
“ 任何产品最真实的评价,就是市场(用户)反馈”
从根本上来说,设计和训练一款大模型的目的是用来解决我们生活和工作中的问题,从更加抽象的角度来说是为了提升生产力和生产效率。
因此评价一款大模型的好坏不是看它使用了什么架构,也不是它用了多少训练数据,而是它实际应用中的表现能力;而这也是大模型从理论或者说实验推向实际业务场景的必要环节。
因此,怎么评价一款大模型就成了一个问题,而怎么解决这个问题?
01
—
大模型的评价体系
其实从实际角度来说,任何评价的标准都没有直接实际检验来的快,来的有效;模型好不好直接拿过来用不就知道了,让使用者感到好用,那就是好,否则就是不好。
就像当年支付宝刚推出时那样,马云亲自体验支付宝的使用,然后自己一眼看不明白不知道怎么用的功能就需要重新设计和优化,不要谈什么用了什么设计理念,有什么天才般的构想,好用才是一切。
大模型也是如此,能用并且好用才是大模型追求的标准。
但由于大模型的成本问题,比如需要大量的训练数据,以及大量的计算资源等;这就导致大模型训练需要很大的成本,因此为了节约成本就需要有一套大模型性能评价的标准,这样才能用最小的成本来训练一个更好用的模型。
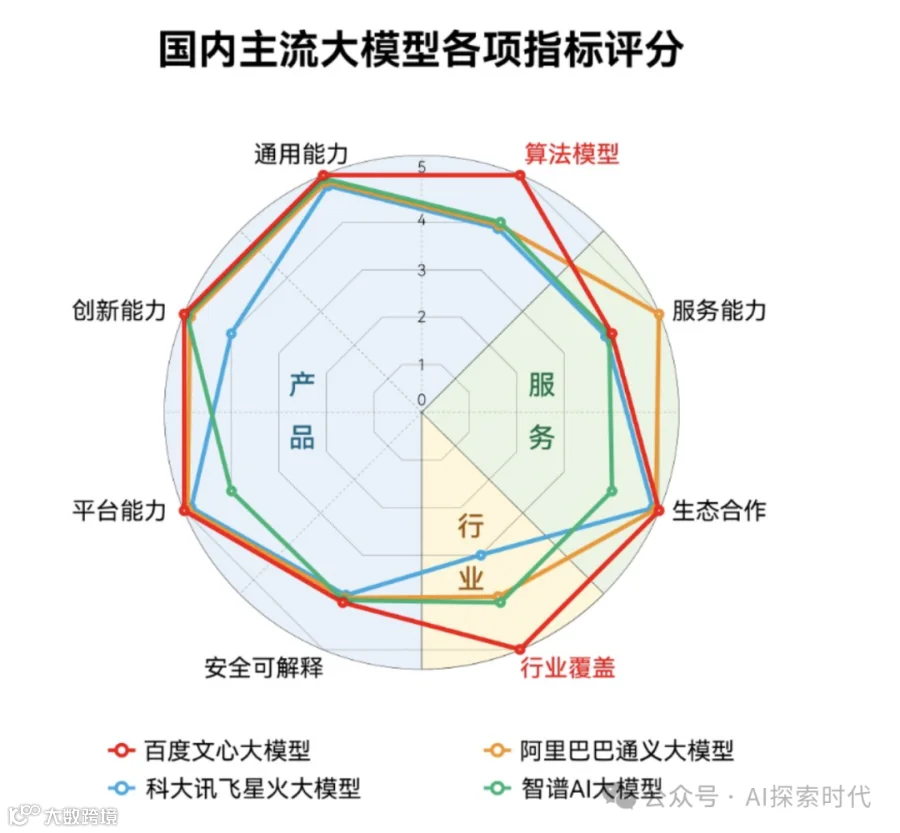
那怎么评价一个大模型呢?也就是设计一个大模型评价标准的方法。
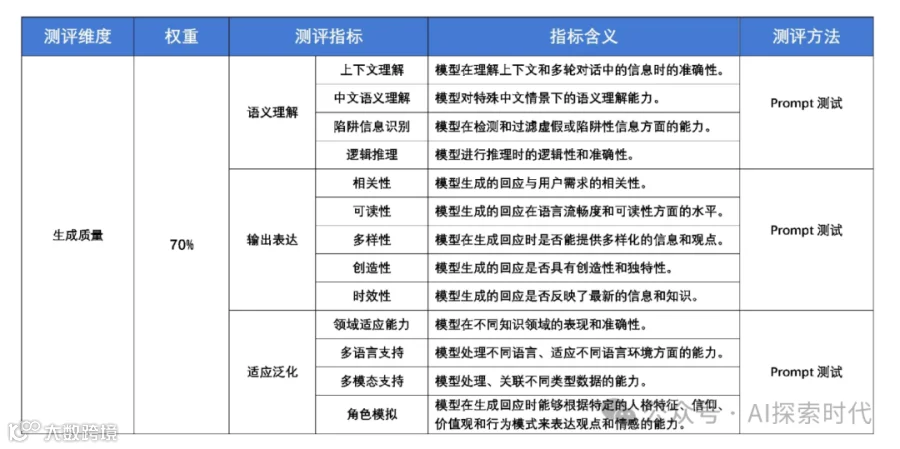
