

目录
•模型部署安全保护[1]•硬件配置与模型选择[2]•Qwen-Coder模型部署[3]•模型微调指南[4]•训练成果保护方案[5]
模型部署安全保护
核心保护思路
"授人以鱼"而非"授人以渔" - 只提供模型推理服务,不暴露核心资产
多层次防御方案

第一层:基础环境隔离与加固
物理隔离 - 不连接互联网的独立服务器系统加固措施:最小化安装操作系统关闭不必要的端口和服务使用复杂密码和SSH密钥认证严格的文件系统权限控制系统日志监控和告警
第二层:模型资产保护
•模型权重加密:AES-256加密磁盘存储,内存中解密•模型混淆:剪枝、量化破坏原始结构•代码混淆:增加反编译难度
第三层:推理服务封装
# FastAPI服务封装示例from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelapp = FastAPI()class InferenceRequest(BaseModel):prompt: strmax_length: int = 512async def predict(request: InferenceRequest):# 模型推理逻辑return {"result": generated_text}
第四层:高级保护方案
•可信执行环境(TEE):Intel SGX, AMD SEV硬件级保护•硬件加密狗:绑定特定硬件才能运行•软件授权系统:硬件指纹验证
硬件配置与模型选择

3070显卡配置分析
•总显存:2 × 8GB = 16GB•实际可用:14-15GB•推荐部署规模:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
量化技术选择
# 4-bit量化配置from transformers import BitsAndBytesConfigquantization_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,)
Qwen-Coder模型部署
环境准备
# 创建Python环境python -m venv qwen_envsource qwen_env/bin/activate # Linux/Mac# 安装核心依赖pip install torch torchvision torchaudiopip install transformers>=4.37.0 accelerate modelscopepip install bitsandbytes vllm # 可选优化
模型下载
# 国内推荐 - ModelScopefrom modelscope import snapshot_downloadmodel_dir = snapshot_download("qwen/Qwen-Coder-7B")# 或使用Hugging Facefrom transformers import AutoTokenizer, AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-Coder-7B")
完整部署方案
基础推理服务
import torchfrom transformers import AutoTokenizer, AutoModelForCausalLMfrom fastapi import FastAPIimport uvicornclass QwenCoderServer:def __init__(self, model_path):self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16,device_map="auto",trust_remote_code=True)def generate_code(self, prompt, max_length=512):inputs = self.tokenizer(prompt, return_tensors="pt")with torch.no_grad():outputs = self.model.generate(inputs.input_ids,max_length=max_length,temperature=0.7,do_sample=True)return self.tokenizer.decode(outputs[0], skip_special_tokens=True)# FastAPI服务app = FastAPI()server = QwenCoderServer("./qwen-coder-7b")async def generate_code(prompt: str):result = server.generate_code(prompt)return {"code": result, "status": "success"}
安全增强部署
# API密钥认证from fastapi import Security, Dependsfrom fastapi.security import APIKeyHeaderAPI_KEY = "your_secret_key"api_key_header = APIKeyHeader(name="X-API-Key")def verify_api_key(api_key: str = Security(api_key_header)):if api_key != API_KEY:raise HTTPException(status_code=403, detail="Invalid API Key")return api_key# 速率限制from slowapi import Limiterfrom slowapi.util import get_remote_addresslimiter = Limiter(key_func=get_remote_address)async def generate_code_secure(prompt: str, api_key: str = Depends(verify_api_key)):return server.generate_code(prompt)
模型微调指南
微调版本选择
官方版本
•Qwen-Coder-7B-Instruct:指令微调版本,代码理解优化•Qwen-Coder-7B-Python:Python代码专门优化
社区版本
community_models = {"qwen-coder-7b-sft": "通用代码SFT","qwen-coder-7b-math": "数学编程优化","qwen-coder-7b-web": "Web开发专用"}
微调技术方案
QLoRA微调(推荐)
from peft import LoraConfig, get_peft_modellora_config = LoraConfig(r=8,lora_alpha=32,target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],lora_dropout=0.1,bias="none",task_type="CAUSAL_LM")model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-Coder-7B",load_in_4bit=True,device_map="auto")model = get_peft_model(model, lora_config)
数据准备格式
code_dataset = [{"instruction": "写一个Python函数计算斐波那契数列","input": "","output": "def fibonacci(n):\n if n <= 1:\n return n\n else:\n return fibonacci(n-1) + fibonacci(n-2)"}]
微调流程
1.环境准备:安装PEFT、Transformers等库2.数据准备:整理专有代码数据集3.配置训练:设置QLoRA参数4.开始训练:监控损失函数下降5.保存成果:生成适配器或合并完整模型
训练成果保护方案
免费保护工具
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
综合保护策略
推荐部署架构
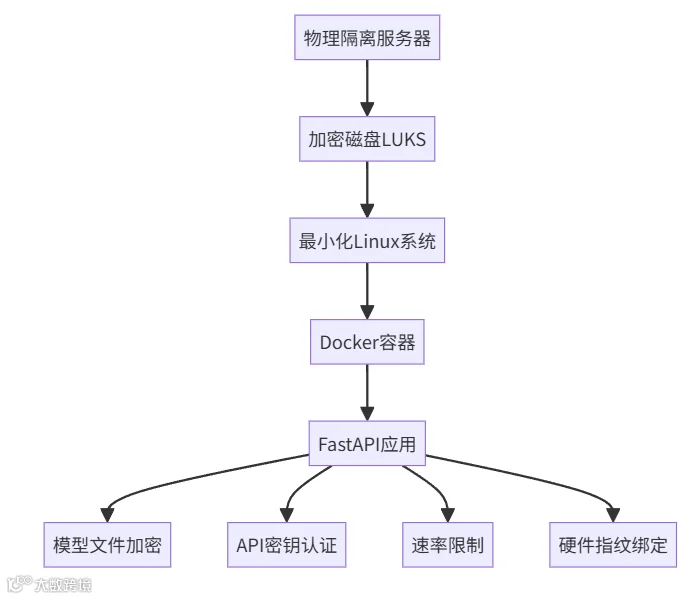
核心保护组合
1.模型文件加密 + 本地API服务封装2.API密钥认证 + 硬件指纹绑定3.速率限制 + 访问日志监控
实施建议
1.风险评估:根据模型价值确定保护等级2.纵深防御:多层防护,不依赖单一方案3.持续监控:定期检查系统日志和安全状态4.法律保护:结合法律协议增强保护效果
本文档基于实际技术讨论整理,提供了从模型选择、部署实施到安全保护的完整解决方案。根据具体需求可选择适合的技术组合。
References
[1] 模型部署安全保护: #模型部署安全保护[2] 硬件配置与模型选择: #硬件配置与模型选择[3] Qwen-Coder模型部署: #qwen-coder模型部署[4] 模型微调指南: #模型微调指南[5] 训练成果保护方案: #训练成果保护方案