
2026 年 6 月 8 日,一条极短的推文在 X 上炸开了锅。
发帖人是 OpenClaw 创建者 Peter Steinberger。话很短,但每一句都像锤子砸在工程师的肌肉记忆上:
"Here's your monthly reminder that you shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents."
「每月提醒一次:你不应该再直接给 coding agent 下 prompt 了。你应该设计循环,让循环去 prompt 你的 agent。」
这条帖子的数据说明了一切:近2000 万浏览,近 2 万人点赞,1.4 万人收藏。
评论区里,一线工程师的反应出奇地一致——几乎没人反驳,清一色是「对,我已经这么干了」。
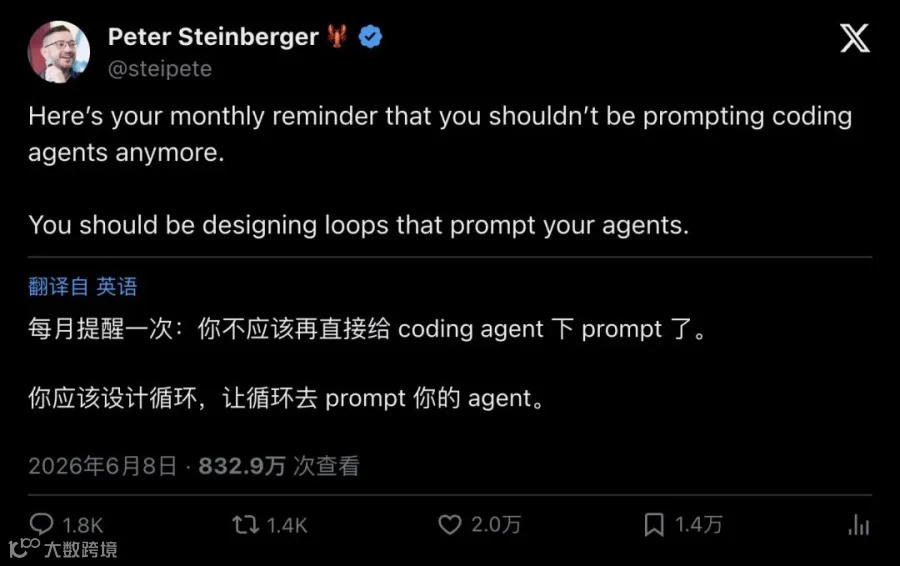
▲ Peter Steinberger 推文:“每月提醒一次——你不该再给 coding agent 写 prompt 了。你应该设计循环,让循环去 prompt 你的 agent。”(近 2000 万浏览,近 2 万点赞)
一、从“聊天框”到“控制系统”:一场静默的范式转移
如果你还在精心构造 prompt、一轮一轮地对着 Claude 或 ChatGPT 打字,那你要注意了——这正是这波变革要淘汰的工作方式。
几天后,安全研究员 @0x0SojalSec 发了一条更直白的总结帖:
"Stop making prompts. Start designing loops. Loop engineering is the new meta."
「别再写 prompt 了。开始设计循环。Loop engineering 正在成为新范式。」
他直接点名 Anthropic Claude Code 负责人 Boris Cherny,并甩出了一张清单——每个有效 AI Agent 循环的 6 个关键组件:
- Automations
(自动化触发器,不需要你手动触发) - Memory files
(STATE.md,跨运行持久化记忆) - Worktrees
