

引言
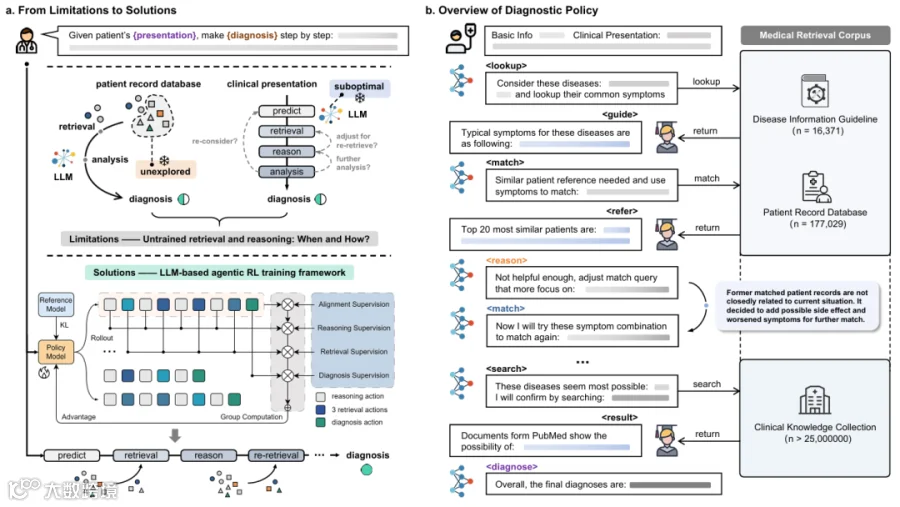
2 问题建模(Problem Formulation)


3 结果(RESULTS)
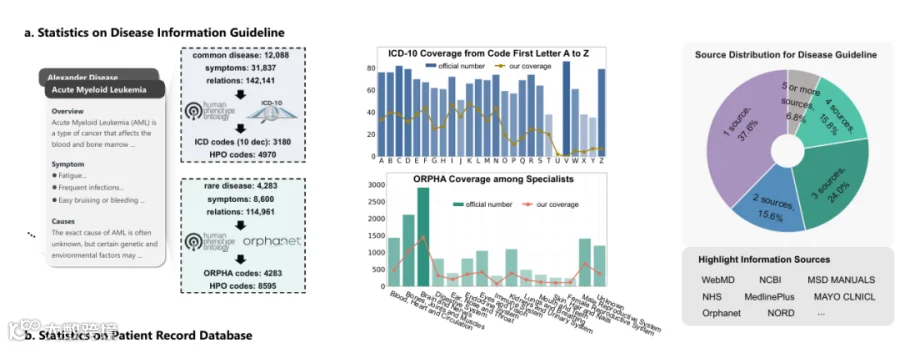
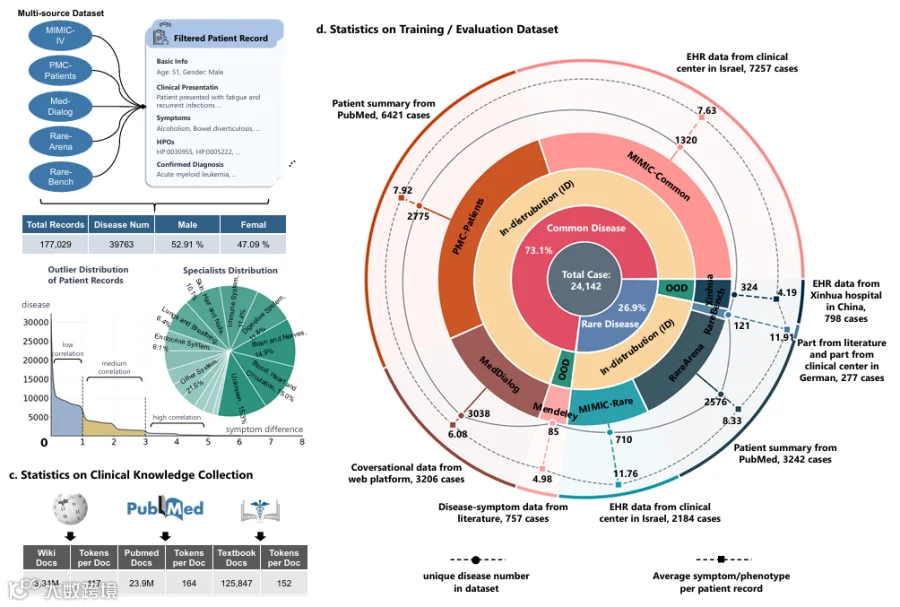
3.1 数据统计(Data Statistics)
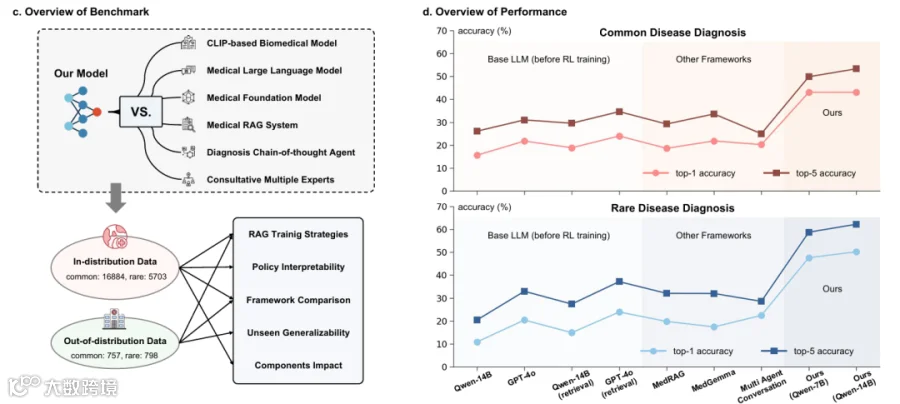
