
“ MoE混合专家模型的作用是保持模型容量的同时大幅降低计算成本。”
在我们项目中用了阿里的MoE模型,结尾是A3B,然后在甲方做汇报的时候,一个项目同事不知道A3B是什么意思,就一本正经的说这是智能体参数,只是3B的参数,当时听到这个都惊呆了,这是什么鬼。
虽然没有研究过千问系列模型都是什么意思,但是A3B是智能体参数这个就很鬼扯了;但幸运的是甲方竟然没有人发现,所以之后就好奇查了一下这个A3B什么意思。
在千问系列中A*B模型是有讲究的,其主要跟MoE混合专家模型有关。
MoE混合专家模型
什么是混合专家模型?
可能有些人研究过混合专家模型,但可能更多的人并不知道MoE到底是什么意思;MoE的出现要追溯到上个世纪,但在国内被人所熟知,应该是DeepSeek模型爆火的时候,因为DeepSeek模型就是基于MoE架构开发的。
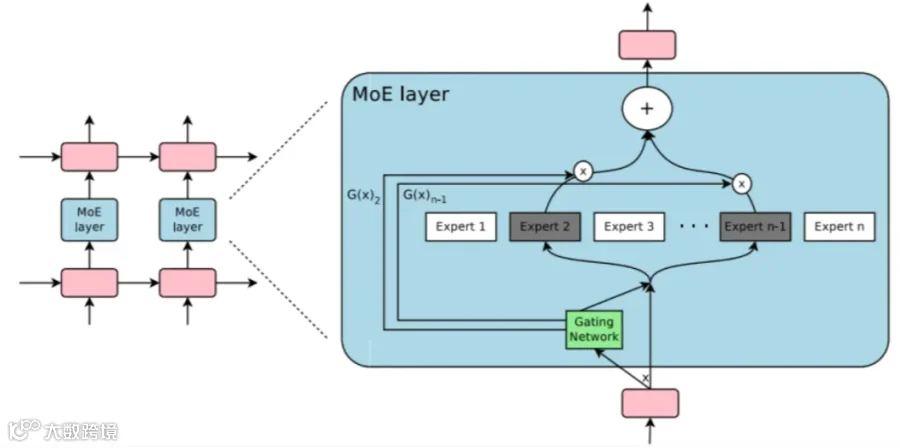
MoE全称是Mixture of Experts——也就是混合专家模型;其在1991年左右由Michael I. Jordan和Robert A. Jacobs等人提出,这一模型的核心思想是通过多个专家模型的组合来处理复杂任务,其中每个专家模型专注于任务的某个特定方面。MOE模型使用一个“门控”机制来根据输入数据的特征动态地选择最合适的专家。
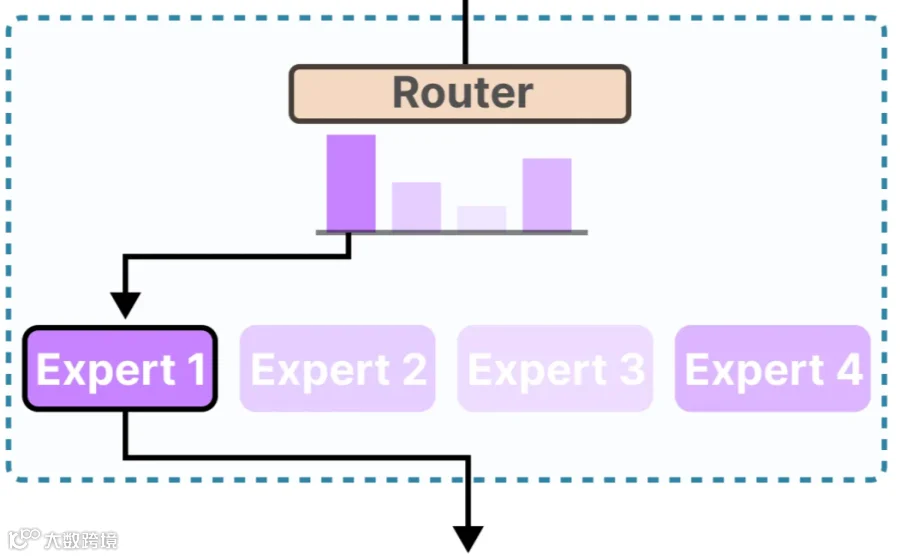
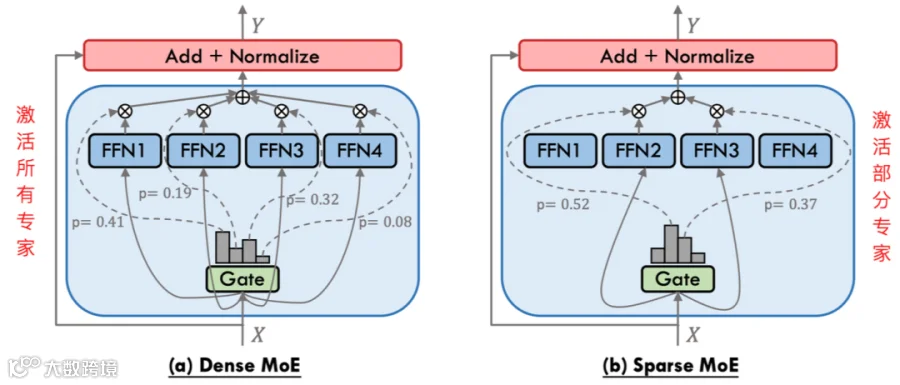
也就是说基于MoE架构的模型,是由多个子模块组成的,每个子模块就是一个“专家-Expert”,每个专家擅长不同的任务,然后在具体执行任务时,只需要与任务相关的专家参与即可,其它专家可以不参与。然后在任务分发时,有一个前置的“门控”来确定需要哪些专家参与,就激活哪些专家。如一个300亿参数的模型,其中某个任务需要3个专家参与,参数量是30亿,那么它的激活参数就是3B。
举例来说,你们班要参加一个学术竞赛,但这个竞赛并不限制具体的学科,因此需要多个擅长不同科目的同学组成一个参赛小组;然后在比赛时,需要根据具体的题目由其中的一个或多个学生参与解题。
