
“ 文档质量是RAG的生命线,而怎么处理文档是一个技术难题。”
在RAG系统中,文档处理或者说知识库建设是重中之重,但对开发者来说往往会面临着一个问题,那就是怎么处理这样文档?
选择手动处理还是选择OCR/转换工具进行自动化处理?
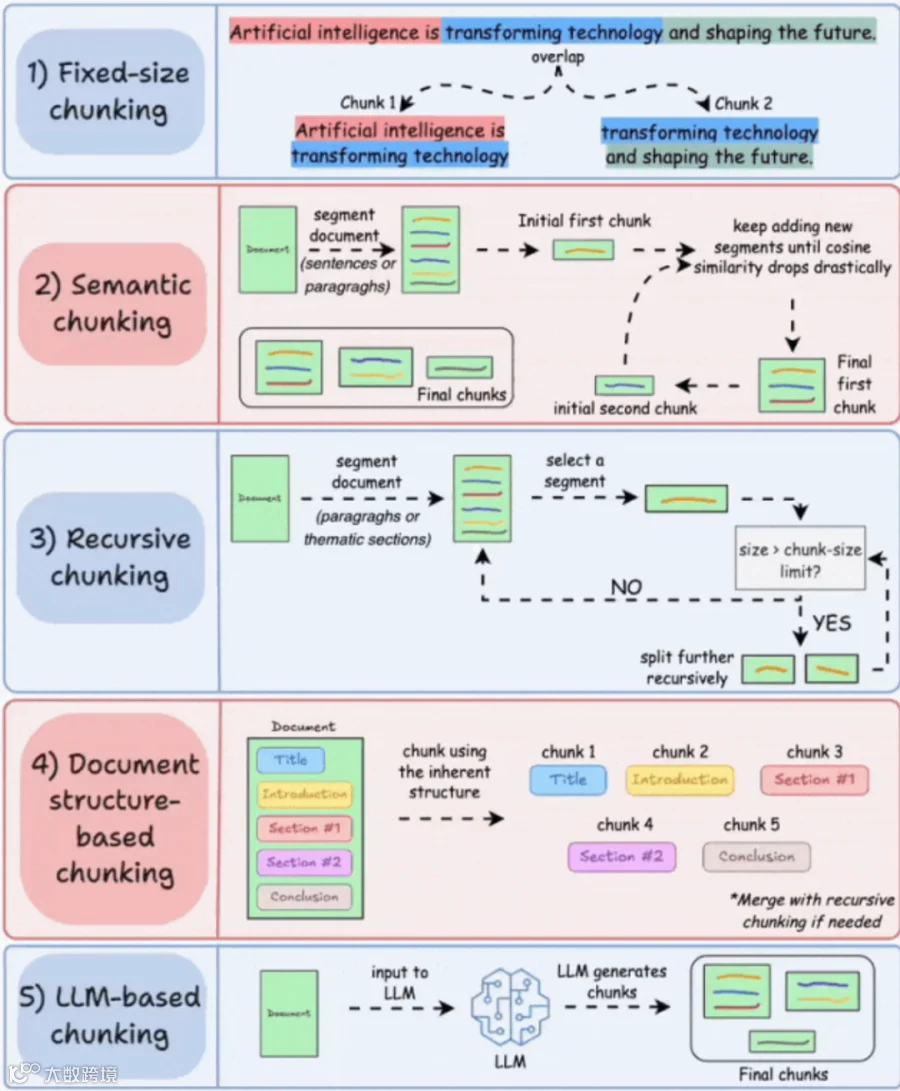
RAG文档处理策略
在RAG中文档处理中,不论是手动处理还是自动化处理,从理论上来说都可以;但两种方式存在不同的优缺点:
手动处理
适用场景:
文档数量少(<100份)
文档质量差(模糊扫描件、手写稿)
对准确性要求极高(法律、医疗文档)
需要深度理解文档结构和专业术语
预算有限但人力资源充足
优势:
✅ 准确率可达99%以上
✅ 能理解上下文语义关系
✅ 可识别特殊格式和隐含信息
✅ 能进行智能分段和标记
✅ 避免自动化工具的常见错误
劣势:
❌ 速度极慢,人力成本高
❌ 难以规模化
❌ 存在人为疏忽可能
❌ 处理过程难以标准化
OCR/转换工具
适用场景:
文档数量大(>1000份)
文档格式相对标准
允许一定的错误率(<5%)
需要快速启动项目
文档以数字文本为主
优势:
⚡ 处理速度快,可批量操作
⚡ 成本相对较低
⚡ 可处理多语言文档
⚡ 容易集成到自动化流程
⚡ 可处理大规模文档库
劣势:
🔧 复杂格式容易出错
🔧 表格、公式、特殊符号识别困难
🔧 上下文理解能力有限
🔧 需要后续校对和修正
🔧 可能遗漏重要排版信息
如果从文档的处理质量上来说,手动处理是更好的选择,因为手动处理过程中所有的环节全部可控,简单来说你需要什么样就可以处理成什么样;但在自动化处理中,对文档质量和格式可能会存在一定的要求,并且效果很难达到你的要求。
所以,在真实的业务场景中,不同的企业由于业务流程和文档的差异,大部分会选择开发自己的文档处理工具;这些工具中可能同时结合了手动处理和自动处理的优势,并根据不同的场景进行适当的优化。
比如说,文档中的表格部分,有些场景可能直接读取表格之后,按照长度等对表格进行拆分;但在有些场景中,可能会选择读取表格之后,使用pandas等工具把表格中的数据读取出来,之后再进行特殊处理。
而这不同的处理方式对应着不同的检索策略,以及业务场景;如果对检索质量要求较高,那么对表格进行读取可能是更好的选择;因为任何多余的数据都会成为影响RAG质量的因素。
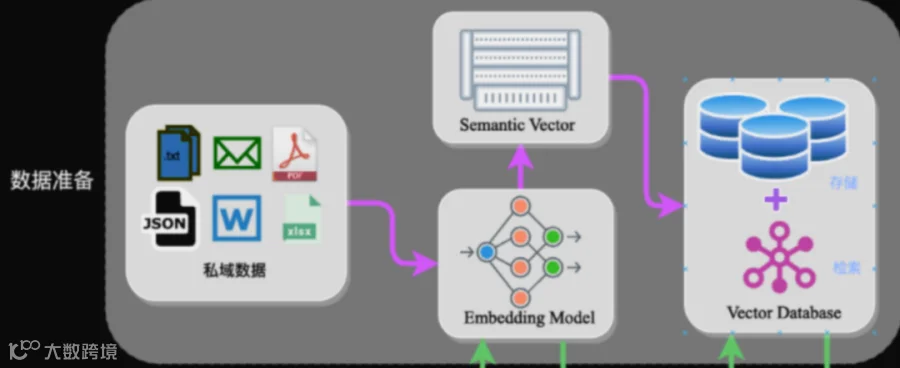
其次,对表格数据进行读取之后可以使用条件查询,而表格拆分之内使用相似度语义查询;这两者之间在准确率上肯定也不可同日而语。
在小企业中由于文档数量较少,要想把产品做的更好,最好选择手动处理;而在大企业中,由于文档数量规模太大,选择OCR或自动化工具效率较高;但在一些对文档质量要求较高的场景中,最好还是手动处理。
但如果有开发能力,并且成本可接受的情况下,可以选择自己开发,把两者的优势结合起来,在不同的地方直接调用即可。