
2026年6月17日凌晨,一条来自第三方评测机构Artificial Analysis的推文,把开源AI圈炸醒了。
Z.ai(智谱)的GLM-5.2,在Artificial Analysis Intelligence Index v4.1上拿下51分,一举登顶开源权重模型榜首。MiniMax-M3 44分,DeepSeek V4 Pro 44分,Kimi K2.6 43分——全被甩在身后。
更狠的是,GLM-5.2的总参数(744B)和激活参数(40B)跟上一代GLM-5.1一模一样。架构没变,参数没加,单纯靠后训练和系统优化,分数硬生生从40跳到51,涨了11分。

▲ Artificial Analysis官方文章宣布GLM-5.2登顶,标题直呼"the new leading open weights model"
同一时间,Z.ai官方推文宣布开源,MIT许可证,权重即刻可下载。500万+阅读,1万+点赞。开发者在评论区直接喊出"You are my heroes"。

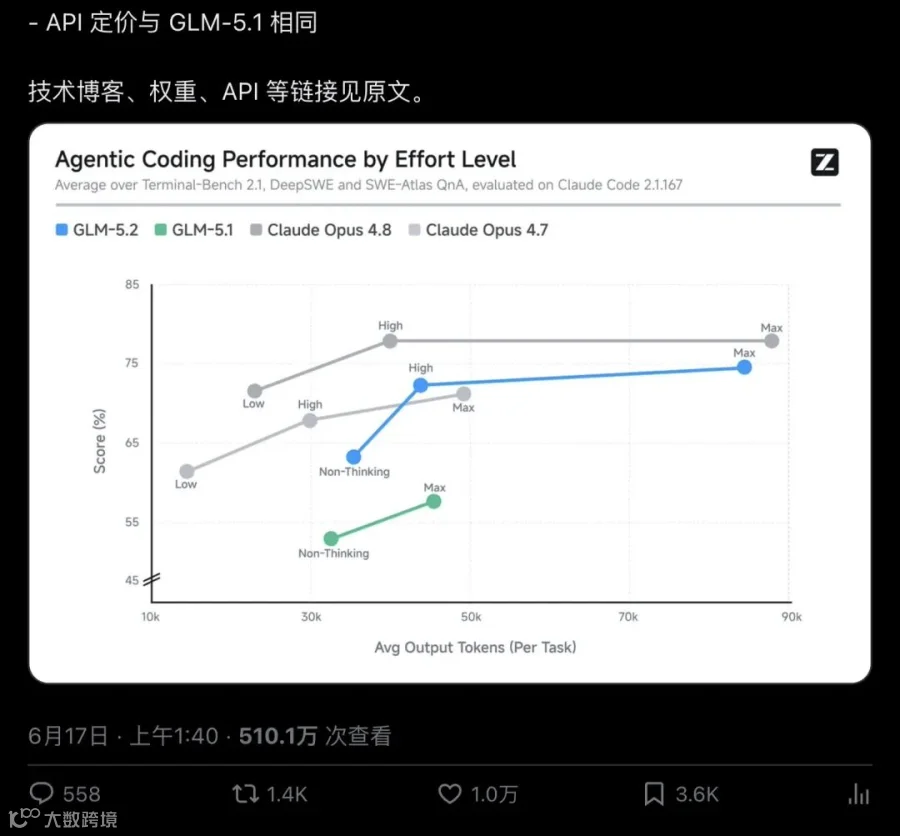
