
“ 模型本地部署是运维人员的基本技能,也是开发人员的基本技能。”
在大模型应用中,数据安全问题是很多企业关注的重点,特别是政务,金融,医疗等领域,对数据安全性有着更高的要求。
因此,这时使用第三方模型服务就不再是一个好的选择,而本地部署模型就成了唯一的选择;但是,模型应该怎么部署呢?
本地部署模型
我们都知道大模型由于其庞大的参数和算法,需要进行大量的计算,而为了解决这个问题就需要大量的显卡来提升运算效率。
显卡和CPU的区别就类似于小学生和大学生的区别;计算100以内的加法,不论是小学生还是大学生都可以解决;CPU就类似于大学生,其计算速度快,效率高,计算一百道题可能只需要十秒钟;但如果找一百个小学生,五秒钟可能就搞定了。这就是显卡和CPU的区别,显卡虽然计算效率慢,但我成本低,数量多。
可能很多人多没本地部署过模型,对模型的部署流程也不了解;那么我们就先来了解一下部署一个模型需要哪些环节?
首先,部署模型我们需要有一台算力机,这台算力机上需要配置一定数量的显卡;当然使用CPU部署模型可以,但从效果和成本角度来看,还是显卡性价比更好,效率更快。
而显卡作为硬件,那么肯定需要有驱动,因此还需要安装驱动,目前国内外有很多提供算力的厂商,如华为,阿里云,谷歌,微软等。
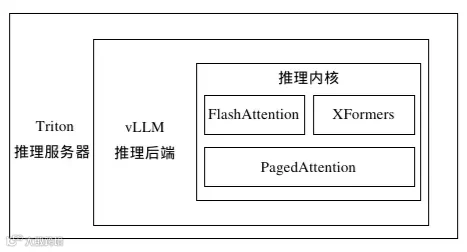
有了显卡之后,还需要有推理引擎,如ollama,vllm,SGLang等多种推理引擎;这些推理引擎的作用是对模型运算环境进行优化,使得其效率更高。
所以,我们在部署模型之前需要先准备带显卡的物理机,然后在机器上安装推理引擎。
当然,理论上来说显卡只提供算力,不针对任何模型,但不同的模型厂商由于商业竞争或其它原因,可能针对某些特定的模型进行优化过;再者,虽然推理引擎也只是为了更好的使用算力,但也由于同样的原因,有些模型只支持在特定的推理引擎上运行。
所以,在选择推理引擎时,我们需要先确定我们需要使用的模型,如果为了简单方便,可以选择一个大部分模型都支持的推理引擎。
在安装完推理引擎之后,就可以下载模型了;下载模型可以选择从模型官网下载,国内的魔塔社区,国外的huggingface等。
建议:如果本地安装模型最好选择使用docker镜像安装,因为其管理比较简单方便,并且不会对宿主系统产生侵入。
# 使用docker部署vllm推理引擎docker run -it -d \--name deepseek \--net=host \--shm-size=8g \--device /dev/davinci0 \--device /dev/davinci1 \--device /dev/davinci2 \--device /dev/davinci3 \--device /dev/davinci_manager \--device /dev/devmm_svm \--device /dev/hisi_hdc \-v /usr/local/dcmi:/usr/local/dcmi \-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \-v /etc/ascend_install.info:/etc/ascend_install.info \-v /llm/models:/models \vllm-ascend:v0.11.0rc1 bash
由此就可以使用docker部署vllm模型。
安装完推理引擎之后,就可以对模型进行部署,如vllm部署模型:
nohup vllm serve /models/Qwen/Qwen3-30B-A3B \--tensor-parallel-size 2 \--seed 1024 \--max-model-len 40960 \--max-num-seqs 25 \--served-model-name Qwen3-30B-A3B \--trust-remote-code \--gpu-memory-utilization 0.95 \--port 5325 \--enable-auto-tool-choice \--tool-call-parser hermes \--api-key xxxx秘钥\> output.log 2>&1 &
如以上命令,在vllm容器内执行之后,就可以在本地部署Qwen3-30B模型,并通过5325端口访问。
学习本地模型部署的目的不是仅仅只是了解模型的部署流程,而是要明白不同的算力平台对模型的支持程度也不一样;而我们在企业级应用中,需要做的是了解不同平台的优劣势,并选择合适的平台。