(隔离环境,避免 agent 之间互相踩踏) - Skills & sub-agents
(可复用技能 + 子代理分工) - Evaluator-optimizer pattern
(写手 vs 检查者,分离执行与验证) - Hard stop conditions
(硬停止条件,不是 AI 自己说“我做完了”就行)
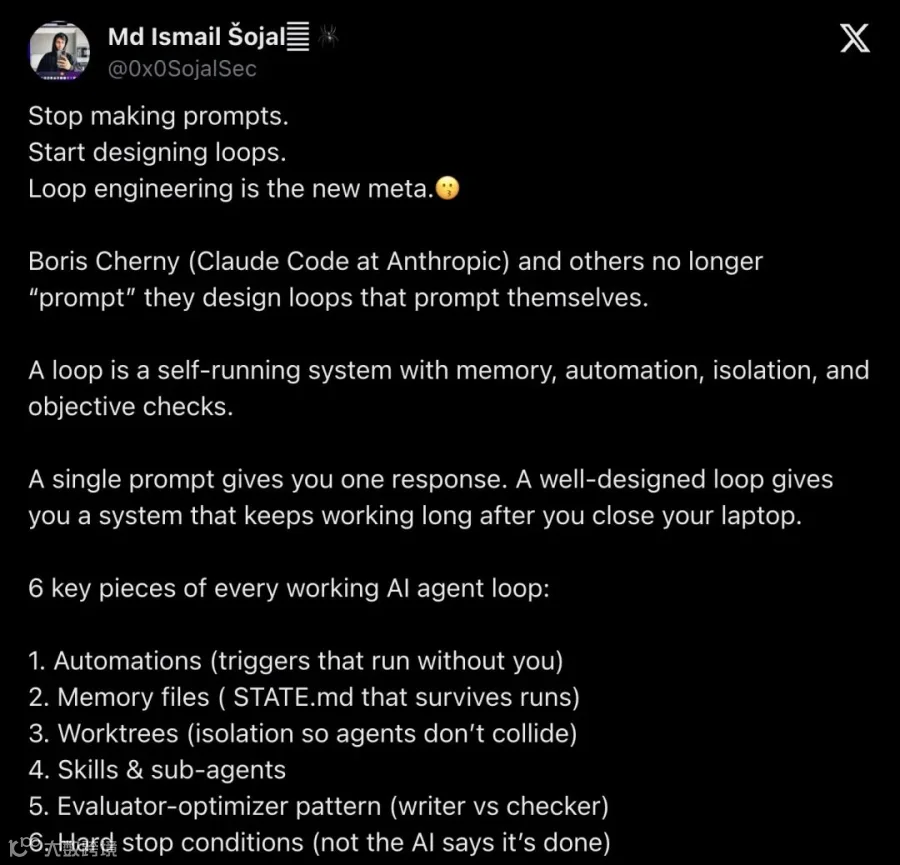


▲ @0x0SojalSec 总结帖,明确提出“Loop engineering is the new meta”并列出 6 个核心构建块
Mike(@mikenevermiss)紧接着发了一篇长文,把这件事讲得很透。他的核心论证直接得令人生畏:
"The agent forgets everything between runs. The loop does not. That single fact is the entire architecture."
「Agent 在每次运行之间会忘记一切。Loop 不会。这 14 个字,就是整个架构的根基。」
这句话不是一个比喻。它是工程事实。
Claude、GPT、Grok——无论哪个模型,每次新的 API 调用都是“失忆”的。上下文窗口再大,也有边界。但 loop 不一样:loop 把进度、决策、状态写进了磁盘文件(STATE.md、CLAUDE.md),每次新运行,agent 先读文件、再干活、再写回。记忆不靠模型,它靠的是文件系统。
这就是旧范式与新范式的根本分界线。
过去两年,你学的是 prompt engineering:怎么措辞、怎么加 few-shot、怎么 chain-of-thought。现在,杠杆点移了。你该学的是怎么设计一个自己发现自己干活、自己验证自己产出的控制循环。
二、拆开看:6 个组件怎么把一个人变成一支军队
别被“6 个组件”吓到。它们各自解决的问题,只要用过 coding agent 超过一周,你都撞过。
1. Automations——心跳
没人手动触发,loop 凭什么自己跑起来?
答案是 cron、GitHub Actions、/loop、hooks。每天早 8 点自动跑一遍 CI 失败分析、昨晚提交摘要、未分类 issue 扫描。你起床时,loop 已经把今天的待办列好了。
这不是“省了 5 分钟”,这是把启动成本降到了零。
2. Memory / STATE.md——脊柱
这是最不起眼、也最关键的一环。
一个典型的 STATE.md 只有三样:上次做了什么、目前在做什么、阻塞在哪里。就这么短。但它让 agent 从“每次从零开始”变成了“接着上次往下干”。
Boris 团队的 CLAUDE.md 更进一步:项目级文件直接放进 git 仓库,任何人在 PR 里 @ 更新规则。他把这叫compounding engineering——规则越写越厚,loop 越跑越稳。
3. Worktrees——隔间
两个 agent 同时改同一个文件,冲突、覆盖、回滚——用过就知道疼。
git worktree add给每个 agent 一个独立 checkout,共享 git 历史但互不干扰。Claude Code 原生支持--worktree和isolation: worktree。
Boris 的真实配置:每天同时开 5 个终端 Claude + 5-10 个 claude.ai 会话,每个跑在独立的 worktree 上。没有隔离,这个规模一秒钟就崩。
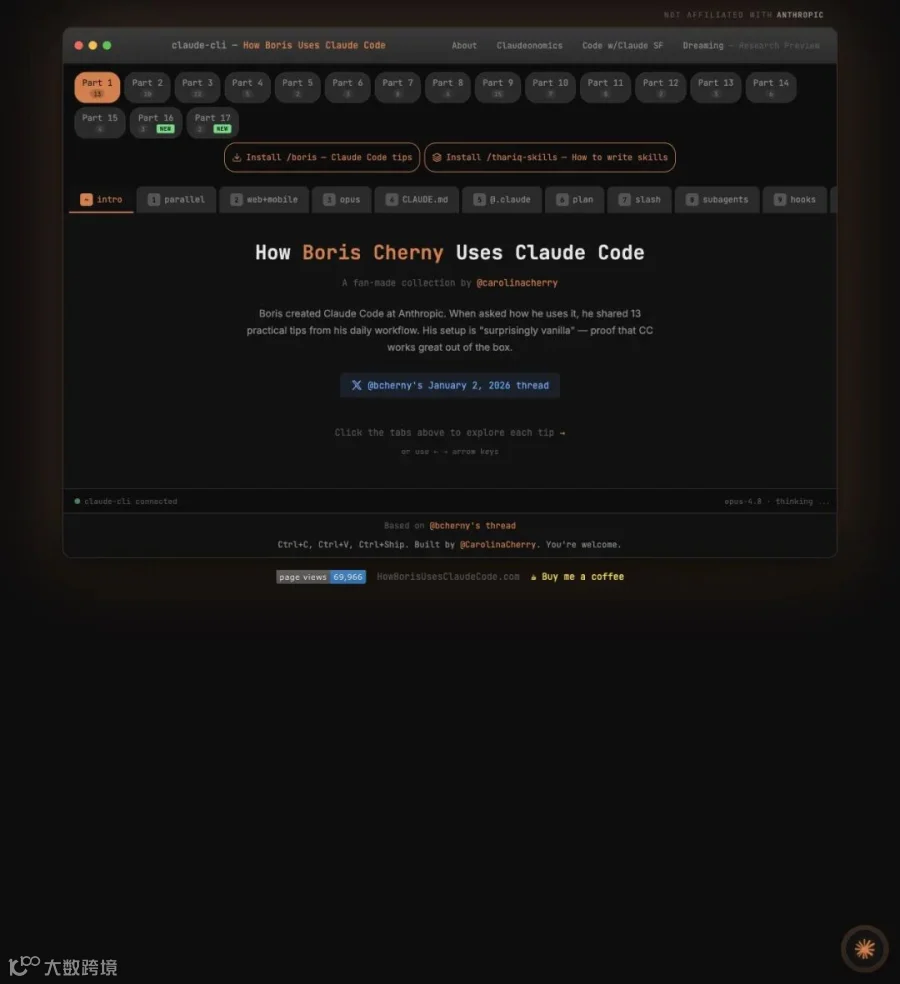
▲ Boris 的真实工作流被粉丝整理成网站(howborisusesclaudecode.com),展示了同时运行 5+ Claude、git worktree 隔离、CLAUDE.md 共享等细节
4. Skills + Sub-agents——可复用的兵种
Skill 就是“写一次、永远复用”的操作手册——一个 SKILL.md 加精炼脚本,遇到同类任务直接调。
Sub-agent 是把大任务拆给不同角色:explorer 负责搜索、implementer 负责写代码、verifier 负责检查。Boris 强烈建议把常见流程写成.claude/agents/*.md,给不同 sub-agent 配独立 worktree。
5. Evaluator-Optimizer——裁判和选手分开
一个 agent 给自己打分?永远太松了。“自己判自己的作业”是所有 AI agent 的软肋。
正确做法:一个 agent 写,另一个独立 agent(甚至不同模型)按客观标准检查——测试全绿、lint 通过、页面在真实浏览器里能点、后端数据库状态正确。失败就回环,直到条件满足。
Boris 在自己的推文里把这一点提到了最高优先级:
"We talk a lot about how important it is to set up self-verification loops... self-verification is a key ingredient that enables the model to run for much longer, delivering a result that is closer to what you intended."