在这个竞赛中,你们参赛小组就是一个MoE的模型,其中每个同学就是其中的一个专家,当是物理或化学题目时,可能就需要擅长物理,化学和数学的人参加,而如果涉及到历史,文学类的就需要擅长历史和文学的同学参加;而这时其它科目的同学可以暂时休息,也就是说物理化学需要激活物理,化学和数学专家,历史需要激活历史和文学专家。
这样做的好处就是,可以用更少的资源解决更多的问题;所以,激活参数(Activated Parameters)是混合专家模型(MoE)架构中的核心概念,指在每次推理过程中实际被激活并参与计算的参数子集。这一设计通过动态选择部分专家网络来处理输入,从而在保持模型容量的同时大幅降低计算成本。
毕竟从理论上来说,培养多个擅长不同学科的人,要远比培养一个全能型人才要容易的多。
激活参数的定义与作用
- 动态专家选择
:Qwen的MoE模型(如Qwen3-235B-A22B)由多个专家网络组成,每个输入仅激活其中的一部分专家(例如激活8个专家中的2个)。激活参数即指这些被选中的专家网络的参数。
- 降低计算成本
:例如,Qwen3-30B-A3B总参数为300亿,但每次推理仅激活30亿参数(占总参数的10%),却能实现与更大稠密模型相当的性能。
- 提升效率
:通过限制激活参数规模,模型在训练和推理时的显存占用、计算量显著减少,适合资源有限场景。
激活参数的技术优势
- 混合思维模式
:Qwen3支持思考模式(逐步推理)和非思考模式(快速响应),用户可通过指令(如
/think或/no_think)动态调整激活参数的利用程度,平衡推理深度与速度。 - 优化资源配置
:通过控制激活参数比例,模型可根据任务复杂度自适应分配计算资源。例如,简单问题仅需少量激活参数快速响应,复杂问题则激活更多参数进行深度推理。
开发者如何利用激活参数
- 参数调整接口
:用户可通过API参数(如
top_k、top_p)影响模型对专家的选择,间接控制激活参数规模。 - 部署工具支持
:推荐使用SGLang、vLLM等框架部署,本地工具如Ollama、llama.cpp也支持激活参数的动态管理。