
2026年6月中旬,一段不到一分钟的视频在X上被反复转发、截图、拆解。
Lisa Su站在舞台上,单手举起一台巴掌大的黑色主机。没有机架,没有云服务器,没有GPU阵列。她说这台设备能本地运行2000亿参数以上的AI模型。
然后她把它接通了。
屏幕上的token开始跳动。全场安静了一瞬。
"This is the smallest AI development system in the world. Capable of running models with up to 200 billion parameters locally."
「这是世界上最小的AI开发系统。能够在本地运行高达2000亿参数的模型。」

▲ Lisa Su演示视频被多次剪辑转发。原始片段仅50秒,信息密度极高
一次演示,掀翻了一个定价体系
先算一笔账。
ChatGPT Pro每月200。Claude Code Max再200。Cursor 20,Gemini 20。如果你把这些AI工具认认真真用到工作里,一年下来5280美元。折合人民币将近四万。
而这台Lisa Su手里的“午餐盒”,整机一次性成本约2000到4000美元。没有月费,没有API账单,数据不出本地。
上面的算术最早来自@Shruti_0810的原始推文。她把问题问得十分直白:
"ChatGPT Pro + Claude + Cursor + Gemini? That's $5,280 every year. For the first time, owning AI is cheaper than renting it."
「ChatGPT Pro + Claude + Cursor + Gemini?加起来一年5280美元。历史上第一次,拥有AI比租用AI便宜。」
这个结论有多大的水分?先拆开硬件的底牌来看。
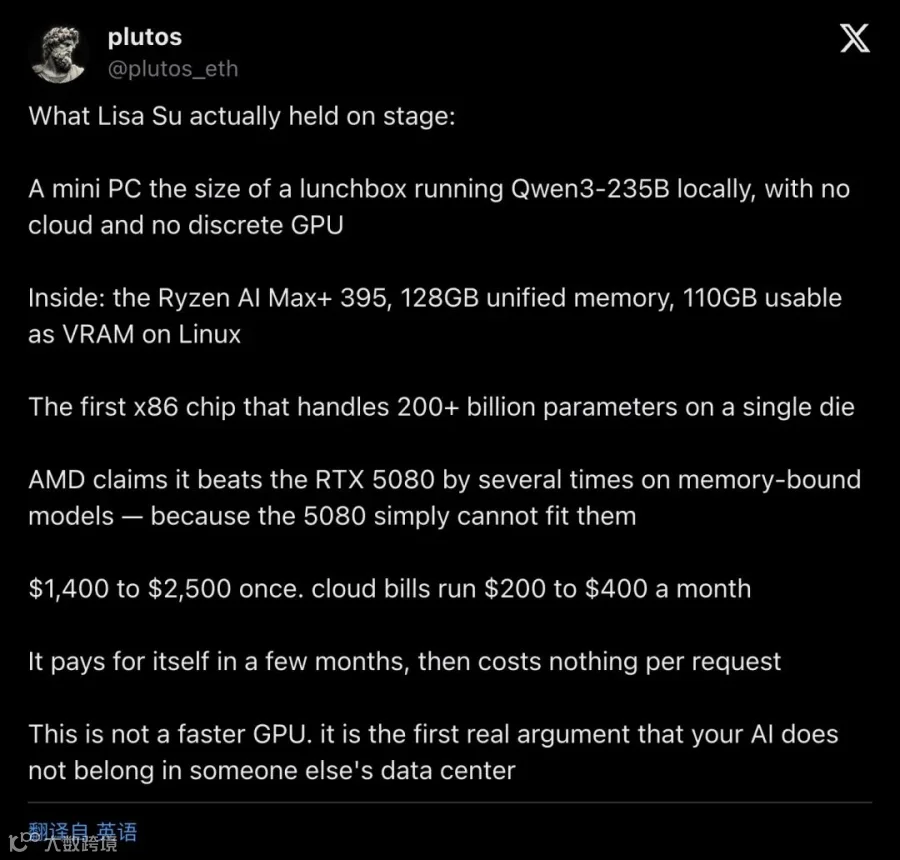


▲ @plutos_eth 的拆解线程在X上获得超过120万浏览,逐层解剖了“午餐盒”的硬件底牌与社区纠正
128GB统一内存,x86第一次摸到这个门槛
核心芯片是AMD Ryzen AI Max+ 395,一枚把CPU、GPU、NPU做在同一块硅片上的“怪兽”。
16个Zen 5核心,40个RDNA 3.5计算单元,再加一颗50+ TOPS的NPU。最关键的是内存——最高128GB LPDDR5X-8000,而且CPU和GPU共享同一块物理内存池。
这与传统架构有本质差别。
普通独显的显存通常8到32GB,CPU和GPU通过PCIe交换数据,中间有拷贝延迟,容量也受制于显存颗粒数量。而统一内存模型下,GPU可以直接寻址系统内存,物理上不再需要搬数据。Ryzen AI Max+ 395的GPU可从中分配约96GB作为“有效VRAM”,在Linux ROCm栈下甚至能拉到110GB以上。
上一代x86平台想跑70B稠密模型,普通消费级显卡显存根本塞不下。现在,一台迷你主机就能把235B参数的MoE模型装进内存,并且以实用速度给出推理结果。
这也是为什么AMD官方对比敢打出这样的数字:Stable Diffusion出图速度比Apple M4 Pro高出3.3倍,Flux高出7.3倍。对比Nvidia DGX Spark,在同等128GB配置下,AMD在每美元token产出上领先,而且同时支持Windows和Linux双系统。
