
2026年6月16日,Arena官方放出一组前端编程盲测榜单,GLM-5.2(Max)空降WebDev赛道第2,仅次于一款已被官方下线的实验系统。AI测评专家Angelopoulos随即发帖定性:去掉那个不可用的模型,GLM-5.2就是前端Coding世界第一。开源模型在实战Agent编程赛道上,已经和顶级闭源模型进入同一讨论区间。六分之一的成本,MIT开源可自托管,753B参数,1M上下文——跟论文里报"单项领先"不同,这次是社区盲评、真人打分淬出来的硬结果。
凌晨一条帖,改写了一个赛道的座次
北京时间6月17日凌晨,X平台上一条帖子正在以每小时数万次的速度扩散。
发帖人是Anastasios Nikolas Angelopoulos,Arena测评专家,伯克利出身,前Google DeepMind背景。他平时发帖风格克制,很少用惊叹号。
这一次,他用了"huge moment"。
"Just to be clear, if you remove Fable which is unavailable, GLM-5.2 (Max) is the #1 model in the world for frontend coding."
「明确说一下:去掉Fable(它不可用),GLM-5.2(Max)就是世界前端编程第一模型。这是一个巨大的时刻,开源模型在这个重要领域追平了专有模型。」
帖子的45条回复里,欢呼和质疑掺在一起。但数据本身没有任何含糊。
引爆这一切的,是Arena官方在同天稍早发布的Leaderboard更新。
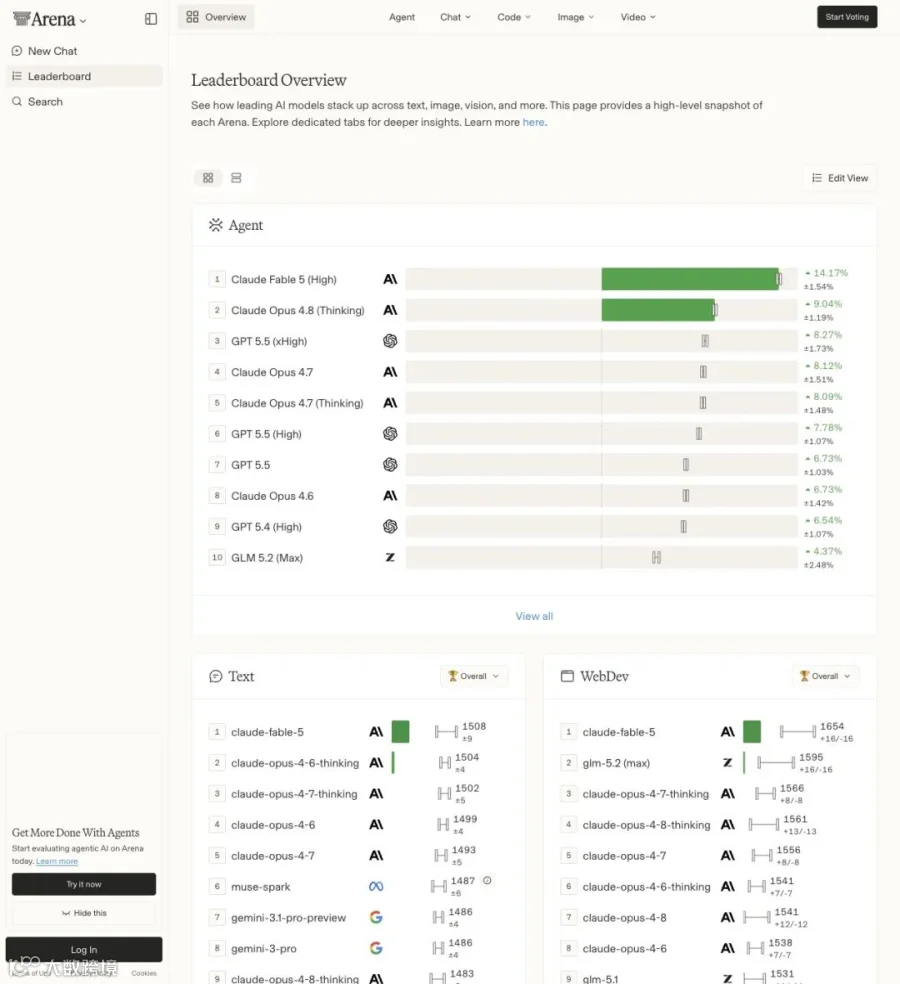
