
2026年6月,Google Cloud发了一条推文——"十年前,主流看法说定制芯片是个错误。今天,它就是Agentic时代的架构基石。"第八代TPU首次拆分为两颗芯片:TPU 8t专攻训练(9600芯片Superpod,121 FP4 ExaFlops),TPU 8i专打推理(384MB片上SRAM,三倍于前代)。从2015年28nm工艺的v1到如今的双芯架构,十年八代,Google把一桩"行业笑柄"做成了AI基础设施的底层宪法。
十年前,所有人都说这是错的
2013年,Google内部做了一次规模推演。
把语音识别、图片搜索、翻译这些AI功能推到全球规模,需要多少算力?结论让会议室安静了:现有数据中心全部资源吃不下,甚至要翻倍建机房。
Jeff Dean的态度很明确:肯定有更好的方式。
但"更好的方式"在当时听起来像个冷笑话。一家互联网公司要自己造芯片。不买NVIDIA显卡,不加Intel服务器。从零开始设计硅片。行业共识只有三个字:别碰它。
Amir Salek组建了Custom Silicon团队,Norman Jouppi出任首席架构师。15个月。设计、验证、部署,首颗TPU v1在2015年内部上线。
v1的规格今天看来极其原始:28nm工艺,256×256脉动阵列,8-bit整数运算,28-40W功耗,峰值几十TOPS。但它只做一件事——矩阵乘法和激活函数——而且做得比同期CPU快15到30倍,每瓦性能高30到80倍。
Google Photos每天处理过亿张图片。Street View提取全球街景文字,全库几天跑完。AlphaGo对战李世石。RankBrain重塑搜索排序。这些早期杀手应用的底层,跑的是同一颗芯片。
2017年ISCA论文发布后,学术界终于看清了:在生产环境里,一颗为张量计算定制的ASIC,能把通用芯片甩开一个数量级。
▲ Google Cloud官推于2026年6月14日发布:"十年前,主流看法说定制芯片是个错误。今天,它就是Agentic时代的架构基石。"43K+浏览
每一代都在打脸"自研无用论"
v1证明了推理可行。训练呢?
Norm Jouppi后来说:"人们觉得训练芯片太复杂了……于是我们决定,造一台训练超级计算机。"
v2(2017)引入bfloat16——Google Brain发明的精度格式,兼顾动态范围与效率。HBM内存、256芯片Pod互联、Cloud TPU首次向第三方开放。从"Google秘密武器"变成行业基础设施。
v3(2018)性能翻倍,直接上液冷,Pod规模扩到1024芯片。AlphaZero在这个时期爆发。
v4(2021)放了个大招:光学电路开关(OCS)。Pod内任意芯片对通过光路动态重连,大Pod利用率和容错能力直接跃升一个台阶。
v5系列(2023)开始分流——v5p打训练峰值,v5e打推理性价比。这是Google第一次按workload分路线,为后来的双芯片伏笔埋下。
