
“ 技术与应用场景,是相互依存不可分割的一体两面”
去年是千模大战的一年,各大企业相继发布自己的AI大模型;openAI, 谷歌,Meta的模型也不断在变强;特别是前段时间openAI曝光的草莓计划,以及谷歌公司的大模型发布。
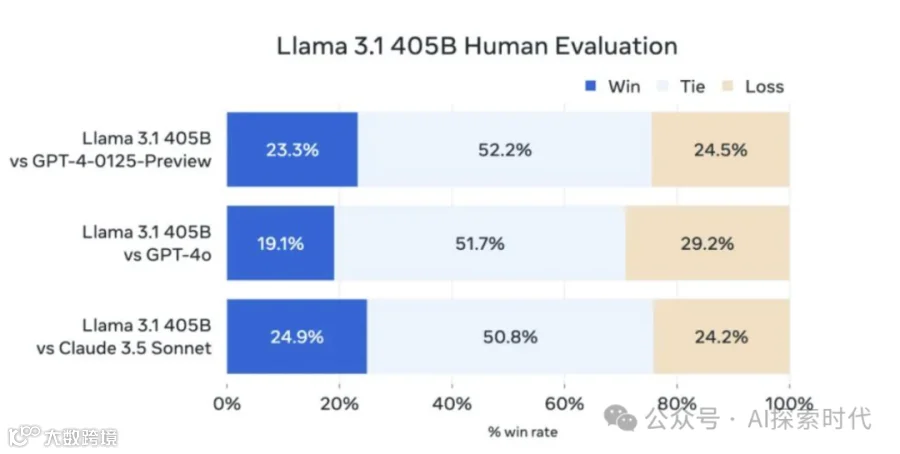
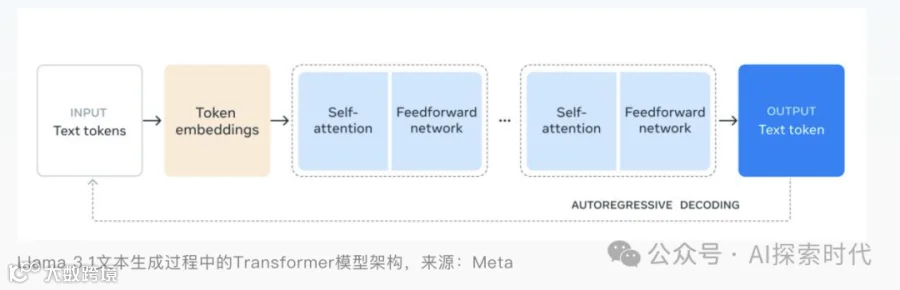
而这两天Meta又发布了新版Llama大模型3.1版本,据说性能是超越了GPT-4o,最重要的是官网给出了一份接近一百页的文档,里面详细说明了Llama3.1的设计,数据处理,训练,微调的过程。
01
—
Llama3.1发布带来的影响?
在目前的大模型生态中,openAI作为龙头老大一路领先;而其它国内外大厂也在不断的跟随openAI的脚步。
而openAI是一个纯粹的商业组织,其大模型也是完全闭源的商业大模型;要想使用就要给钱,然后通过接口调用的方式使用openAI的大模型功能。
但处于第二梯队的谷歌,meta都在不断开源自己的大模型;开源和闭源的区别就是,开源大模型的代码是公开的,任何人都可以下载使用,也就可以本地部署;而闭源大模型只能通过API的方式进行调用。
有人说,谷歌,meta开源大模型的目的是为了集众人之力,抗衡openAI的一家独大;这也是闭源模型和开源模型之战的来源。
在国内,百度总裁李彦宏同样在公开场合发表过闭源的商业模型会比开源的模型做的更好。
他说,大模型最难的并不是技术架构,而是怎么打造一个能用的且好用的大模型。
开源模型虽然解决了技术问题和架构问题,但我们并不知道他们是怎么训练的,用了什么数据,用了多少数据,而这才是打造一款能解决实际问题模型的根本所在。
当然,开源模型也同样有它的好处,那就是可以让别人对开源模型进行借鉴,模仿,然后打造出更加好用的大模型。
因此从这个角度来看,meta开源的Llama3.1模型有很多的好处,特别是它的文档;能够让更多的人了解大模型的运作原理;同时也能让我们国家拉近与国外大模型的技术差距。
个人开发的一款大模型聊天机器人,感兴趣的可以点击查看:
网络上有这么一个笑话,每次国外企业开源大模型,国内的大模型就能升级一次;其次这种说法是片面的,从技术的角度来说不要重复造轮子;并不是说所有东西都是自己研究出来的就说明你比别人强。人类科技的进步,就是在不断的学习和抄袭的过程中得到发展;如果任何技术都要从头开始,那人类社会的进步又从何谈起呢?
其次,大模型的开源与闭源之争,到目前为止还没有一个定论;总之一句话,花开两朵,各表一枝;开源有开源的好处,闭源有闭源的好处。
不论国内还是国外,都有人支持开源,也有人支持闭源;今年年初时,埃隆马斯克发布了X(原推特)公司的开源模型,meta也在不断持续开源llama系列模型,而谷歌也不甘其后的发表Gemini系列模型。
而国内虽然也在开源模型,但力度要比国外小的多,比如清华的GLM系列,阿里的通义系列等模型。
02
—
大模型后续发现方向
现在又回到了之前的问题,大模型的功能在不断迭代中加强;但好像大模型能做的事并没有增强。
现在大模型的主要应用场景,无非就是问答,文档总结,写写文章,画画图,做做自媒体等。
好一点的应用场景,无非就是外挂几个其它模块的接口(AI Agent技术),然后做一些简单事情,比如天气查询等。典型的是抖音推出的扣子平台。
在垂直领域,大模型完全没有发挥其应该有的优势;其既不能用来搞企业管理,也不能搞产品生产,更搞不了技术研发。
目前,大模型在企业中的作用更像是一个秘书文员类的职责。
因此,从这个角度来看,大模型的发展方向还是要以应用为主;以大模型技术本身的发展为辅。或者说,后续可能会以应用驱动大模型本身技术的发展。
任何技术的发展都需要两条腿,一条腿是技术的本身;另一条的是技术的应用场景。

没有了应用场景,那么技术就失去了价值;而没有了技术,应用场景就无法得到满足。
因此,技术与应用并不是相互对立的矛与盾;而是硬币的一体两面,没了一面,另一面也就不存在了。