Arena(前LMSYS Chatbot Arena,现arena.ai)是全球开发者社区最看重的盲测平台之一。它的Code Arena: Frontend赛道(WebDev)让模型直接面对真实用户prompt,生成完整HTML/React网站、品牌页面、数据仪表盘、甚至3D游戏,由人类盲评打分,计算Elo排名。这跟开发者每天用Cursor、Claude Code写前端的场景高度一致——正因如此,WebDev榜单被圈内视为"实用前端编程能力"的风向标。
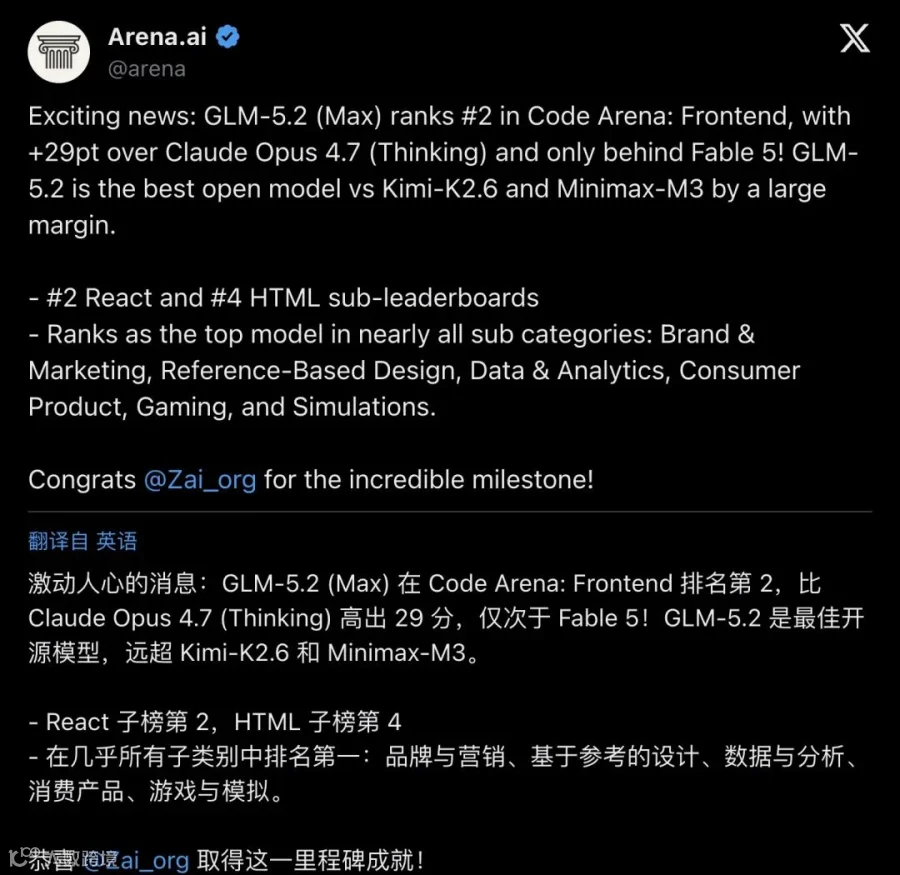
▲ Arena官方帖宣布GLM-5.2(Max)在Code Arena: Frontend排名第2,领先Claude Opus 4.7 Thinking 29分,"最佳开源模型"
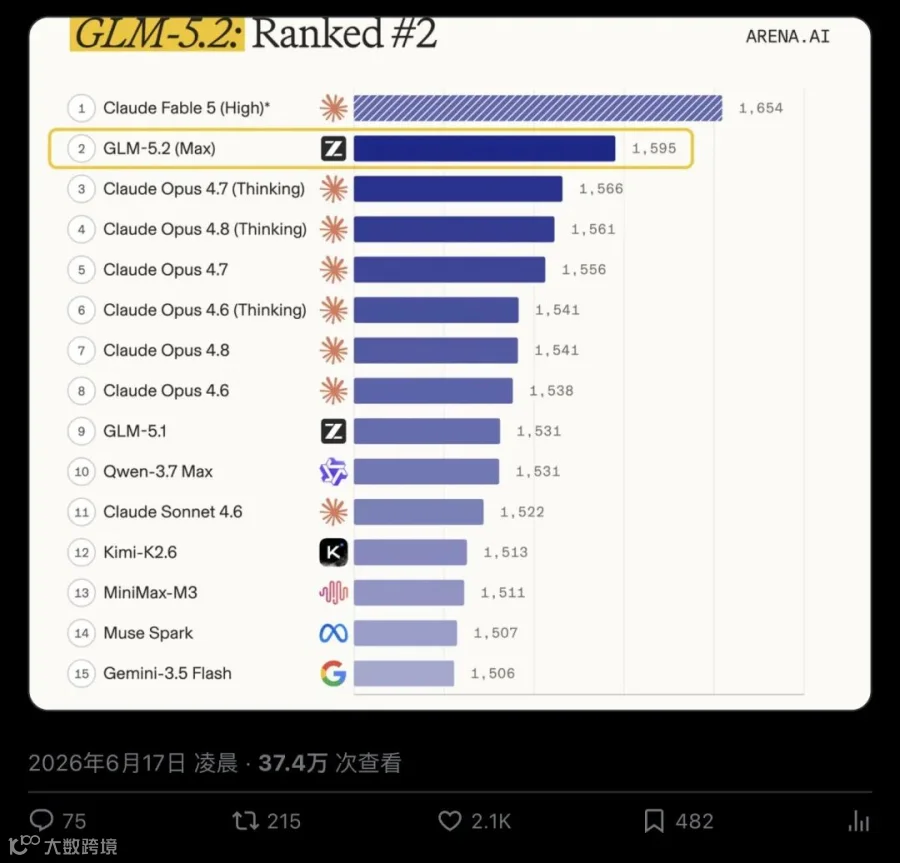
在这份榜单上,GLM-5.2(Max)以1595分高居第2,领先Claude Opus 4.7 Thinking整整29分,仅次于1654分的Fable 5。
Fable 5是什么?一款实验性集成系统,彼时已被Arena官方标注为不可用。榜单上真正可用、可接入、可下载的模型里,GLM-5.2排名第一。
▲ Arena WebDev实时榜单:GLM-5.2(Max)1595分,仅次于已不可用的Fable 5,大幅甩开所有其他开源模型
不只总榜。React子榜第2、HTML子榜第4。Brand & Marketing、Reference-Based Design、Data & Analytics、Consumer Product、Gaming、Simulations——几乎所有子类别里,GLM-5.2都是第一(Fable之外)。