3.2 智能体式 RAG 系统设计对比(Comparison on Agentic RAG System Designs)
分布内(ID)评估(In-distribution Evaluation)
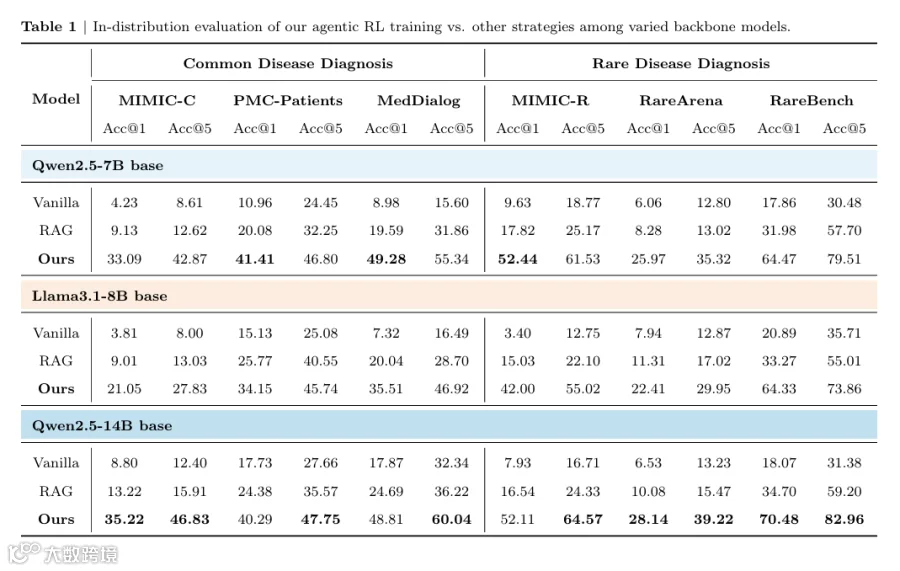
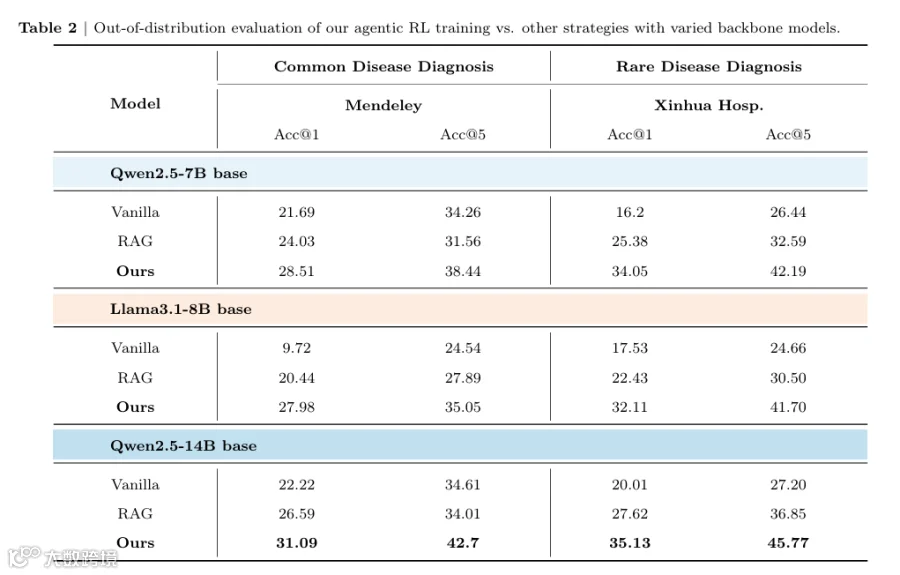
分布外(OOD)评估(Out-of-distribution Evaluation)
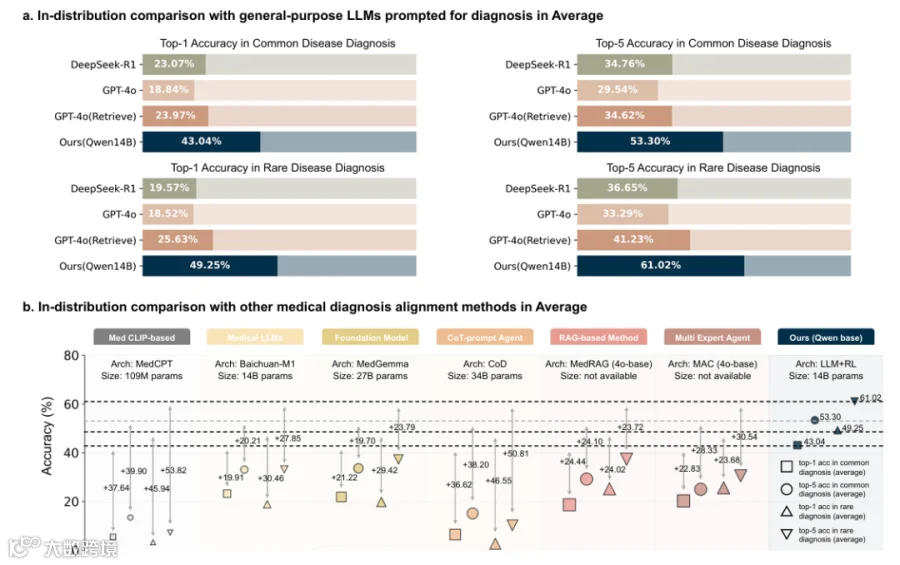