▲ Z.ai官方发布帖,强调"Frontier Intelligence, Open Weights",MIT许可、1M上下文、API定价不变
51分到底什么水平?榜单说了算
Artificial Analysis的榜单不是野榜。它是目前独立第三方评测里最硬核的之一,v4.1版本专门转向真实世界Agentic工作负载的评估。
在总榜上,GLM-5.2(max模式)排在开源权重第一,甚至逼近一些闭源专有模型的区间。
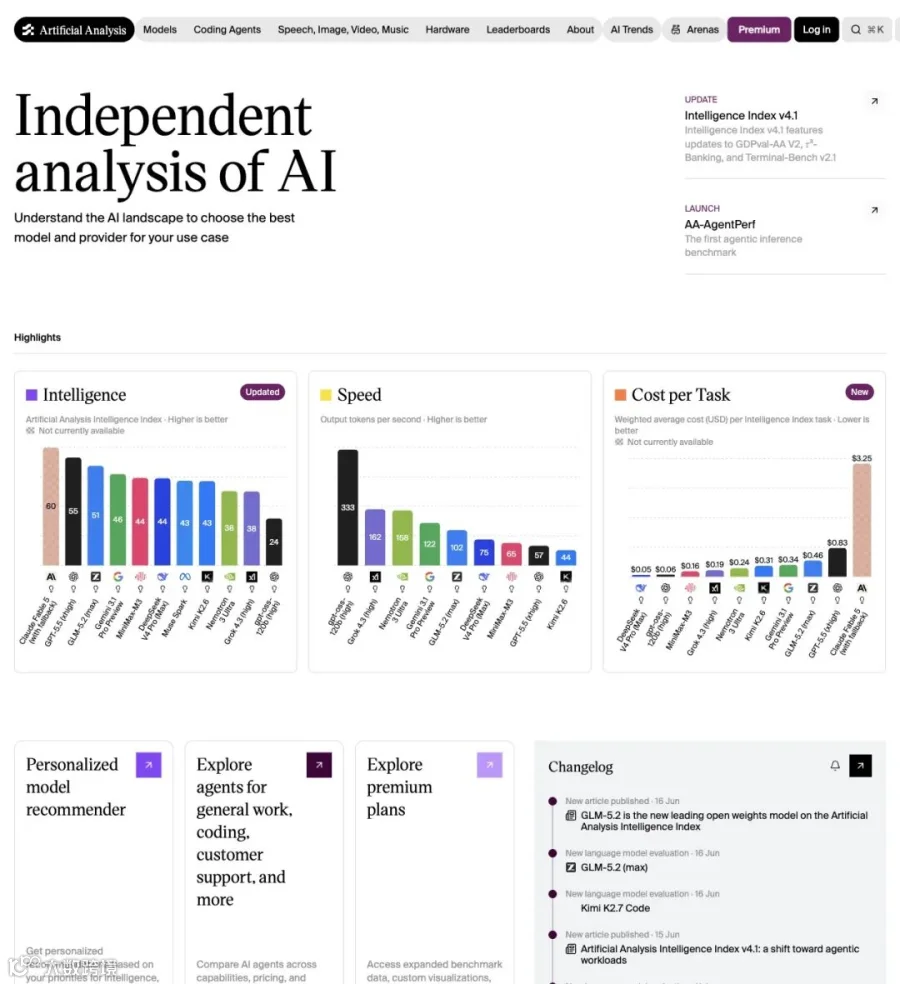
▲ AA主页榜单,GLM-5.2 (max)在开源权重中排名第一,紧逼闭源阵营
具体维度看看这11分是怎么涨出来的:
- CritPt(物理/批判性推理)
:从5%跳到21%,涨了16个百分点 - HLE(Humanity's Last Exam)
:从28%升到40%,涨了12个点 - AA-LCR(长上下文推理)
:从62%拉到71% - TerminalBench v2.1
:从62%冲到78%,涨了16个点 - τ³-Banking(银行工具使用Agent)