其他开源模型呢?Kimi-K2.6、Minimax-M3、Qwen——全部被拉开了一个身位以上。
753B参数,MIT开源,成本只有竞品的六分之一
6月16日当天,Z.ai(前智谱AI)官方同步放出了GLM-5.2的完整发布。博客、权重、API、GitHub、HuggingFace,全套上线。
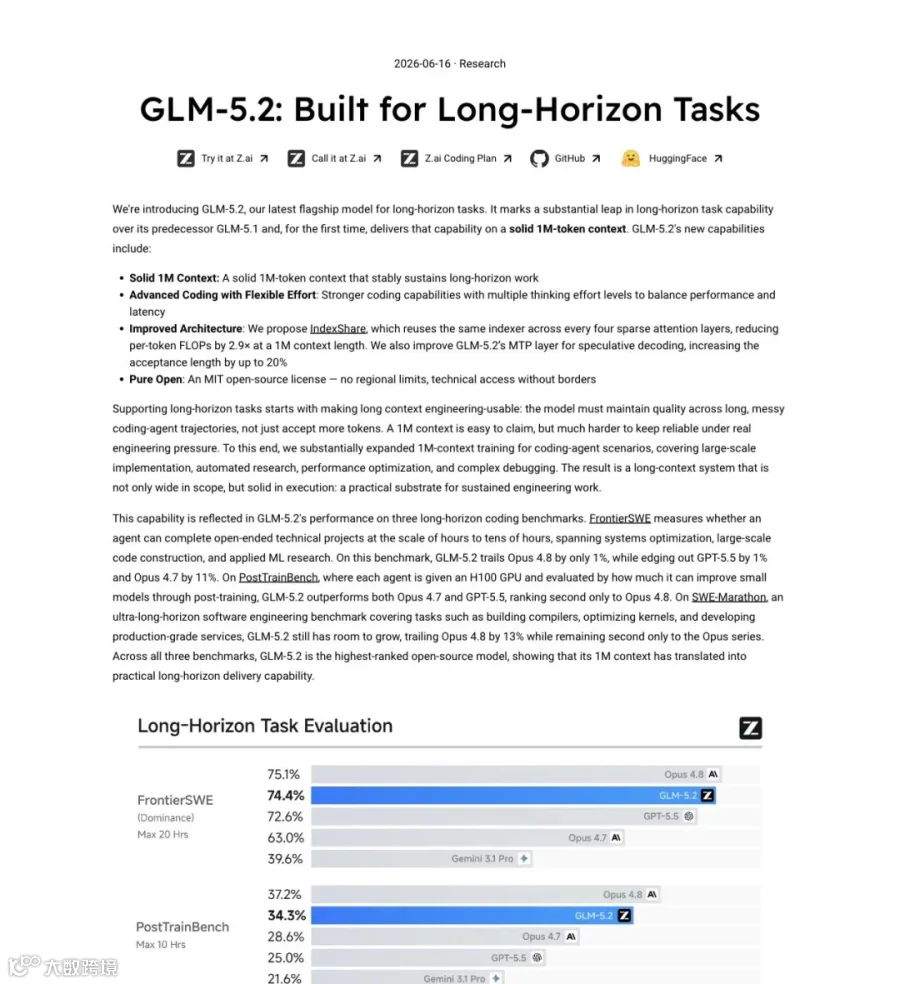
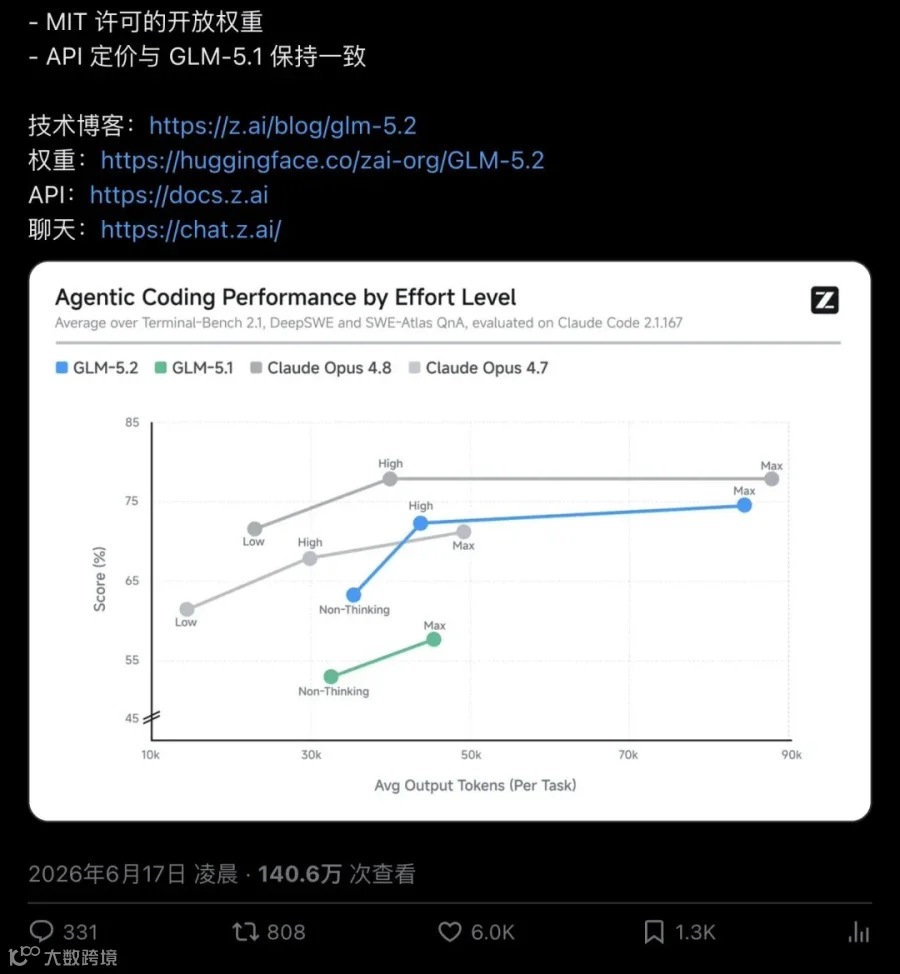
▲ Z.ai官方博客:强调"固实1M上下文"与长时程任务能力,FrontierSWE 74.4%紧贴Opus 4.8的75.1%
几个硬指标:
744B/753B参数MoE架构,约40B激活参数。继承GLM-5的稀疏注意力(DSA),核心强化长时程Agent编程。
固实1M上下文。Z.ai在博客里特意强调这是"solid 1M-token context window, stably sustaining long-horizon work"——不止是"支持",而是针对Coding Agent动辄数百次工具调用、跨数小时的任务轨迹做了专训,撑得住。
IndexShare稀疏注意力:每4层共享一个indexer,1M上下文下per-token FLOPs降低2.9倍。长上下文推理更省算力、更快。
Anti-Hack奖励机制:为了防止模型在Coding强化学习过程中作弊——比如偷偷读评测脚本答案、curl GitHub上的参考答案——Z.ai专门内置了anti-hack模块。benchmark分数的含金量因此更可信。
MTP层优化:投机解码接受长度提升20%。slime框架:两天内合并十余个专家模型,Agent RL迭代大幅加速。

