
“ 智能体的测试和优化,需要根据不同的环境,根据问题不断地进行调整。”
最近几天在测试和优化问答系统,看过之前文章的读者应该都知道最近的RAG系统从被动式RAG改造为主动式RAG,也就是智能体系统。
但是在最近几天的测试中又发现了一些问题,因此需要对智能体进行一些优化;而最主要的问题就是智能体的泛化问题和拟合问题。
智能体的优化
在最近的智能体系统开发中,作者发现了一个问题,事实上实现一个智能体并不难,也没想象中的那么复杂;但难的是把智能体给做出来和把智能体给做好,这是两回事。
至于原因还是因为大模型的问题,由于大模型是通过自然语言与人类进行交互,因此它需要通过自然语言理解人的意思,但我们都知道语言本身就存在很多歧义;再加上大模型本身的不稳定性,这个问题就会被无限放大。
而这就是大模型中最典型的问题——过拟合和欠拟合。
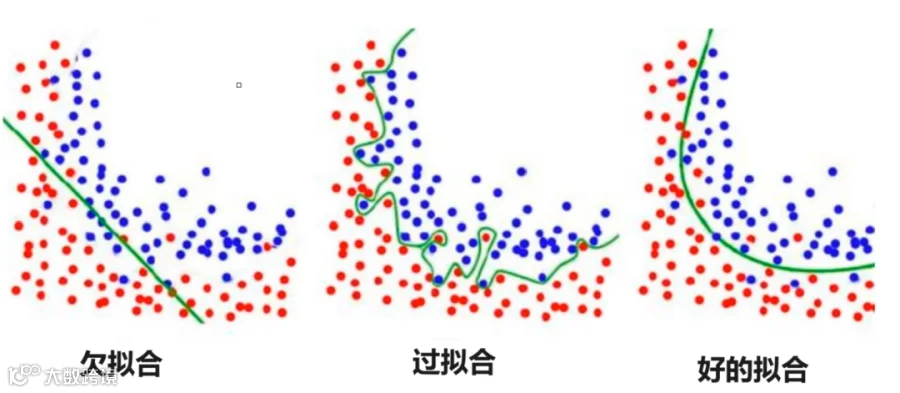
不论是模型的预训练过程,还是模型的使用问题,都会存在过拟合和欠拟合问题;模型训练的数据质量会导致这两个问题,而模型应用中的提示词也会导致这个问题。
所谓的过拟合就是数据集限定范围太严格,就会导致模型的泛化能力不足;而数据集太分散又会导致模型欠拟合,最终变成了四不像。
以作者目前遇到的问题为例,由于智能体本身比较简单,只有两个检索工具,而且两者之间并没有特别重合的地方;因此智能体在大部分场景下运行的都挺好。
但有些问题智能体就会出现泛化能力不足的问题,比如说一些约定俗成的短语或口头语;比如说我想要查一下浙江省的社保情况,你说这时我想查的是浙江省政府的数据,还是浙江省所有市县区的数据?
所以说,遇到这种情况应该怎么办?
说到底出现这种情况本身就是我们在提示词中描述的不清楚,才导致模型不太理解我们到底想干什么;因此,我们需要在提示词中增加一些特殊说明和案例。
比如说我想要浙江省全省数据就是指下辖所有的市县区,而如果只是说浙江省就是指省政府的数据。
但是,这里还有一个注意点,就是这个提示应该加到哪里?
智能体本质上就是模型+工具+提示词的集合;而工具描述本身也属于提示词的一部分,但这段描述加在系统提示词中(system prompt)和加在工具的描述中可能会产生不一样的效果。
所以,智能体的调试本质上还是提示词工程的能力,提示词写的越好,越标准,歧义越少;那么你的智能体就会比别人的智能体强,比别人的智能体更稳定。
但这种问题又没有统一的解决办法,只能进行不断的测试和调整;毕竟从理论上来说,同一个模型的同一个版本,部署在不同的机器上可能效果都不一样。