
“ 向量化是一切大模型技术的基础,大模型中的一切都是向量。”
在之前的文章曾不止一次的讲过向量,向量作为大模型的基础数据格式,其重要性不言而喻;但大部分人对向量还是没有一个深刻的认识。
所以,今天我们就来讨论一个问题,那就是向量化,大模型的入口。
向量化
向量的概念这里就不解释了,有问题的可以看之前的文章,或者自己去找一下向量,矩阵的内容看看。
先来讨论第一个问题,为什么要向量化?
原因在于计算机无法直接处理非数值性计算,所以的计算都需要转换成数值运算才行;但数值计算的方式有很多,为什么会选择向量作为载体?
原因就在于向量的几个基本特性:
第一就是向量便于计算机进行处理;
第二就是向量能够表示文本,图像等之间的语义关系
第三就是使用矩阵来表示向量,计算效率更高
什么是向量化?
简单来说向量化就是把其它格式的数据转换为向量形式,这里的其它格式包括我们常见的一切格式的数据,文本,图像,视频,音频等等;因此,可以直接把向量化理解为一种数据格式转换的技术。
在大模型中哪些地方需要进行向量化?
简单来说,任何需要输入到大模型的数据都需要向量化;其次,需要记录语义关系的也都需要向量化,比如RAG,向量数据库等。
众所周知,大模型是由一个输入层,一个隐藏层,一个输出层组成;而其中隐藏层包括一个或多个神经网络层。其中,输入层需要做的一件事就是把输入数据向量化,只有这样才能被隐藏层接受和处理。
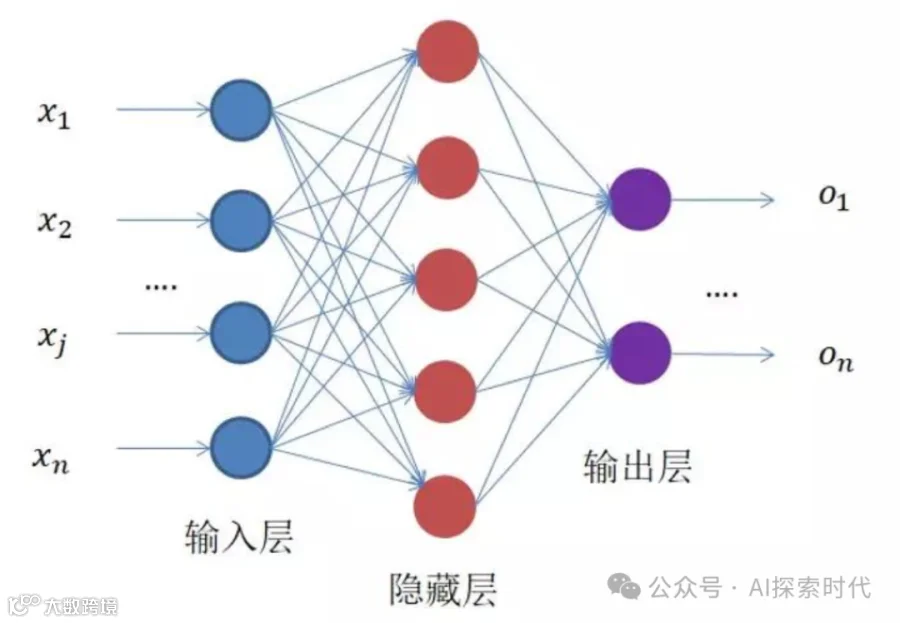
记住一句话,在大模型中一切都是向量。
那怎么实现向量化?