评估一款大模型涉及到多个方面,确保模型在性能,效率,鲁棒性和实用性等方面都能满足要求。下面是一些主要的评估维度和方法:
性能评估
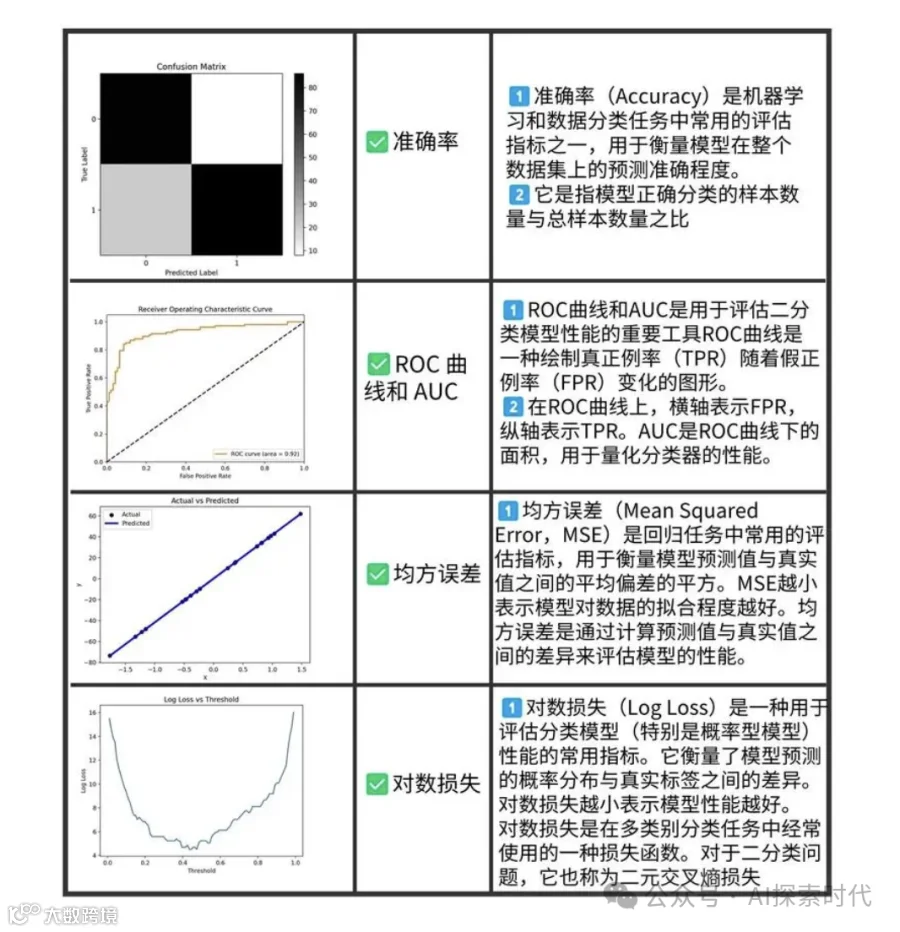
准确性
任务特定指标:根据模型应用的具体任务使用相应的性能指标,如分类准确率,回归误差,BLEU分数(用于翻译),ROUGE分数(用于摘要)
基准测试:使用标准数据集和任务(如GLUE,SQuAD,COCO等)进行评估,比较模型在这些任务上的表现
生成质量
流畅性和连贯性:评估生成文本的语法正确性,语义连贯性。可以使用人工评估或自动化平分工具(如perplexity,BLEU分数)
创造性和多样性:评估生成文本的多样性和创造性;可以使用自动化指标(如N-gram多样性)或人工评估
效率评估
计算效率
推理时间:测量模型在给定输入上的推理时间,包括处理速度和响应时间
训练时间:评估模型从初始训练到收敛所需的时间
内存和计算资源
内存消耗:评估模型在推理和训练时的内存占用
计算开销:测量模型的计算复杂度,通常以FLOPs(每秒浮点运算次数)或其它计算资源的消耗来表示
鲁棒性和稳定性
抗噪声能力
处理异常输入:评估模型在面对输入噪声或异常数据时的表现,例如错误拼写,语法错误等
一致性
稳定性测试:检测模型在不同随机种子,不同输入顺序等条件下的表现是否稳定
通用性和适用性
迁移学习
任务适用性:评估模型在不同但相关任务上的表现,例如预训练模型在下游任务上的微调效果
泛化能力
跨领域表现:评估模型在不同领域,不同类型的数据上的表现
伦理和公平性
偏见检测
公平性测试:检测模型是否对特定群体存在偏见,例如种族,性别,年龄等方面的偏见
伦理考虑
生成内容监控:评估模型生成的内容是否符合伦理标准,避免生成有害或不准确的信息
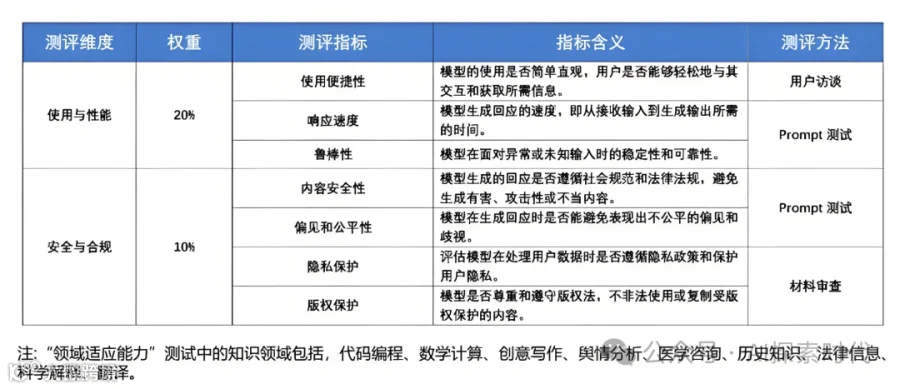
用户体验
实用性
用户反馈:收集用户对模型输出的反馈,评估模型的实用性和满意度
易用性
界面和集成:评估模型的API或用户界面的易用性,是否方便集成到现有系统中
可解释性
透明度
解释能力:评估模型的可解释性和透明度,即能否理解模型的决策过程或输出的原因
可视化
结果可视化:使用可视化工具展示模型的内部机制或预测结果,帮助理解和分析模型的行为
安全性
防御能力
攻击测试:评估模型在面对对抗性攻击(如对抗样本)时的防御能力
数据隐私
隐私保护:确保模型在处理用户数据时遵循数据隐私和安全标准
人工智能机器人小程序,感兴趣的可以点击查看:
总结
评估大模型的过程包括多个维度,涉及性能、效率、鲁棒性、通用性、伦理、公平性、用户体验、可解释性和安全性。每个维度都需要通过特定的方法和指标进行评估,以确保模型在实际应用中的有效性和可靠性。通过综合考虑这些评估因素,可以全面了解模型的优缺点,并为进一步优化和应用提供指导。