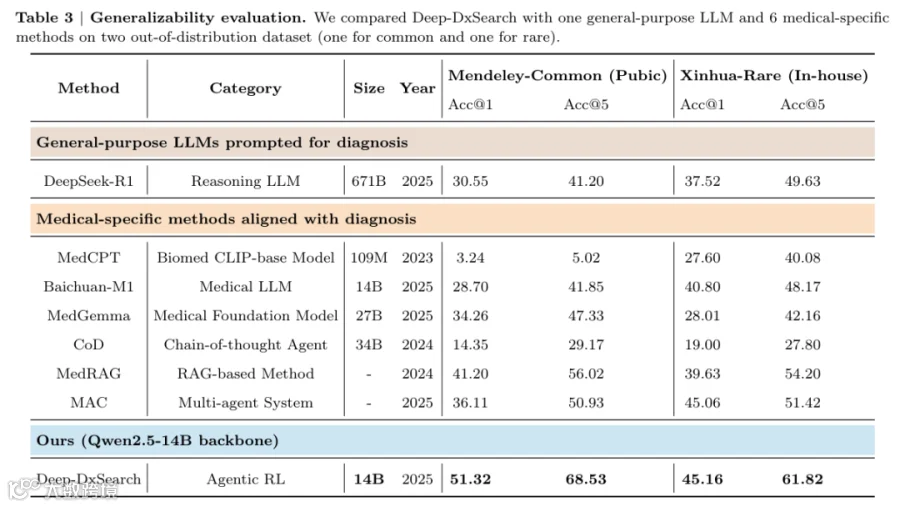
3.3 与其他诊断 SOTA 的比较(Comparison with Other Diagnostic SOTAs)
分布内(ID)评估
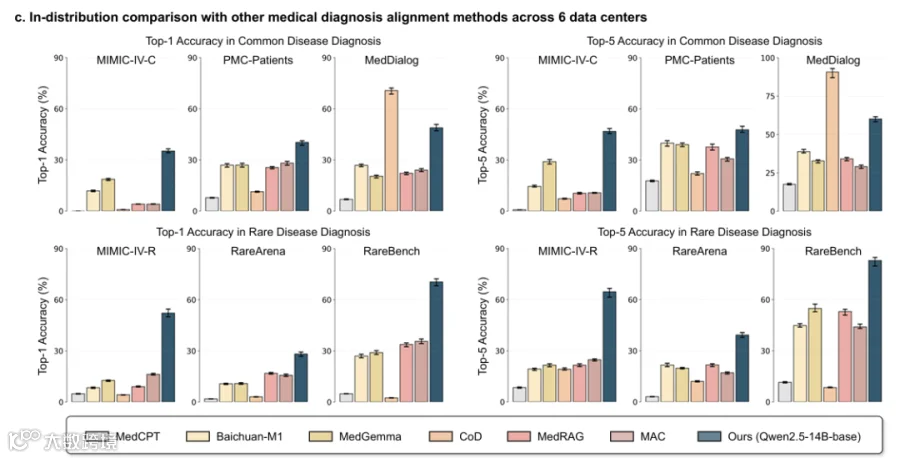
分布外(OOD)评估
3.4 消融实验(Ablation Studies)
奖励设计的消融(Ablation studies on reward design)
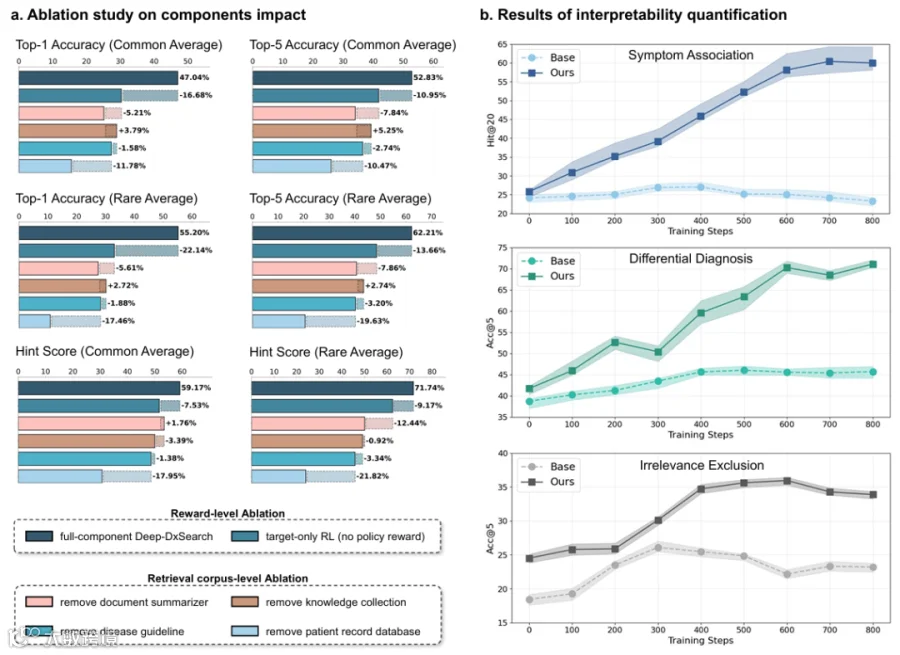