在不同的技术阶段,向量化的方式也有所不同;以文本向量化来说,文本向量化一般有三种方式:
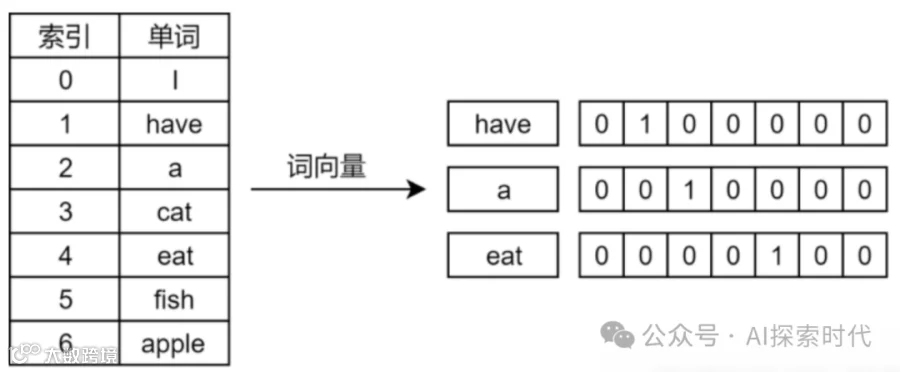
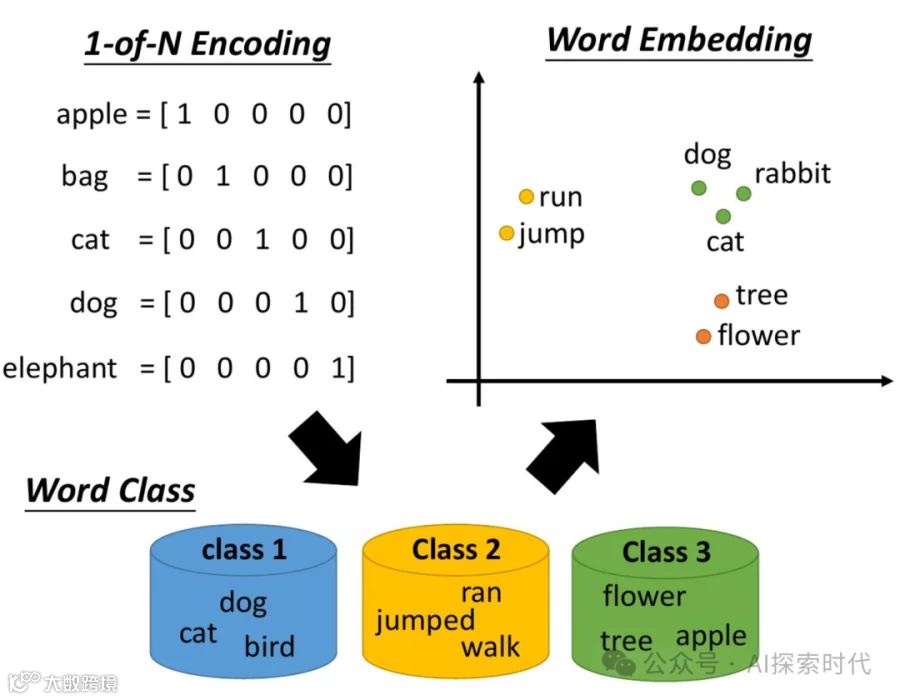
one-hot编码
词汇映射(Word2Vec)
Word Embedding(广义上Word2Vec也属于Word Embedding的一种)
词嵌入是文本向量化的一种常见方式,一般情况下会将一个单词映射到一个高维向量中来代表这个词,这就是词向量。
而文本嵌入层的作用就是,将文本中词汇的数字表示转变为高维的向量表示,旨在高维空间捕捉词汇间的关系。
Embedding 可以说是目前比较常见的一种向量化的方式,各大模型服务商,以及开源社区都发布了大量的Embedding模型来提供给用户使用;而Embedding嵌入就是一种经过专门训练的用来向量化数据的神经网络模型。
只不过Embedding嵌入模型经过矩阵算法的优化,比传统的向量化方式效率更高,效果更好。
https://cloud.tencent.com/developer/article/1749306
而且,Embedding的应用非常广泛,其不仅是大模型的基础技术之一;事实上,Embedding也是大模型技术的应用场景之一。比如在图像搜索,推荐系统,广告,搜索等业务中,Embedding都发挥着重要的作用。
了解了文本向量化的工具之后,那么思考一下图像和视频是怎么实现向量化的?
在图像向量化的过程中,卷积神经网络和自编码器都是用于图像向量化的有效工具;前者通过训练提取图像特征并转换为向量;后者则学习图像的压缩编码以生成低维向量表示。
卷积神经网络(CNN):通过训练卷积神经网络模型,我们可以从原始图像数据中提取特征,并将其表示为向量。例如,使用预训练的模型(如VGG16, ResNet)的特定层作为特征提取器。
自编码器(Autoencoders):这是一种无监督的神经网络,用于学习输入数据的有效编码。在图像向量化中,自编码器可以学习从图像到低维向量的映射