
“ 相似度检索有其天生的缺陷,而这是其自身所解决不了的。”
在日常工作中,你是否遇到过这样的困扰:向智能助手询问「杭州市社保信息的数据」,得到的却是大量与社保相关的政策解读、历史沿革,唯独缺少你真正需要的杭州市具体社保数据?
这背后暴露的,正是当前大热的RAG(检索增强生成)技术在复杂场景下的核心缺陷。
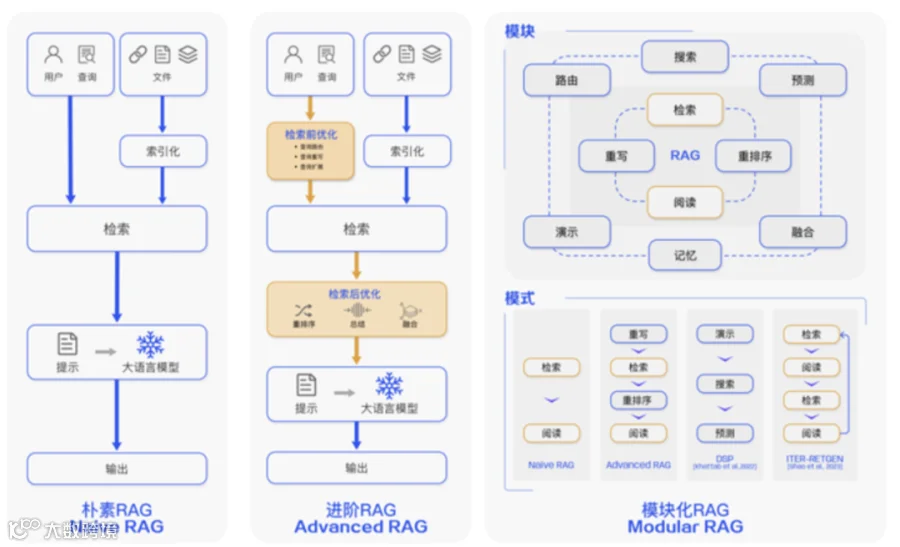
一、RAG的理想与现实落差
RAG的工作原理看似完美:
将用户问题转换为向量
在知识库中寻找相似内容
基于检索结果生成答案
但在条件查询场景中,这个流程却频频失效,如下:
# 用户真实需求:条件查询用户输入:"我想查询杭州市社保信息的数据"# RAG的理解:语义匹配检索词:["杭州", "社保", "信息", "数据"]# 实际检索结果:- 《社保制度的历史沿革》- 《全国社保政策解读》- 《杭州市旅游指南》- 《数据管理方法论》# 用户期望结果:- 杭州市社保参保人数- 杭州市社保缴费比例- 杭州市社保基金结余
二、为什么语义相似度不够用?
1. 条件过滤缺失
RAG基于概率匹配,而非确定性过滤。它知道「社保」和「杭州」相关,却不知道需要将两者精确组合。
2. 意图识别偏差
用户意图是查询数据,但RAG可能理解为解释概念。
3. 结构化数据检索困难
当需求涉及「哪个部门」、「什么时间」、「何种类型」等多重条件时,纯语义检索显得力不从心。
三、真实业务场景中的困境
场景一:企业数据检索
「查询2023年销售额超过1亿的华东地区客户」
❌ RAG返回:销售技巧、华东市场分析
✅ 用户期望:符合条件的客户具体名单
场景二:科研数据筛选
「找出近五年被引量超过100的人工智能论文」
❌ RAG返回:人工智能发展综述、论文写作指南
✅ 用户期望:具体的论文标题和引用数据
四、突破之道:从「纯RAG」到「智能RAG」
解决这一问题的核心思路是:意图识别 + 条件过滤 + 语义检索的三重组合。
五、实施路径:如何构建智能查询系统
1. 意图识别模块
使用微调的小模型进行意图分类
支持「数据查询」、「概念解释」、「流程指导」等多种意图
2. 条件提取引擎
实体识别:自动提取时间、地点、部门等条件
关系映射:将自然语言转换为数据库查询条件
3. 混合检索架构
条件查询:优先执行结构化数据检索
语义检索:作为补充和解释
结果融合:智能整合不同类型的结果
结语
RAG技术无疑为企业知识管理带来了革命性变化,但只有认识到其局限性并针对性优化,才能真正发挥其价值。
当你的智能助手能够准确区分「查询数据」和「解释概念」,当它能够理解「杭州市社保」是一个需要精确过滤的条件而非模糊的语义概念时,人机协作的效率将迎来质的飞跃。
技术的进步,不在于让机器更像人,而在于让机器更好地理解人的真实需求。
看了很多RAG文章,还是不知道怎么下手?代码还是跑不起来?《别再空读理论了!周末两天,用这份资料包亲手搭一个可运行的RAG系统》