
“ 模型优化不仅能节约成本,还能提升模型的响应速度”
对一家企业来说,大模型的压缩与部署是一个很重要的环节,不但能够节约企业成本,也可以优化用户体验。
因此,怎么压缩出一个性能更好的大模型,就是一个值得思考的问题。
今天就来讨论一下,怎么打造一个性能优越的大模型——也就是模型的蒸馏技术。
01
—
什么是蒸馏技术?
所谓的蒸馏技术就是通过迁移学习的思想,将一个复杂的大模型的知识传授给相对简单的小模型。
简单概括就是利用教师模型的预测概率分布作为软标签对学生模型进行训练,从而在保持高预测性能的同时,极大降低了模型复杂度和资源需求,实现模型的轻量化与高效化。
以上是网上对蒸馏技术的定义,可能很多人看的都是云里雾里的,包括我自己。
那么,应该怎么理解模型蒸馏的技术呢?
事实上,模型蒸馏也分为两种不同的技术,一个是模型蒸馏,另一个是知识蒸馏;当然还包括一些其它的变种方式,比如,层蒸馏,自蒸馏和任务蒸馏等。
总之一句话,蒸馏技术的目的是为了压缩模型,使其更轻巧,更高效。
那蒸馏技术是怎么实现的呢?
知识蒸馏技术是从一个复杂的大模型(源模型)中提取知识,然后用于构建一个新的小模型(目标模型)的过程。因此,知识蒸馏的核心就是大模型知识的提取,以及小模型知识的训练。
为什么叫蒸馏技术?
是因为这个过程类似于物理和化学实验中,从一些不纯的物品中提纯出需要的元素。
蒸馏过程
根据前面对蒸馏技术的描述,因此蒸馏技术首先要有两个模型,一个是训练好的复杂大模型,一个是待训练的小模型。
在把训练数据输入源模型的过程中,大模型会输出预测结果,也就是软标签;然后通过损失函数来计算小模型训练过程中与大模型预测结果的差异,然后根据反向传播算法对模型进行优化。
这样就可以在较小的训练数据集上训练出更轻巧,高效的大模型。
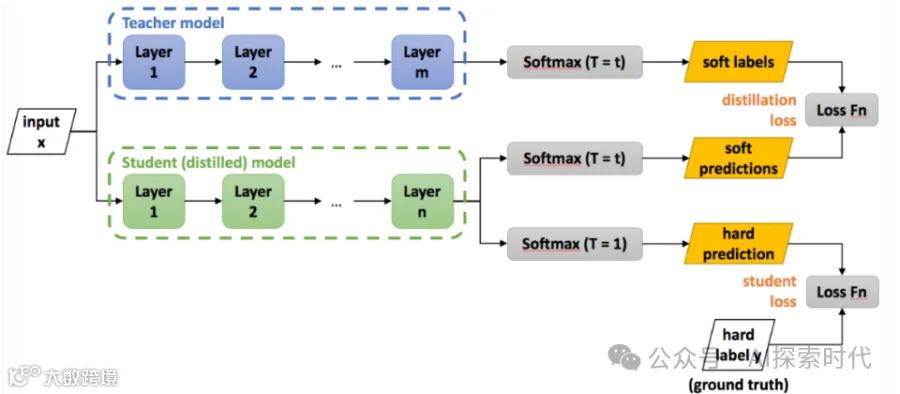
模型蒸馏技术的实现流程通常包括以下几个步骤:
(1)准备教师模型和学生模型:首先,我们需要一个已经训练好的教师模型和一个待训练的学生模型。教师模型通常是一个性能较好但计算复杂度较高的模型,而学生模型则是一个计算复杂度较低的模型。
(2)使用教师模型对数据集进行预测,得到每个样本的预测概率分布(软目标)。这些概率分布包含了模型对每个类别的置信度信息。
(3)定义损失函数:损失函数用于衡量学生模型的输出与教师模型的输出之间的差异。在模型蒸馏中,我们通常会使用一种结合了软标签损失和硬标签损失的混合损失函数(通常这两个损失都可以看作交叉熵损失)。软标签损失鼓励学生模型模仿教师模型的输出概率分布,这通常使用 KL 散度(Kullback-Leibler Divergence)来度量,而硬标签损失则鼓励学生模型正确预测真实标签。
(4)训练学生模型:在训练过程中,我们将教师模型的输出作为监督信号,通过优化损失函数来更新学生模型的参数。这样,学生模型就可以从教师模型中学到有用的知识。KL 散度的计算涉及一个温度参数,该参数可以调整软目标的分布。温度较高会使分布更加平滑。在训练过程中,可以逐渐降低温度以提高蒸馏效果。
(5)微调学生模型:在蒸馏过程完成后,可以对学生模型进行进一步的微调,以提高其性能表现。
其实简单来说,模型的训练就类似于老师让你做题,然后做完之后让老师检查,做错了之后再拿回去重做。
而蒸馏技术就是,老师先把题目做一遍,然后把每一题的思路告诉你,然后再让你做,这样明显会快得多,也会简单的多。
这样的好处是你能少走很多弯路,少了很多错误的方法,能够让你在短时间内学的更好,更快。
它是您的私人助手,能够回答您关于工作,生活,感情的问题,以及提供建议,并且可以帮您撰写工作报告,媒体文案,感兴趣的可以点击查看: