棋局
Gemma 4 12B 不是孤立发布的。它在 Gemma 4 家族中占据了一个非常精心设计的位置:
- E2B / E4B
:超轻量边缘模型,适合手机和 IoT 设备 - 12B
:笔记本和消费级 GPU 的甜点区 - 26B / 31B
:工作站和高端显卡的重型选手
▲ Gemma 4 12B 已在 Hugging Face 上线,采用 Apache 2.0 协议
▲ Google AI for Developers 的 Gemma 4 12B 发布记录
Google 还公布了一个数字:Gemma 模型的总下载量已突破 1.5 亿次。这说明 Gemma 已经不是一个实验性项目,而是一个拥有庞大开发者基础的成熟分发渠道。
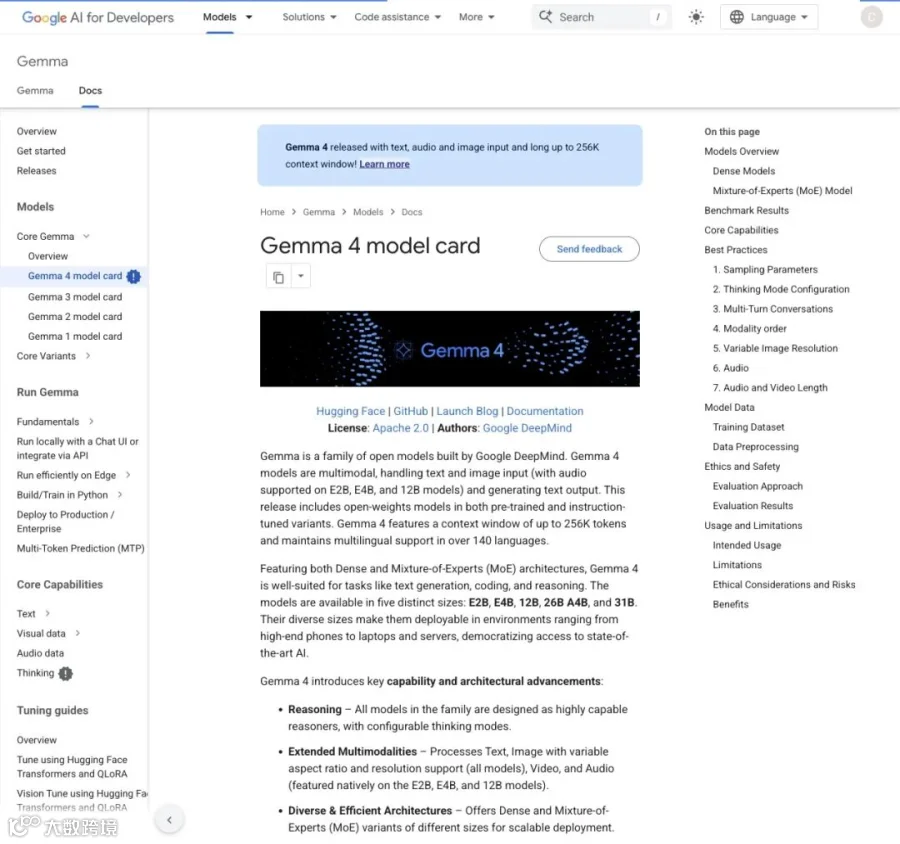
▲ Gemma 4 模型卡:支持文本、图像和音频输入,最大 256K 上下文
模型卡显示,Gemma 4 家族支持文本和图像输入,E2B、E4B 和 12B 还额外支持音频输入,最大上下文窗口达到256K token。配合多语言支持和 Apache 2.0 开源协议,Google 显然在给开放模型生态补齐从模型训练、文档、部署到压缩优化的完整链条。
12B 的定位堪称精准:它是大量 16GB 个人设备的能力上限——再往上就需要更贵的硬件。一旦这个档位的模型质量足够好,它就会成为工具开发者优先适配的默认本地模型。
别急着吹:这些坑要看清
Google 画了一个很诱人的饼,但几个问题必须提前说清楚。
第一,16GB 能跑和 16GB 跑得舒服是两回事。上下文长度、量化方式、batch 大小、KV cache、图像和音频输入都会吃内存。别以为所有 16GB 机器都能流畅跑完整个 Agent 工作流。
第二,benchmark 接近 26B 不等于真实任务接近 26B。多步 Agent 任务最怕什么?中途偏航、工具调用参数出错、上下文遗忘。这些在 benchmark 里测不出来,需要大量实际场景验证。
第三,本地 Agent 带来了全新的安全问题。如果模型能调用本地工具、读写文件系统,那 Agent 的权限管理、沙箱隔离、审计日志会比模型分数重要一万倍。跑在云端时,安全边界在服务商那里;跑在本地时,你就是自己的安全官。
本地 AI 的分水岭时刻?
回头看,Gemma 4 12B 发布的真正意义不在于又多了一个开源小模型。
它标志着一个转折:本地模型的叙事从「能不能跑」跳到了「能不能当 Agent 用」。
16GB 内存的笔记本上跑多模态 AI Agent,看图、听音频、多步推理、工具调用——一年前这还是云端大模型才有资格讲的故事。Google 正试图证明,这个故事可以在你面前的这台电脑上发生。
至于它到底能不能兑现这个承诺,答案不在 benchmark 表格里,而在接下来几个月开发者的实际使用中。
但有一点可以确定:本地 AI Agent 的竞赛,已经正式开始了。