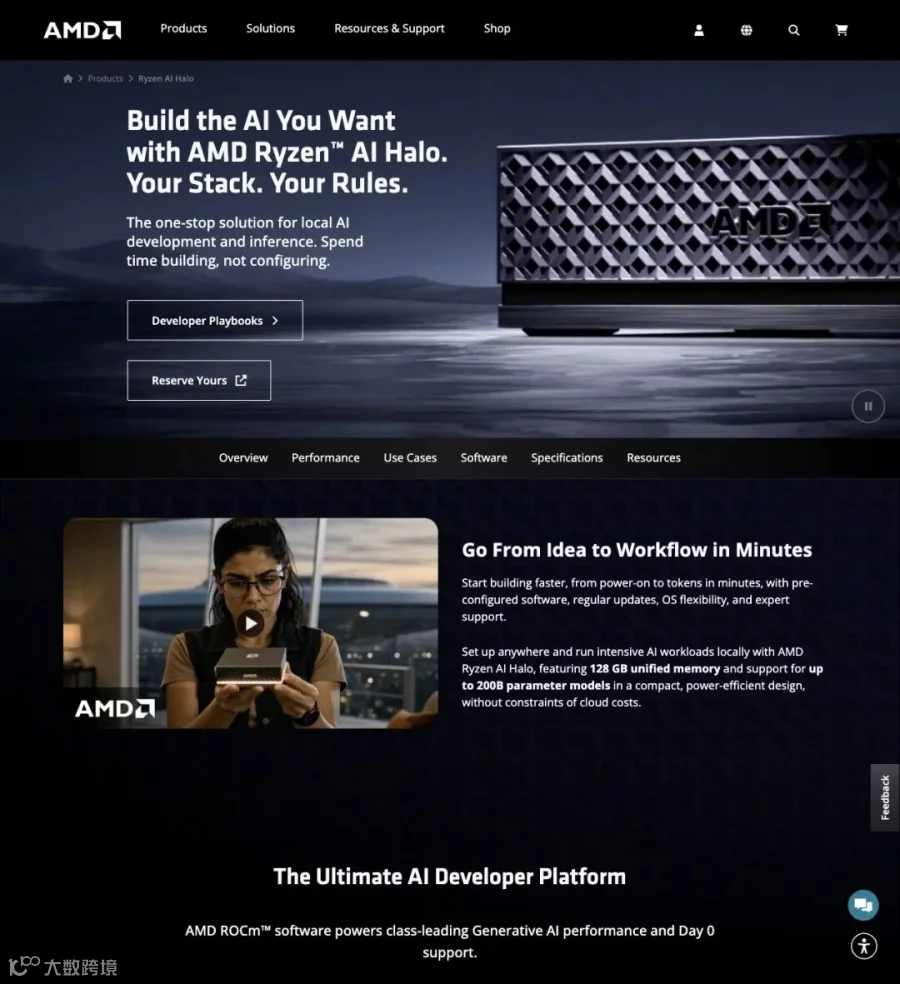
▲ AMD官方Halo平台页面:128GB统一内存、支持200B+模型、双OS、与M4 Pro/DGX Spark的性能对比
硬件已在货架上,不是PPT
社交平台上流传最广的“午餐盒”指向一款真实可买的产品——GMKtec EVO-X2。
这台机器的外形确实像饭盒:单手可持的紧凑机身,内部塞进了Ryzen AI Max+ 395和最高128GB内存。实测数据可以跑Qwen3-235B(MoE架构),输出速度约11 tokens/s。Llama 3.3 70B大约5 tokens/s。7到13B的小模型则能跑到30-45 tokens/s。
另一个玩家Minisforum也拿出了MS-S1 MAX,类似配置,128GB+2TB款标价约3679美元。官方还给出了双机集群方案:两台设备并行跑235B Q4模型,吞吐达到10.87 tokens/s。
这些硬件早于Lisa Su的演示就已经上架,某几个型号甚至售罄过。演示的真正意义,是让消费级x86“本地跑超大模型”这件事在社交层完成了爆发——从开发者圈扩散到了更广泛的公众视野里。
能跑和好用之间,隔着什么
11 tokens/s。如果你习惯了ChatGPT每秒几十token的输出,这个速度会让你皱眉。
之所以235B的模型能被128GB内存吃下,靠的是模型架构的取巧,不是硬件的暴力堆砌。Qwen3-235B是Mixture of Experts(混合专家)设计:虽然总共2350亿个参数,但每次推理只会激活约220亿个“活跃专家”。实际的工作集远小于标称值,才让11 tokens/s成为可能。
