
“ 把大模型应用做出来和把模型应用做好是两回事;做出来可能只需要一两个月,而做好可能需要一两年甚至更久。”
最近手头上的一个大模型应用项目的基本功能都做完了,虽然从功能上来看都做完了;但从测试结果上来看,根本没有达到想要的效果,因此后面的主要任务是怎么优化系统;但等真的尝试去优化系统的时候才发现,这个系统到处都是问题。
所以说,用大模型做应用很简单,但想把应用做好就很难了。
怎么把大模型应用做好
大模型应用从本质上来说,就是利用大模型的理解和生成能力,取代人类在系统中扮演的角色(比如说做设计,写代码),利用大模型的决策能力去实现系统自动化运行。
但这里有个潜在的问题,那就是模型的稳定性,由于模型本身的特性使得大模型无法稳定的理解问题并输出;所以就导致系统会出现各种各样的问题,特别是在对大模型稳定性要求比较高的情况下。
首先以理解能力来说,其比较经典的应用场景就是RAG;而RAG的第一步就是文档处理,怎么才能准确召回与问题相关的数据;而对文档处理的好坏,直接影响到召回数据的质量。
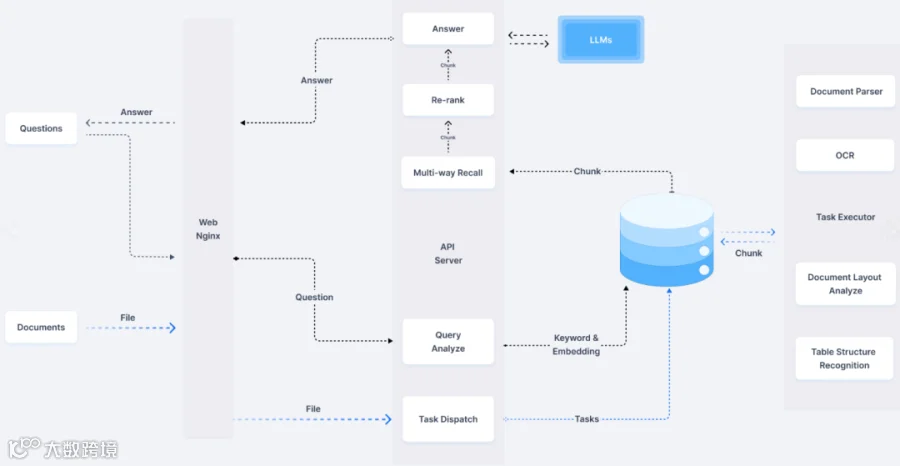
而这个文档出来就是基于大模型来实现的(embedding-嵌入模型),特别是复杂文档,很难保证文档的语义相关性。
因此,关于文档处理我们就要想好多种办法,而原则就是提升文档的语义相关性;比如说文档怎么拆分(文档拆分的长度,关联性,合理性都会直接影响到数据的召回),怎么组织数据;比如说把excel转换成markdown格式,word,pdf等对里面的图片,表格进行特殊处理等。
还有就是,可以通过让模型对拆分的文档做总结提炼,亦或者提取关键词标签;这样就可以相对提高数据召回的准确性。
但受限于当前的技术手段,不论怎么搞都很难达到我们的要求;所以,既然在左侧的文档处理方面已经黔驴技穷了;那么就只能想办法在右侧数据召回方面多下点功夫了。
那在数据召回方面应该怎么做呢?
首先可以对用户的问题进行优化,因为我们无法控制用户的输入,因此用户输入可能存在很多问题,比如说错别字,语句不通顺,缺词少句等;而我们就可以让大模型先理解用户的问题,然后对用户的问题进行优化,并根据用户问题提出几个相似的新问题,这样就可以间接提升数据的召回广度。
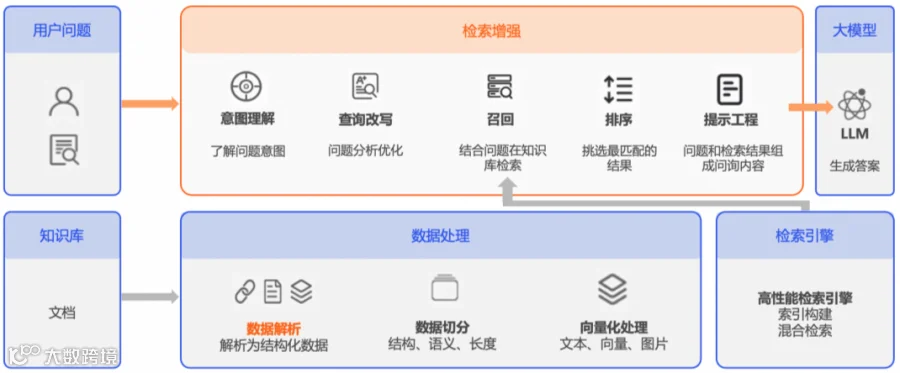
当然,这种方式只能部分提升数据的召回质量,但解决不了根本问题;特别是在一些需要动态数据的场景下,需要根据问题从多个维度召回数据。但受限于RAG的流程是固定的,因此就没有办法了。
而这时,我们可能需要使用Agent智能体技术,通过配置工具的方式,让大模型能够根据问题进行自主决策,然后调用不同的工具来完成动态数据的获取。
但使用智能体需要大模型在格式化数据输出方面的能力要求较高,因为其本质上就是让大模型扮演程序员的角色,然后根据工具的要求生成调用参数,并获取结果进行处理。
总之,在大模型应用的道路上,想把应用功能做出来很简单,但能把应用做好却非常不简单。