「我们反复讨论设置自我验证循环有多重要……自我验证是让模型跑得更久、产出更接近你意图的关键配料。」
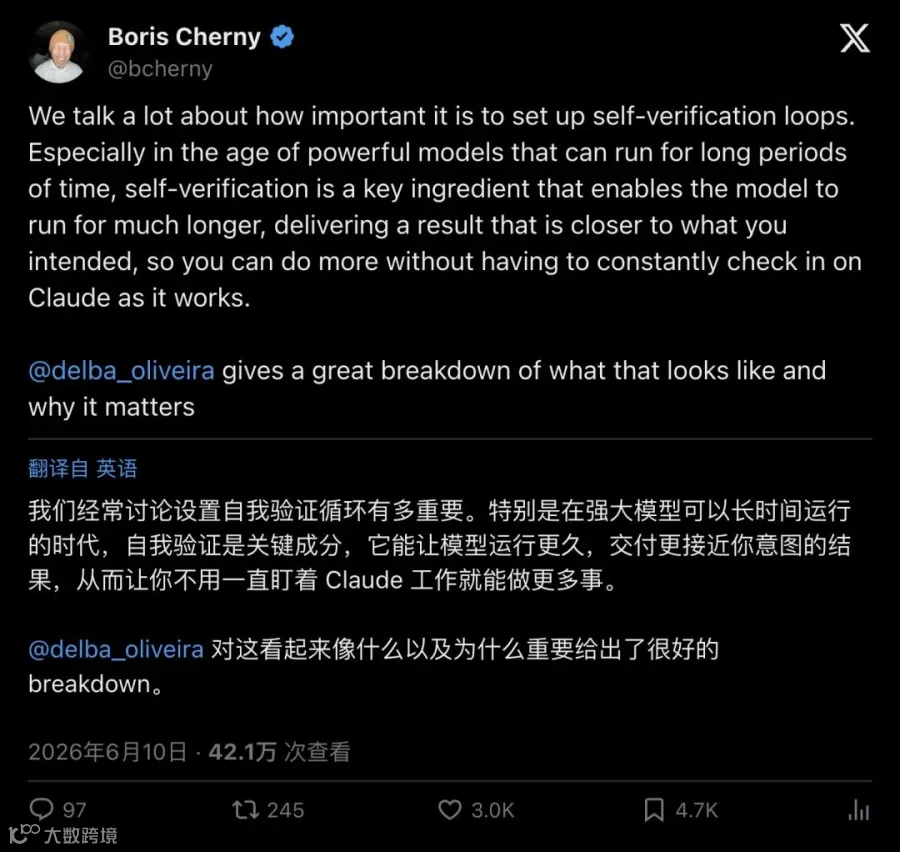
▲ Boris Cherny 本人推文,强调自我验证循环是长时间自主运行的关键
6. Hard Stop Conditions——铁门
社区里出现了一个著名的反模式,叫Ralph Wiggum loop(由 Geoffrey Huntley 命名):agent 还没干完就说“完成了”,loop 就退出了。跟动画片里 Ralph 那句经典台词一样——“I'm helping!”
停止条件不能靠 AI 自己说“完成了”。你得给它可验证的外部事实:npm test全绿、Linear ticket 移到 Done 且 CI 通过、页面交互正常。再加一个最大迭代次数做最后一道保险。
三、Addy Osmani:给这个新范式正式命名的人
Google 工程师 Addy Osmani 在 6 月 7 日发了一篇博客,标题就是「Loop Engineering」。
这是在社区话语被 Boris 和 Peter 的推文搅热之后,第一次有人用工程文档的精度把这件事拆干净。
他的核心观点只有一行表,但这一行表比任何煽动性推文都更有杀伤力:他把 Codex 和 Claude Code 的实现一一对齐,证明“loop shape 正在变得工具无关”——
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

▲ Addy Osmani 的系统框架对比,证明 loop 原语正在跨平台标准化
但 Addy 真正厉害的地方不在于这张表。他在博客里写了四句让行家坐不住的话:
- “Verification is still on you.”
——验证还是你的事。loop 跑得再顺,你得看懂它产出。 - “Comprehension debt grows faster.”
——理解债务比技术债务涨得快。代码不是你写的,但你得能改。 - “Cognitive surrender is the comfortable trap.”