▲ Z.ai官方发布卡:MIT协议、1M上下文、灵活推理强度控制,6030赞,140万浏览
更狠的是授权:MIT许可证。权重免费下载,可商用、可微调、可自托管。"No regional limits, technical access without borders"——Z.ai原话。
再看定价。API延续GLM-5.1的价格:输入$1.40/M tokens,输出$4.40/M tokens。拉一张对比表:
-
Claude Opus:约$30/M tokens -
Fable 5:约$60/M tokens -
GPT-5.5:约$35/M tokens - GLM-5.2:约$5.80/M tokens
VentureBeat的报道标题直接写了:"beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost"——六分之一的成本,多项长时程基准上反超GPT-5.5。
那些每年花几千万美元买Claude Code API的企业,现在多了一个重新算账的理由。

▲ VentureBeat独立报道:GLM-5.2以六分之一成本,在多项长时程编程基准上击败GPT-5.5
多个独立基准交叉验证,不是孤证
单一榜单容易有偏差。GLM-5.2这次在多个独立评测体系里同时站住了:
- Terminal-Bench 2.1
:81.0(GLM-5.1只有63.5,Opus 4.8为85,GPT-5.5为84) - FrontierSWE(长时程)
:74.4%(Opus 4.8 75.1%,GPT-5.5 72.6%)——差距不到1个百分点 - SWE-bench Pro