如果换成一个真正的235B稠密模型(每次推理激活全部参数),这台机器会直接歇菜。
还有一个常被忽略的硬约束:带宽。LLM推理真正的瓶颈在内存带宽,不在纯算力(TOPS)。模型权重放在内存里,每生成一个token就要从头到尾读一遍权重。Ryzen AI Max+ 395的理论带宽是256GB/s(实测约215GB/s),听起来不低,但顶级消费级显卡普遍在1TB/s以上。这意味着高并发场景、超长上下文场景下,带宽会迅速成为天花板。
AMD标称“DeepSeek R1推理比RTX 5080快3倍”,真实原因是RTX 5080的显存放不下完整模型,不得不频繁换页甚至直接跑不动。这更像一场容量比较,不是同条件的算力对决。
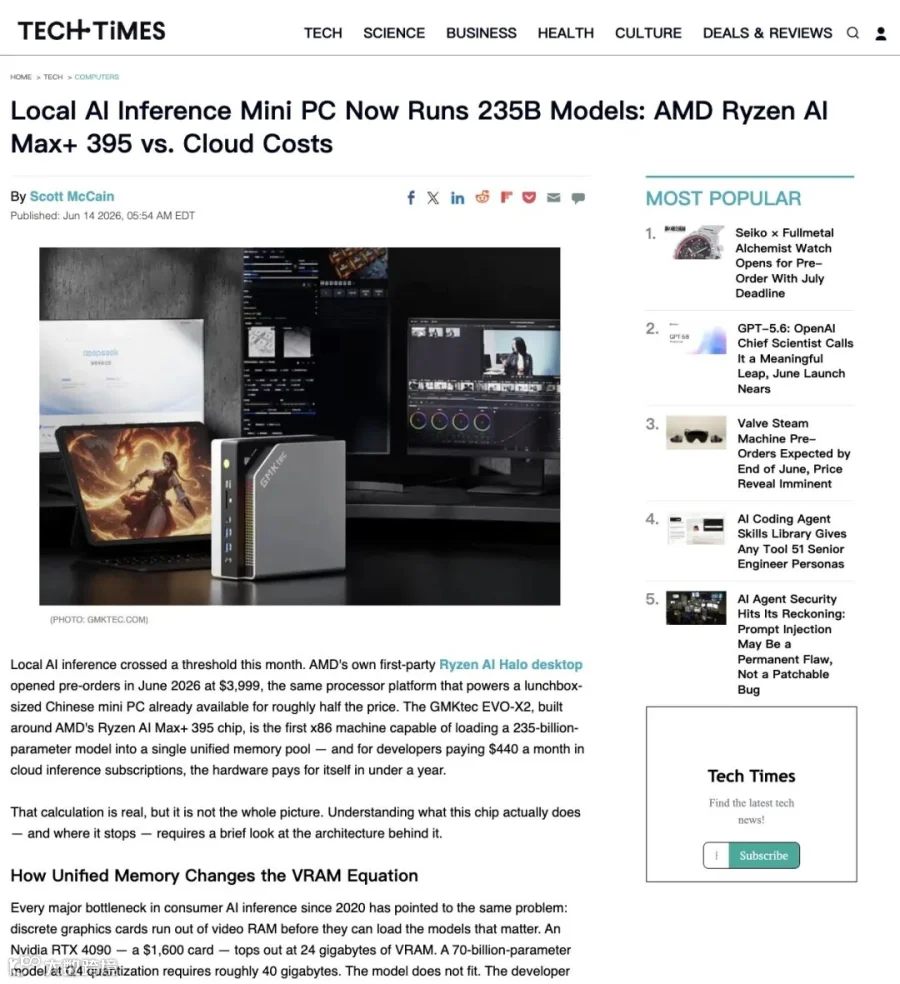
▲ TechTimes的深度拆解:架构图、实测性能数字(11 t/s、5 t/s)、ROI对比,第三方角度补全了官方未说的细节
软件栈的坎,AMD绕不开
硬件到位了,但把110GB的GPU内存真正用起来,需要Linux + AMD ROCm。
Windows下虽然也有Ollama、LM Studio等工具可跑,但显存分配受限,性能有明显折扣。ROCm是AMD对标CUDA的开源计算栈,近年来迭代速度不慢,但生态成熟度仍然落后。驱动配置、框架兼容、社区教程的密度,都与CUDA不在同一量级。
换言之,这台“午餐盒”目前更像一台开发者玩具,不像插电即用的消费电子产品。能跑,但要调。
“杀死订阅”这个说法,有几分真实
回到开头那笔账。
如果你当前的工作流完全可用开源权重模型替代——用DeepSeek V3代ChatGPT、用Qwen Coder代Cursor——那这台1500到4000美元的硬件确实能在9到10个月内回本。之后只剩下每月不到10美元的电费。