:从12%翻到27% - GPQA Diamond
:从86%爬到89%
七个维度都在涨。某一个benchmark飘了可以归给运气,七个维度同时往上拉,底层能力确实不一样了。
最让人坐不住的,是GDPval-AA v2这个指标。它是AA专门用来衡量真实世界Agentic执行能力的核心测试——让模型完成有实际产出的工程任务,然后人工目视检查输出质量。
GLM-5.2在这项上拿到1524分,压过MiniMax-M3的1418和DeepSeek的1328,直接追平了GPT-5.5 (xhigh模式) 的1514分。
AA在文章里特别强调了这点:"We visually inspected GLM-5.2's outputs across a range of GDPval-AA tasks"——所有GDPval任务输出都经过了人工目视检查,得分后面站着真实的工程产出。

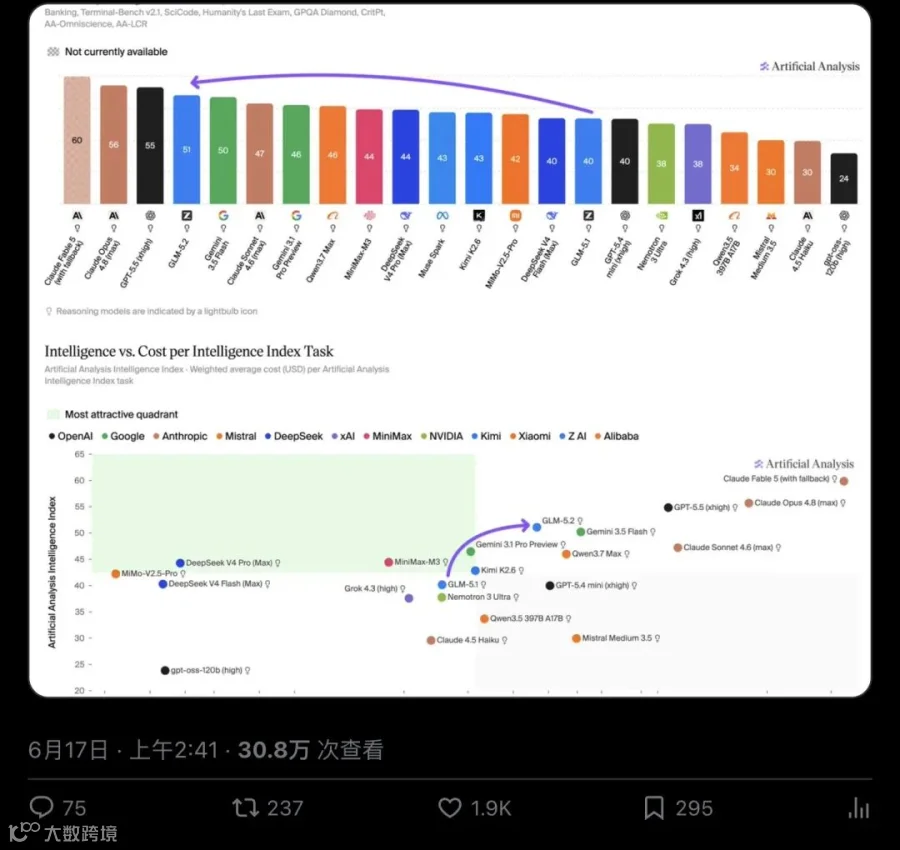
▲ AA发布的数据对比图,GLM-5.2在GDPval-AA v2上领先所有开源模型,基本持平GPT-5.5
同样的744B,凭什么多出11分?