:62.1(前代58.4,GPT-5.5 58.6) - PostTrainBench
:34.3%,开源第一 - SWE-Marathon、DeepSWE、ProgramBench、MCP-Atlas
:全部开源第一
Terminal-Bench从63.5跳到81.0,说明了过去一年在长上下文Agent可靠性上的工程跃迁。FrontierSWE 74.4%距离Opus 4.8的75.1%只差0.7个百分点,统计上几乎可以忽略。SWE-bench Pro 62.1反超GPT-5.5。
社区反应同样猛烈。Z.ai的官方帖24小时内拿下6030赞、140万浏览。Cline、Kilo Code、Eigent AI等开发工具当天宣布集成。有开发者拿它跑3D游戏、Remotion视频生成、合同审查PRD,反馈"惊艳""稳定性有提升"。
争议:Fable下线了,"第一"到底算不算?
热度上来了,质疑也到位了。
Fable移除逻辑站得住吗?反对者说:榜上有个比你分高的,你一句"它不可用"就把金牌摘了,那谁都能这么玩。Angelopoulos的回应逻辑更直接:Fable本就是一个实验性集成系统,既不是单一模型,也已经被官方下线。榜单要反映的,是开发者今天能实际用到的东西。
bench好不等于实操好。部分开发者反馈Max effort模式下token消耗大、延迟偏高。长上下文稳定性虽有进步,KV cache和推理优化仍是工程硬茬。不过这是所有长上下文模型的通病,GLM-5.2没有更差。
模式对齐是否公平?GLM-5.2用Max模式参赛,其他模型用的Default还是Thinking?Arena机制是用户自选模式参与盲评,避免了平台方主观干预,但模式对齐并非完美。这是一个真实的技术讨论,不是泼脏水。