检索语料库的消融(Ablation studies on retrieval corpus)
3.5 学习到的 RAG 策略的可解释性分析(Interpretability Analysis of the Learned RAG Policy)
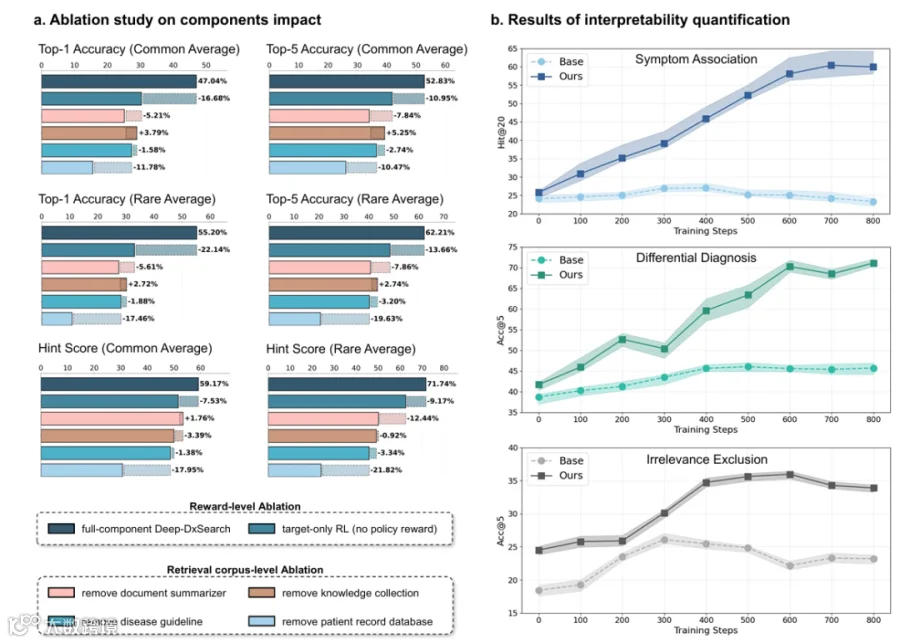
4 讨论(DISCUSSION)
5 方法(METHODS)
5.1 系统设计(System Design)
5.1.1 主工作流形式化(Main Workflow Formulation)