Trillium/v6(2024)单芯片峰值性能较v5e提升4.7倍,能效提67%。此时TPU已是Google所有AI产品(搜索、照片、地图、Gemini系列)和DeepMind基石模型的底层动力。Cloud客户名单里有了Anthropic、Midjourney、Salesforce。60%以上获融资的生成式AI初创、近90%的AI独角兽跑在Google Cloud AI基础设施上。
Ironwood/v7(2025)被Google称为"推理时代的第一颗TPU":9216芯片液冷Pod,42.5 ExaFlops——El Capitan世界最大超算的24倍。192GB HBM,7.37TB/s带宽。
然后到了2026年4月。Google Cloud Next大会。
第八代TPU亮相。两颗芯片,两套架构——Google第一次把训练和推理彻底拆开。
▲ Google官方博客由Amin Vahdat署名发布,标题:"我们的第八代TPU:两颗芯片,为Agentic时代而生"
分家的底层逻辑:看见了下个十年的问题
第八代TPU拆成两路。表面看是代际升级,底层推动力是架构层面的结构性重构。
Agentic AI跟以前所有的AI都不一样。Agent的本质是"感知→规划→工具调用→执行→反馈→RL微调"的连续循环——跟过去的一次性问答有根本性差异。需要海量KV cache做状态记忆,需要MoE专家路由(all-to-all通信模式),需要多Agent协作(频繁collectives操作),对尾延迟敏感到毫秒级。几百万个Agent并发的时候,功率墙是第一硬约束。
硬件开发周期两到三年。要提前预判agent需要什么。用一颗芯片同时最优解决训练和推理——这个方程在agentic工作负载面前无解。单一架构必然在某端大幅妥协。
Google的选择很干脆:分家。
TPU 8t:训练怪兽。9600芯片Superpod,121 FP4 ExaFlops,2PB共享HBM,ICI带宽翻倍。全新Virgo网络——高基数扁平拓扑,单fabric支持13.4万+芯片,跨站点百万芯片近线性扩展(JAX+Pathways)。目标goodput(有效计算时间)超过97%。前沿训练动辄数月,每1%的故障重启都是数百万美元的账单。
TPU 8i:Agentic推理引擎。288GB HBM,外加384MB片上SRAM——前代的三倍。这个数字瞄准的方向很明确:在芯片上炸开memory wall。长上下文的KV cache全部塞进片上,延迟直接降维。Boardfly拓扑把最大跳数砍到7(传统3D torus要16跳,减少了56%)。新增CAE(Collectives Acceleration Engine)卸载全局归约和同步操作,片上延迟再降5倍。Axion Arm CPU做主机,双物理CPU/服务器,NUMA隔离。
经济账同样炸:8t训练每美元性能提升2.7倍;8i推理低延迟MoE场景每美元性能提升80%;两者每瓦性能都是Ironwood的两倍。
▲ 维基百科TPU词条:从v1(28nm)到v8t/8i的完整世代演进表,独立第三方数据交叉验证
NVIDIA铁幕下的第一道裂缝
NVIDIA仍然占着AI加速卡约81%的市场。但裂缝已经肉眼可见。