Z.ai的博客标题起得很直白:"GLM-5.2: Built for Long-Horizon Tasks"。
核心逻辑不是堆参数。是把1M上下文真正用起来。
博客里有一句很关键的话:"A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure." 宣称支持100万token上下文不难,难的是在实际工程压力下保持可靠。
GLM-5.2在Coding Agent场景下了苦功。数月专项训练,针对长时程任务(大规模实现、自动化研究、性能优化、复杂调试)做了强化学习。
效果怎么样?看几个长时程benchmark:
- FrontierSWE
:74.4分,仅次于Opus 4.8的75.1,压过GPT-5.5的72.6 - PostTrainBench
:34.3分,碾压GPT-5.5的28.4 - SWE-Marathon
:13.0分,与Opus系列属同一梯队
一个真实案例:开发者在X上晒出用GLM-5.2一次性完成物理模拟项目(泳池破裂、高尔顿板),代码量极大、细节丰富,单次任务消耗85万token,几乎打满1M窗口。
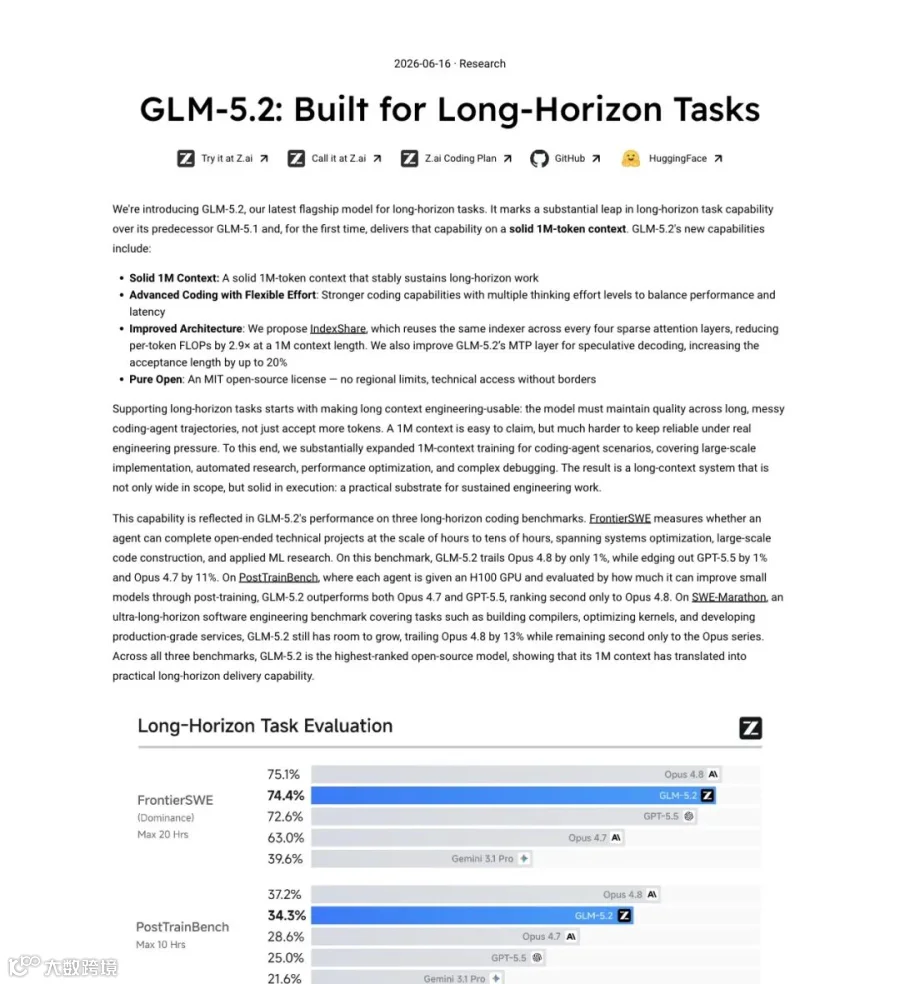
▲ 官方博客详细拆解了Solid 1M上下文、Effort控制、IndexShare架构、MIT纯开源四大核心能力
架构层面,有三板斧在撑:
IndexShare。每4层共享一个轻量indexer,1M上下文下per-token FLOPs降低2.9倍。简单说就是计算量砍了三分之二,长文本不再烧算力。
MTP改进(投机解码)。接受长度提升20%,结合拒绝采样和端到端TV损失,推理更快更稳。
slime框架。Z.ai自研的强化学习基础设施,支持白盒/黑盒rollout和子代理工作流。整个OPD训练只用了大约2天。
还有一个叫Anti-hack模块的设计值得一提:训练中自动检测并阻断模型"作弊"(比如用curl偷看答案、读eval secret),同时允许rollout继续跑,避免训练崩溃。
这些合在一起,回答了一个问题:相同硬件footprint下,智能能不能继续涨?GLM-5.2的答案是能,而且涨了不少。
性价比这一刀,切在哪?
GLM-5.2的API定价跟GLM-5.1完全持平:每百万token输入$1.4、输出$4.4、缓存命中$0.26。
在这个价格点上,AA的Intelligence vs Cost per Task图表说了实话:在同等智商水平下,GLM-5.2是成本最低的模型。它正好坐在"帕累托前沿"上。
▲ Hugging Face上可直接下载权重,MIT许可证允许商用、无地域限制
重点对比一下:
-
GLM-5.2单任务成本约$0.46,产出43k token(其中37k推理token) -
MiniMax-M3单任务$0.18,但只产24k token -
DeepSeek单任务$0.05,产出更少
贵,确实比便宜的对手贵。但43k token的输出量——是MiniMax的近两倍。长时程任务里,模型多思考和验证,最终产出质量更高。VentureBeat的标题点破了这件事:"Beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost."
六分之一的价格,追平甚至局部超越GPT-5.5的长时程编码能力。
开源权重意味着什么?意味着你可以自托管。vLLM、SGLang、Transformers、KTransformers、Ascend NPU全部支持。同时,DeepInfra、Novita、Nebius、Parasail、SiliconFlow、Fireworks、Cloudflare Workers AI等十几家推理服务商在发布当天就上线了。
不是只能走官方API一条路。想怎么用就怎么用。

▲ 中文文档推荐的实战场景:项目级工程接管、长程重构、移动端真机调试、科研复刻
质疑有没有?有
这么大的参数体量,744B全量加载到内存就是一道坎。社区有开发者直接吐槽:"40b active looks cheap until 744b total starts hurting memory and cold starts."
翻译过来:激活参数看着只有40B,轻飘飘的,但744B总参数塞进内存的那一刻,冷启动时间才是真正的痛。
AA的Intelligence Scoring Methodology v4.1升级也引发了一些讨论。新版本引入了更多agentic指标和新的judge方式,导致部分老模型相对分数发生了变化。有人在评论区说"This jump is impressive but... your scoring system is severely flawed"。
输出token量大也是双刃剑。GLM-5.2平均单任务产43k token,长了确实靠谱,但也意味着每次调用都在烧钱。好在官方提供了两个推理强度档位:max模式全力冲,high模式在性能和token效率之间取平衡。
还有一个客观限制:GLM-5.2是纯文本模型,不支持图像输入。多模态场景暂时无缘。
这件事为什么值得认真看
GLM-5.2这个发布,不是在刷榜。
同一个架构,同一种尺寸,后训练加上基础设施优化,把一个已经很强的模型又往上推了11分。这件事告诉行业一个信号:参数规模的军备竞赛告一段落了,下一阶段的战场在数据质量、训练方法和系统工程。
更重要的信号是开源。MIT许可证、权重立刻可下载、十几家平台同时上——Z.ai在把"前沿智能"从小部分人的特权变成基础设施。Filecoin和io.net的官方账号都在评论区表示要接入去中心化计算。
中文媒体量子位的报道标题直接给到了"Fable-5之下,开源第一"的评价,把Claude、OpenAI、智谱并称为AI编程的"全球御三家"。
▲ 量子位报道称GLM-5.2在Fable-5之下,开源模型第一,"全球御三家"格局形成
对开发者来说,多了一个强力、便宜、可本地部署的Coding Agent选项。对行业来说,中国实验室的迭代速度和开放姿态,给全球开源生态打了强心针。对用户来说,GPT-5.5级别的编码能力,六分之一的价格,这件事本身就足够震动。
有人问下一个会不会是1T参数?
也许参数会更大,也许同尺寸还会继续涨分。GLM-5.2用实际结果告诉你:架构不变的情况下,智能的上涨空间远没有见顶。