——认知投降是最舒服的陷阱。“按下 go 就行”的姿势,也是最危险的。 - “Two people can build the exact same loop and get completely opposite results.”
——两个人搭出一模一样的 loop,结果可以完全相反。loop 不分好坏,是你分。
整篇博客真正的落点在最后一句:
"Build the loop. But build it like someone who intends to stay the engineer, not just the person who presses go."
「去搭你的 loop。但你搭它的姿势,得是一个还想继续当工程师的人——不是那个只会按开始键的人。」
四、GitHub 上已经能 clone 了:Cobus 把 loop 做成了开源基础设施
理论讲到这里,有人会问:我现在能上手吗?
能。
南非工程师 Cobus Greyling 在 GitHub 上建了一个仓库——cobusgreyling/loop-engineering——它直接就是生产级模板:
-
三个 CLI 工具: loop-init(一键初始化)、loop-audit(成本审计)、loop-cost(精确计价) -
7 个可直接 clone 的 loop 模式:daily-triage(每日分类)、PR-babysitter(PR 保姆)、CI-sweeper(CI 扫雷)、changelog-drafter(变更日志起草)…… -
每个模板自带 STATE.md、AGENTS.md、skills/ 目录 -
明确分了三级:L1(只报告不动手)、L2(辅助修复)、L3(无人值守)
▲ cobusgreyling/loop-engineering:开源的生产级 loop 模式仓库,提供 CLI 工具、STATE.md 模板和三级自主度阶梯
更有意思的是,Cobus 把 Grok、Claude Code、Codex 的对应能力做了完整映射——结论是,loop 的形态正在变得工具无关。你换平台只用换底层指令,loop 的结构不变。
这会催生什么?一个跨平台的 loop 市场。你卖的东西不再是代码本身,而是 loop 设计。就像过去卖 SaaS 模板、卖 DevOps pipeline——loop 正在变成可交易的生产力资产。
五、跑 loop 的代价:Boris 的诚实
但话不能说一半。
所有认真讨论 loop engineering 的人,都在同一处刹车:这不轻松,也不便宜。
Boris 自己承认,一个设计不当的 loop 跑一夜就是巨额 token 账单。Mike 的建议很实操:先手动跑 3-5 次测单次成本,再乘以迭代上限,看一眼总价再决定要不要放它通宵。
钱只是第一道槛。真正会出事的是人。
Addy 警告了一圈:loop 跑得越顺,你越容易不看它产出的代码。这叫 comprehension debt——理解债务。代码不是你一行一行写的,但线上出了 bug,你要负责。你不会读的代码,跟你的资产没有关系——它就是定时炸弹。
认知投降(Cognitive Surrender)是所有陷阱里最深的一个:你搭了一个完美的 loop,每天按 go,看它跑、看它绿、看它合。三个月后有人问你这套系统为什么这样设计,你只能说“loop 定的”。那一刻,你不是工程师了。你是 loop 的操作员。
Boris 自己也说了一句很有信息量的话:loops 是“他们十年后仍然最骄傲的功能”——这句话的另一面是,现在还远远没到终态。共享内存怎么搞、质量怎么追踪、停止条件怎么跟真实业务结果绑定——这些全是前沿难题。
六、它到底是什么,比它叫什么更重要
Loop engineering 这个叫法,是社区在 6 月这波集中讨论里自然凝结出来的。但名称不重要。重要的是你从它里面看到了什么。
你看到的是“更高级的 prompt 技巧”,那你还在旧范式里。
你看到的是一个控制系统——有信号输入(automations)、有状态存储(memory files)、有并行隔离(worktrees)、有分工协作(skills + sub-agents)、有反馈校正(evaluator-optimizer)、有边界条件(hard stop)——那你已经在用新范式思考了。
Peter Steinberger 说的「杠杆点已经移动」就是这个意思。你以前花 90% 时间写 prompt,10% 时间看结果。现在你把 prompt 外包给 loop,花 90% 时间设计系统、定义验证门、review 输出、更新记忆文件。
你不再是打字的人。你是设计打字系统的人。
Boris Cherny 亲口证实,他的日常工作已经从“坐在聊天框前”变成了:设计心跳、维护 STATE.md、调整隔离策略、写好验证规则,然后 review loop 吐出来的东西。
这解释了为什么有些工程师用 AI 越用越快,有些人越用越迷茫。工具都一样。真正拉开差距的,是你把自己放在系统的哪一层。