
“ 长对话是目前大模型应用的一个技术难题,我们只能尽可能的对其进行优化。”
在大模型应用中,多轮对话或者说长对话一直是大模型应用的一个难点;而导致这一现象并不是某个原因,而是一项系统性工程。
而作者最近几天在做长对话测试时就发现,智能体在多轮对话中会出现各种各样的问题,但也没有好的解决方案,因此先在这里做个记录。
智能体多轮对话问题
在做智能体或大模型应用开发时,除非是真正的企业级应用,大部分人都是做个简单的DEMO,把流程跑通就行;因此就会导致一个现象,那就是很多问题测不出来,甚至认为大模型开发把流程跑通了就没问题了。
但事实上,大模型应用开发,把功能做出来只是开始,真正的难点在于效果和稳定性。
而目前长对话就是作者遇到的一个真实场景的问题,经过测试发现当对话超过五轮之后,智能体的性能就会出现严重下降;如不知道调用工具,调用参数不准确,无法理解上下文,答非所问等一系列问题。
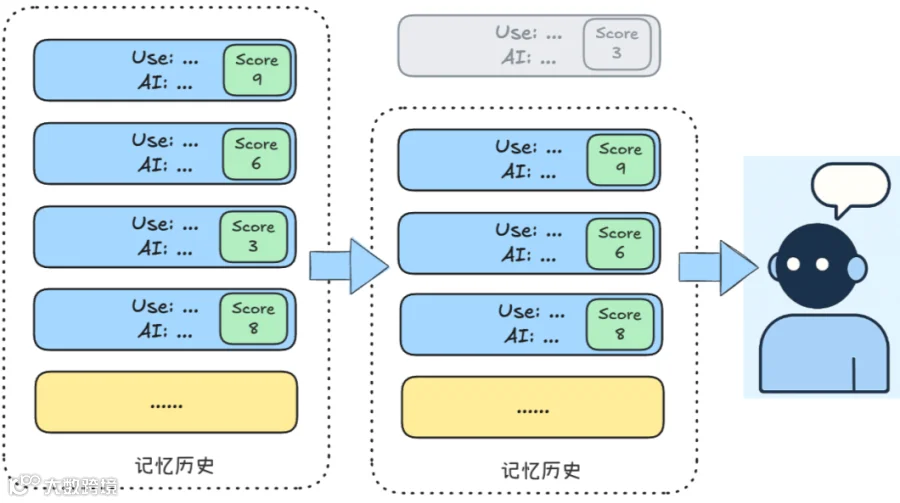
从理论上来说,出现这种问题主要是由于随着上下文的增长,模型犯错的概率就会不断扩大;因此,针对这种情况,一般的解决方案是控制上下文长度,并且尽可能的减少噪音数据对模型的影响。
其次,通过优化提示词,工具描述等方式,来提升模型的泛化能力和工具识别能力。
但经过以上一通操作之后,发现还是达不到想要的效果,上述问题依然存在。
因此,现在还有两个办法一个是通过上下文压缩来保证语义连贯性,其次是替换模型,找一个更大更强的模型。
通过更换模型之后,效果好像是变好了一点,但随着对话轮数增多,还是会出现一些其它问题。
并且,从企业实际角度出发,更好的模型往往意味着更高的成本,或者因为某些原因我们没有办法使用更好的模型。
这时,应该怎么通过工程化或者某种设计模式来解决或者说优化这些问题?
关于这个问题,网上也有一些讨论,但并没有一个很好的解决方案;无非就是,对模型进行针对性训练或微调,比如使用长对话内容作为训练数据,对模型进行强化训练。
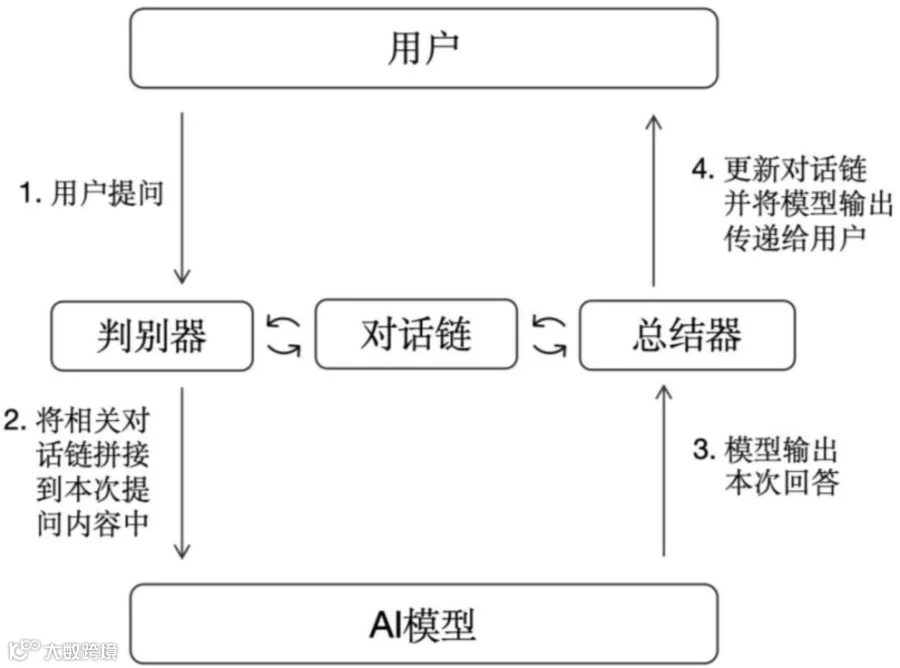
亦或者使用判别模型,对问题和答案进行验证,如果有问题,则让智能体进行动态调整。
但不管怎么说,长对话确实是智能体或者说大模型应用的一个技术难点;如果单纯的从成本和优化的角度出发,作者认为可以通过提示词来优化模型的交互能力,比如遇到拿不准或者搞不定的事,就多引导用户提供更多的信息,使用更准确的描述。
这样,就可以在保证成本的情况下,尽可能的把智能体做到最好。
当然,这个问题可能在以后随着大模型技术的发展而逐渐被解决,但从目前的情况来看,要完全解决这个问题,技术方面还有所不足,存在很大的技术壁垒。