
“ 尽量不要去做模型的训练和微调,我们需要做的是学会使用它。”
大模型技术一直被认为是高大上的技术,特别是在模型设计与实现,训练与微调;甚至一些做大模型应用的小公司都会问你能不能独立部署和训练或微调DeepSeek模型。
虽然说从纯粹的技术角度来说,懂得模型的设计原理和基本算法,以及模型的训练和微调方式是一个加分项;但从公司的角度来看,特别是小公司想做模型的训练和微调,这绝对不会是一个好公司,而是一个很大的定时炸弹。
关于模型训练和微调
可能很多人都有一个错觉,所谓的训练和微调就是找点数据,简单处理一下,然后找一些开源或官方的脚本跑一下就觉训练和微调了;但事实上,真正的训练和微调远没有大家想象中的那么简单。
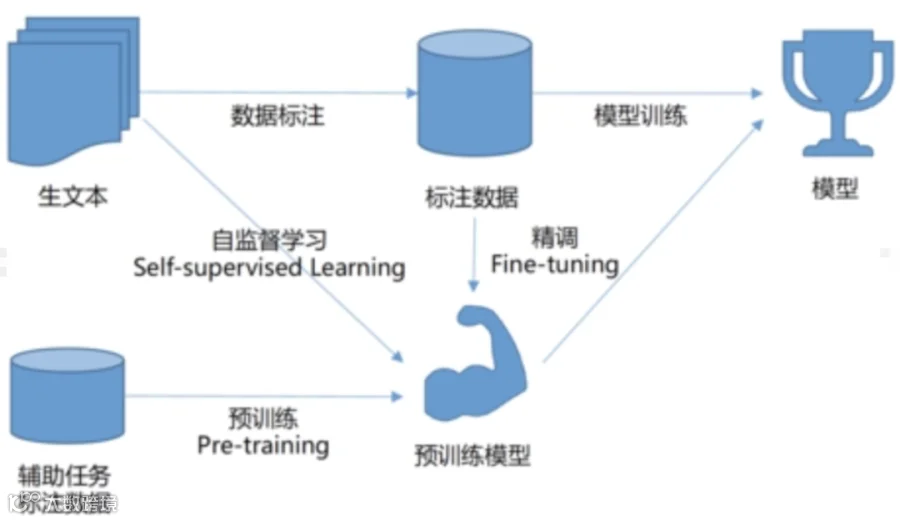
这也是为什么不建议小公司做模型训练和微调的原因。
首先,不同的模型由于设计原理,算法以及对算力的要求都不一样,因此不同的模型或者说同一个模型,在相似的条件下表现也不尽相同。
一个好的,合格的,能用的模型需要经过设计师和开发人员不断的努力,并需要配合大量的数据处理工作,以及可能多次失败的情况下,才能真正训练出一个能用且好用的模型。
否则,像chatGPT,DeepSeek这些知名厂商,也不至于很久才能推出一个模型;而且还只是更新的模型,而不是新的模型。
小公司重新训练或微调模型的风险点在哪里?
小公司做模型训练和微调最大的风险点有两个,一个是技术问题,一个是成本问题;真正想训练或微调出一个好用的模型,需要大量的数据,算力需求,并且需要对模型原理有一定深度的理解,这两者小公司都很难具备。
特别是,即使做好了万全的准备,不论是训练或微调都会有失败的可能,而失败的成本对小公司来说可能是无法接受的。
而即使没有失败,但模型可能也很难达到我们所需要的效果;再有就是,即使表面上看着好像达到了,但它在其它方面的能力可能又被弱化了,而这也可能会导致模型变得越来越笨。
最后还有一点就是,大模型技术目前正处于高速发展迭代的阶段,今天强大且好用的模型,明天可能就会被完全推到重来;所以,这就有可能出现,你辛辛苦苦花费大量人力物力财力训练或微调出来的模型,在还没有开始使用的情况下,就被时代给抛弃了。
这就像chatGPT刚发布时,很多人利用这个机会,开发了大量的套壳工具和产品;然后在chatGPT一次大的升级之后,这些套客工具全都没有用了。
所以,不论从哪个方面来说,小公司做模型训练和微调都是一件吃力不讨好的事情;除非,钱多了烧的。
我能理解小公司想做训练和微调的想法,但这确实不是一个很好的操作建议;他们所认为的训练和微调,就是找一些与业务相关的数据,丢给模型,然后模型就能达到他想要的效果,而这明显是不可能的。