但如果你仍然依赖GPT-4o级别的闭源前沿模型,这台设备替代不了全部订阅支出。它是一种叠加选项:把不涉密的、需要频繁迭代的长上下文任务拉回本地,保留云端API处理需要最强模型的那部分工作。
这个结论没有“杀死订阅”听起来痛快,但更贴合实际。
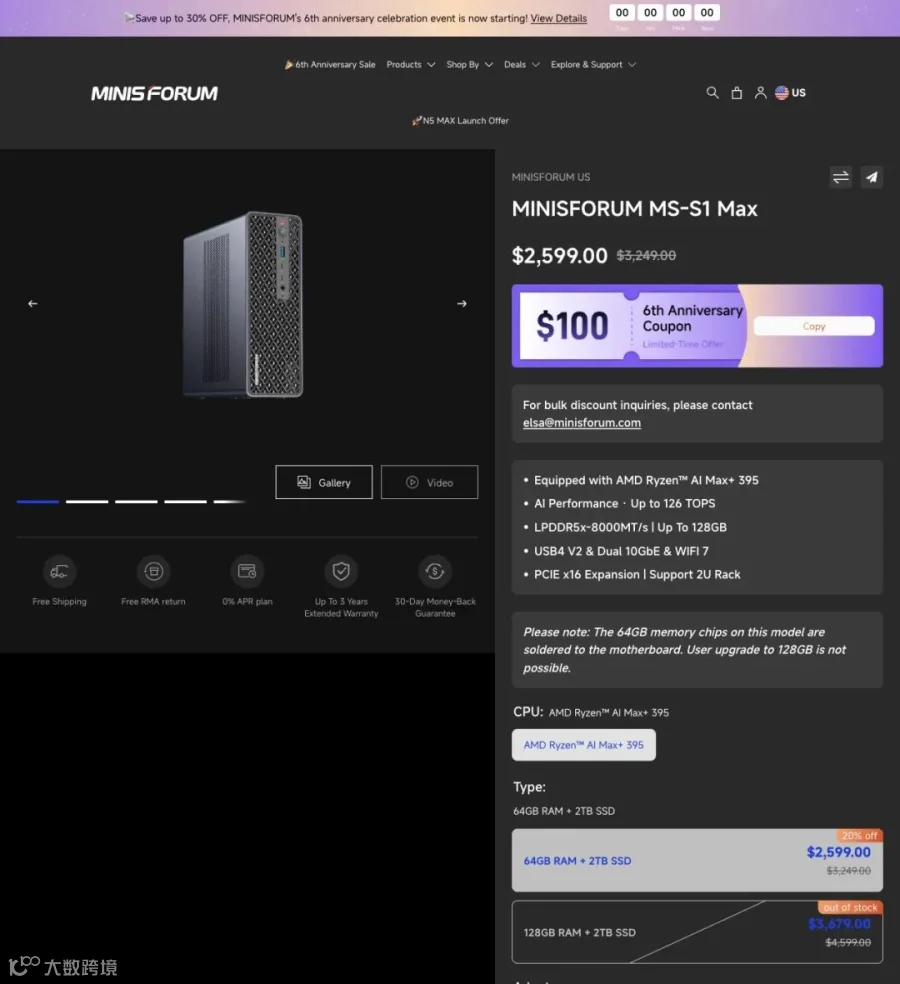
▲ Minisforum MS-S1 MAX:另一款搭载同芯片的迷你工作站,支持双机集群方案
底线在硬件之上,也在硬件之外
Lisa Su这次演示,真正改变的是认知——x86平台上的统一内存终于从一个“Apple做过但我们没有”的技术缺口,变成了可购买、可验证的实物。这也是AMD在整个客户端AI棋局里打出的一张差异化牌:用内存容量去压Nvidia的生态护城河。
但把机房塞进午餐盒,只是物理层面的解放。
数据不出本地,意味着隐私、合规、离线可用这些需求第一次在消费级价位上被严肃回应。对于企业用户来说,这比单纯省下几百美元月费的分量重得多。尤其是在跨境数据合规日趋收紧的背景下,一台不需要云连接就能跑200B模型的设备,回答的不只是成本问题。
同时也要正视一个事实:不同采购方会因供应链和合规要求做额外评估。但这恰好反衬了本地部署的优势——只要做好系统重置和网络隔离,数据路径就完全握在自己手里。
AMD已经预告了下一步:2026年Q3将升级至Ryzen AI Max PRO 400系列,最高支持192GB内存、160GB VRAM。容量继续涨,生态在追,价格存争议。那个“本地AI真正取代云端订阅”的时间点,未必在今天,但轨道的方向已经看得见了。