
“ 文档处理在不同的业务场景中需要选择不同的处理方式,而不送一概而论。”
关于RAG的知识库构建或者说文档处理,很多会受限于各种条条框框,比如说应该这样处理你的文档,应该那样建立你的知识库;但事实上知识库的建立没有任何标准,唯一的标准就是怎么让你的系统表现的更好,这是知识库构建的核心。
知识库构建的核心
在学习RAG的过程中,任何人都无法避开的一个问题就是文档处理;因为文档处理是RAG的根基,没有文档处理RAG就是水中月镜中花;但面对真实的业务场景,很多人都不知道该怎么处理文档。
在他们的观念中,所谓的文档处理就是把文档拆分,切片向量化入库即可;但事实上这样的操作虽然没有什么错,但在很大业务场景中好像并没什么用;也就是说你感觉你好像什么都做了,但事实上等于什么都没做,因为没有什么效果。
为什么会出现这种情况?
原因就在于很多人没有明白知识库的本质是什么,建立RAG知识库的目的有两个,一是对文档和数据进行统一管理,二是在检索方面进行优化,能够进行更加精准和高效的检索。
而第二个作用才是知识库的本质作用,毕竟知识库就是为大模型服务的,怎么精确检索才是RAG的核心问题。
因此,在真实的业务场景中,我们需要根据业务需求,文档内容对文档进行适当的处理,然后构建成合理结构的知识库系统;只有这样才能进行更加准确的检索,并实现高效的管理。
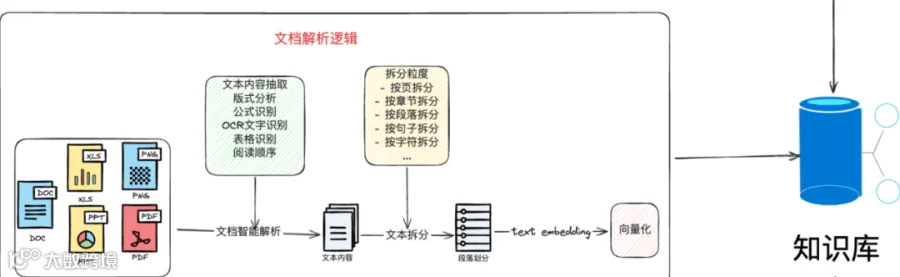
如结构化数据最好是对数据进行元数据提取,比如常用的查询字段,不同维度的字段标识,如部门,地区等;这样在检索时,就可以使用这些字段进行快速且准确的检索。
而对于非结构化数据,我们要根据段落,标题,标点符号等多种方式对文档进行分段,并且在分段之后保留其原有内容做增强生成,而对文档的核心内容进行提取,去除文档中的噪音和无关数据,用来做精确检索,只有这样才能大大提升召回的准确率,并且不影响生成逻辑。
还有,在对文档处理时,我们首先要对文档进行清洗;如过滤掉页眉,页脚,无效字符;同时,还需要适当丢弃部分内容。
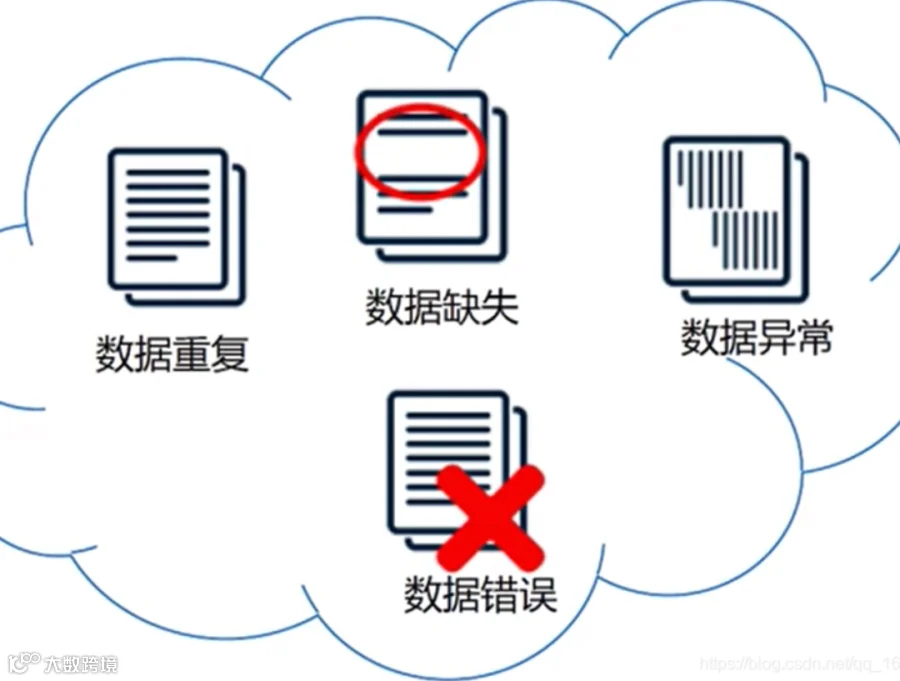
由于真实环境中文档来源的复杂性,导致文档质量参差不齐,因此很多文档中的内容可能只有部分有用;而大部分都是无用数据,因此可以选择丢弃掉这部分数据,原因在于一个好的知识库应该知道什么应该要,什么不应该要,不要因为一颗老鼠屎,坏了一锅汤。
而这就是我们平常所说的脏数据,脏数据的出现不但不会提升知识库的质量,反而会拉低知识库的质量。
当然,最终的处理方式还要根据你自己的业务需求进行适当的调整,而不是机械的照抄别人的处理流程,最后好像所有流程都是对的,但结果却往往不尽人意。