OpenAI预订Google TPU容量——分析师直接把这叫做"NVIDIA铁幕下第一道可见裂缝"。Anthropic、Meta等也开始大规模部署TPU。Google和Broadcom深度合作做ASIC设计,TSMC代工主力计算芯片,同时跟Samsung洽谈未来的内存I/O芯片生产——多源策略正在摊薄供应链风险。
芯片性能对决只是台面上的浪花。水面下真正在打的,是AI算力规则的定义权。
Hyperscaler自研加云开放——Google可以内部让Gemini/Search服务十亿用户,同时给外部Cloud客户提供同一套基础设施的弹性容量。在功率约束越来越紧的当下,这种"既要又要"的底气,来自十年的全栈积累:硅→网络→液冷→数据中心→编译器XLA→框架JAX/PyTorch→运行时Pathways。
▲ Ironwood/v7发布博客:42.5 ExaFlops推理专用TPU,为v8的双芯片拆分直接铺路
真正的护城河不在芯片图纸上
硬件做到极致只是基础。软件栈能不能喂饱它,才是生死的分界线。
TPU 8的软件栈跟硬件同步迭代:JAX+Pathways+XLA近线性扩展到百万芯片;MaxText/Tunix提供参考实现和RL训练支持;Native PyTorch完整支持Eager Mode;vLLM/SGLang推理引擎做针对性优化;Pallas/Mosaic让开发者用Python直写自定义kernel,触达SparseCore和CAE这些新硬件特性——不需要碰一行CUDA。
Bare metal访问,加上GKE深度集成——Inference Gateway预测路由、Rapid Cache、Agent Sandbox——开发者用熟悉的框架,跑Google的规模。
Google持续开源MaxText、JAX、llm-d等项目,要让TPU成为行业可选基础设施,不限于内部秘密武器。
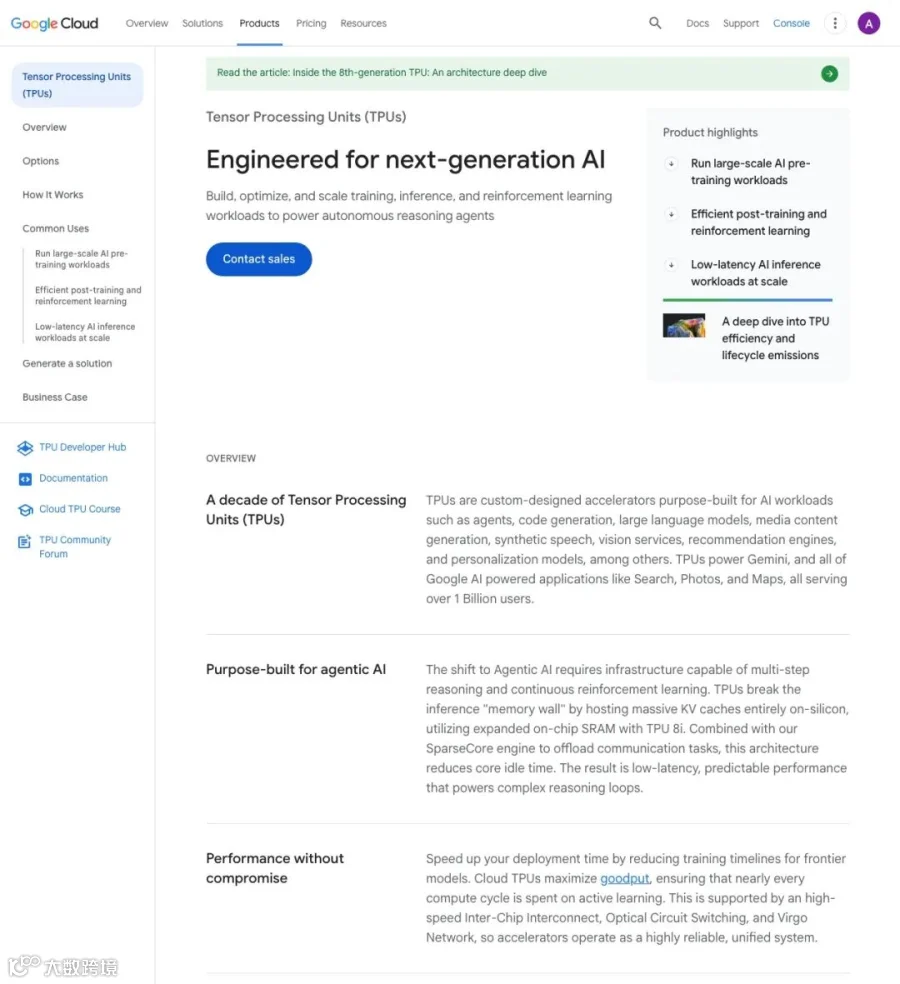
▲ Google Cloud TPU产品页:"为下一代AI而设计……自主推理Agent",强调突破推理memory wall和6倍每度电算力提升
十年下注,赌的是"算力定义权"
回头看这十年,Google做对了一件事:在软件定义一切的时代,有胆量为张量计算造硅基硬件,并且每代都用全栈co-design重新定义上限。
Agentic Era把这件事的价值放大了不止一个数量级。Agent的本质是持续的规划-执行-学习循环、多Agent协作、世界模型模拟——跟单次查询有本质区别。功率墙、内存墙、网络直径墙同时砸过来,只有垂直整合(硅→数据中心→软件→应用)才能在这些约束下持续交付线性扩展和极致goodput。
TPU 8的双芯片拆分,核心逻辑就在这里:不再追求一颗芯片统治所有场景。让训练阶段跑在最匹配吞吐的硅上,让推理阶段跑在最匹配延迟的硅上。
从2015年28nm、几十TOPS的v1,到2026年121 ExaFlops的8t和384MB片上SRAM的8i——十年八代。当初业界笑它"不必要的风险",今天它是Agentic时代的架构基石。
这不止是芯片故事。这是AI时代"谁来制定算力规则"的权力转移。
— END —