
“ 损失函数是实现大模型训练的基础”
在上一篇文章中介绍了大模型训练的核心算法之反向传播,而今天就来介绍一下大模型训练的另一个核心算法——损失函数算法。
大模型正是利用损失差和反向传播算法来更新模型参数的权重,依此达到最优化模型参数的目的,而这也直接关系到大模型的推测效果。
大模型损失函数计算
损失函数是机器学习与深度学习中用于衡量模型预测与实际结果之间差距的函数;选择合适的损失函数对于训练模型的性能至关重要。
以下从技术原理,实现等多个方面介绍损失函数:
原理
损失函数是一个衡量模型预测与实际结果之间差异的函数,它输出的通常是一个标量,表示预测结果的误差大小;目标是最小化损失函数的值,从而提高模型的预测性能。
作用
模型训练:损失函数用来指导模型的训练过程,通过优化算法调整模型参数,以降低预测误差
性能评价:损失函数的值可以用于评价模型性能
优化目标
优化目标是通过梯度下降或其它优化算法最小化损失函数,从而找到模型参数的最优解
实现
损失函数类型
回归问题:
均方误差(Mean Squared Error, MSE):
L ( y , y ^ ) = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 其中
y i y ^ i N 均绝对误差(Mean Absolute Error, MAE):
L ( y , y ^ ) = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ MAE对异常值的敏感度较低。
分类问题:
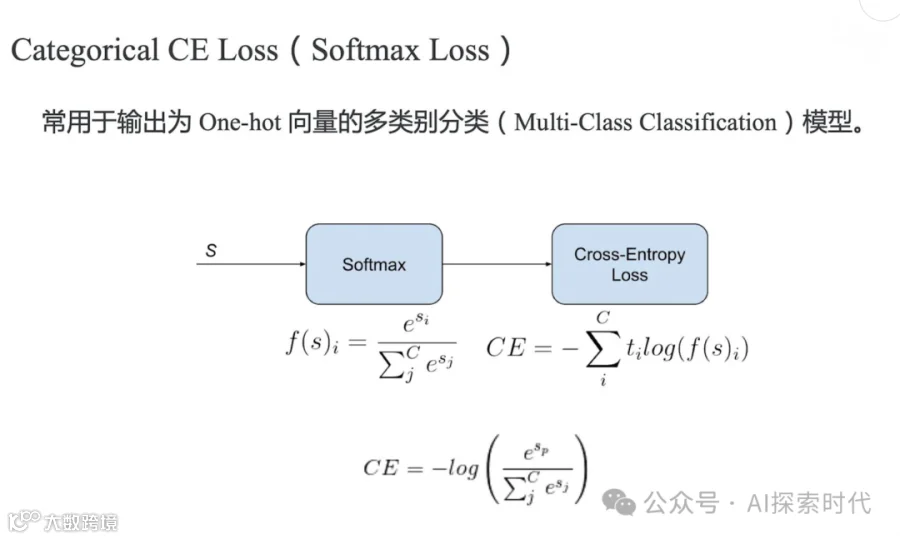
交叉熵损失(Cross-Entropy Loss):
L ( y , y ^ ) = − ∑ i = 1 N y i log ( y ^ i ) 其中
y i y ^ i 对数损失(Log Loss):
L ( y , y ^ ) = − [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ] 用于二分类问题,其中
y y ^
计算过程
前向传播:计算模型预测值
损失计算:将预测值与实际标签带入损失函数,计算损失值
反向传播:通过链式法则计算损失函数相对于模型参数的梯度,指导参数更新
技术细节
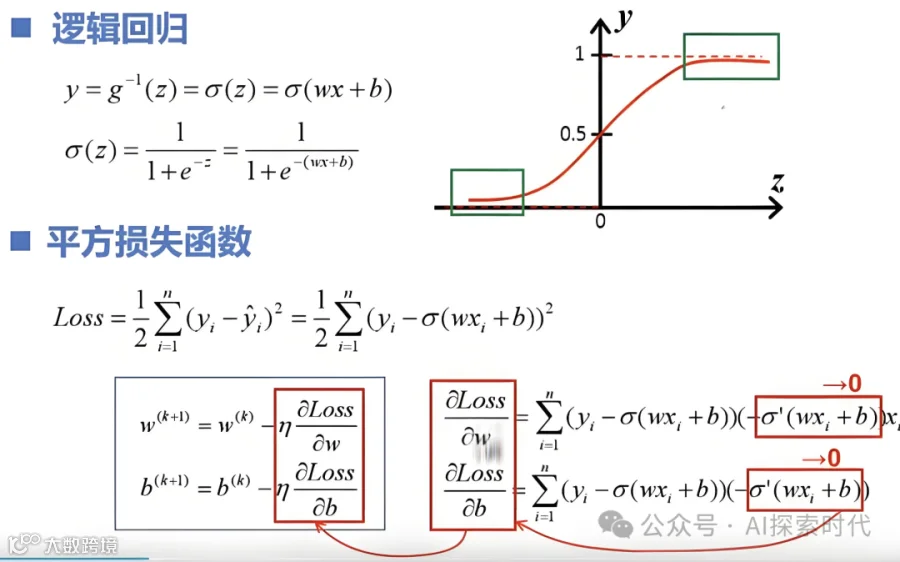
梯度计算
链式法则:用于计算损失函数对每个模型参数的梯度,在反向传播过程中,通过链式法则将损失函数的梯度逐层传播到网络的每个参数
示例:对均方差损失函数的梯度计算
数值稳定性
避免对数函数中的零:在计算交叉熵损失时,预测概率可能为零,导致对数函数的计算不稳定。通常采用平滑处理,如
log ( y ^ + ϵ ) ϵ 1 e − 10 标准化:对输入数据进行标准化,以提高数值计算的稳定性和收敛速度。
选择损失函数
根据任务选择:根据具体的任务(回归、分类、排序等)选择合适的损失函数。例如,回归任务通常使用均方误差,分类任务通常使用交叉熵损失。
损失函数的鲁棒性:根据数据特征选择适合的损失函数。例如,当数据中存在较多异常值时,可以选择对异常值不敏感的损失函数,如均绝对误差。
优化算法
梯度下降算法:常用的优化算法有批量梯度下降(BGD)、随机梯度下降(SGD)和小批量梯度下降(Mini-Batch SGD)。
高级优化算法:如动量法、RMSprop、Adam等,这些算法通过调整学习率和引入动量,能够加速收敛和提高训练效果。
实现细节
框架支持:现代深度学习框架(如 TensorFlow、PyTorch)提供了丰富的损失函数实现,并自动计算梯度。使用这些框架可以简化损失函数的实现和计算过程。
自定义损失函数:在需要特殊损失函数时,可以根据任务要求自定义损失函数。这通常涉及定义损失函数的计算过程并确保其可导性。
基于大模型开发的人工智能机器人小程序:
总结
损失函数是机器学习模型训练过程中的关键组成部分,它衡量模型预测的准确性并指导模型参数的优化。理解损失函数的原理、实现和技术细节对于成功训练和优化模型至关重要。选择合适的损失函数、计算梯度、处理数值稳定性问题以及使用优化算法,都是提高模型性能的重要步骤。