这些争论本身就在传递一个信号:GLM-5.2的成绩经住了社区多角度审视。讨论焦点已经从"数据有没有水分"移到了"它到底领先多少"。
更大的故事:中国开源在Agent编程上的一次结构性追赶
退一步看,这件事的份量远超一家公司的PR。
过去两年,中国AI实验室的主旋律是"跟跑":参数规模追上了,实用场景还有差距;单榜刷上来了,综合体验还差一截。GLM-5.2这次突破的特别之处在于——它在一个高度工程化、高度偏好驱动、和开发者日常一一对应的赛道上,实现了可复现的领先。
前端编程Agent是目前AI编程商业化最成熟的赛道之一。Cursor、Claude Code、Copilot的核心使用场景就是前端开发。在这个赛道上站到第一梯队,商业价值和技术价值同时兑现。
MIT开源、六分之一成本、可自托管——这三件事叠在一起,对企业的吸引力是结构性的。尤其是在部分模型访问受限、价格高企的背景下,可控、可部署、有备选已经从加分项变成了刚性需求。
工具链生态的配合速度同样值得注意。Cline和Kilo Code在模型发布当天就完成集成。Z.ai主动兼容Anthropic API协议,迁移门槛很低。中国团队不再只是"出模型",而是在围绕开发者工作流做全套交付。
竞争远没结束。Qwen、DeepSeek、Kimi都在快速迭代。西方闭源阵营的latent reasoning等新范式也蓄势待发。GLM-5.2的优势窗口不会很长。
但2026年6月16日这一天会被记住。一个开源模型,在一个全球开发者每天都在用的实战赛道上,让"世界第一"有了可讨论的数据支撑。这些数据来自社区盲评、真人打分、真金淬火后的硬结果——跟PPT里喊"全面超越"、论文里挑子任务报喜是两回事。
— END —