
“ 模型的部署和系统运维是一项复杂的过程,难点是怎么维护一个高可用的稳定模型服务。”
关于模型本地部署,作者经过实操之后觉得好像也没什么难的,下载几个工具,执行几个命令,安装几个包即可;但事实上,模型运维哪有想象中的那么简单。
今天作者就碰到了几个坑,所以今天在这里简单说明一下。
模型部署存在的问题
类似于大模型应用开发一样,把功能开发出来只是第一步,难点在于优化;而对于大模型部署同样如此,把模型跑起来只是第一步,让模型能够稳定的运行才是难点。
作者以个人的经验来简要说明一下部署模型的难点在哪里?
第一,在知道具体需要部署哪个模型的情况下,下一个需要解决的问题就是选择哪个推理引擎;但是在很多模型的说明文档中并没有明确说明可以使用哪些推理引擎,或者说只有很少一部分模型有简要说明。
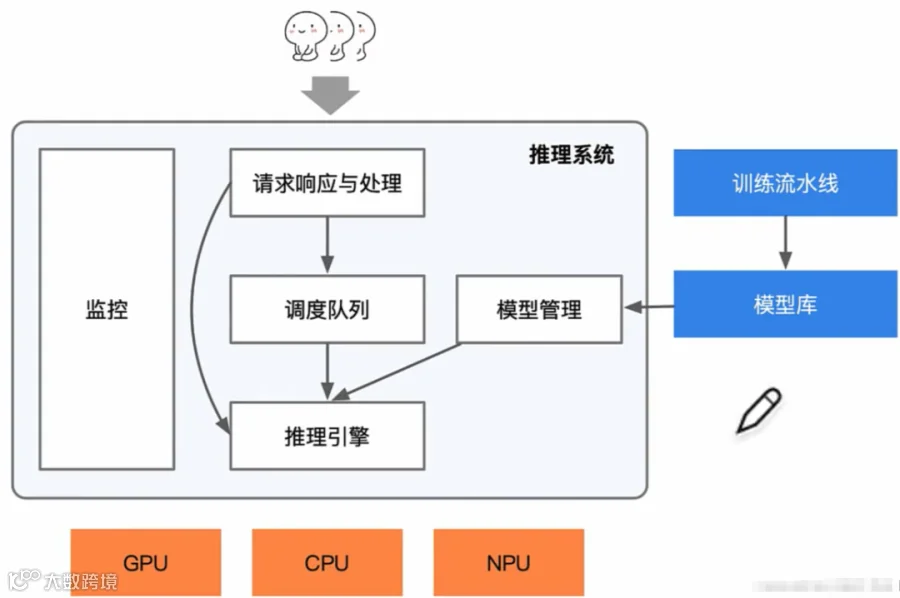
特别是随着时间的发展,模型变得越来越多,在模型托管平台如魔塔,huggingface上托管着几十万个模型;而这些模型支持哪些推理引擎或者说哪些推理引擎支持哪些模型,我们不可能弄得一清二楚,甚至有些模型根本没有适配推理引擎,也就是说不同的模型可能有不同的部署方式。
之所以产生这个现象的原因是,大部分模型开发人员关心的是模型的性能和效果以及算法的实现,而不关心模型的部署问题,除非一些商用模型。
因此一般情况下,模型的部署一般由推理引擎开发人员去适配模型,而不是模型去适配推理引擎,所以这是第一个难点。
最重要的是,有些推理引擎虽然说支持某个模型,但等你真正部署之后才发现,虽然它支持,但需要你对模型进行适当的调整,比如说架构转换,这样才能真正的投入使用。如vllm推理引擎说是支持Qwen3-Rerank-8B模型,但实际上要想使用,需要对模型架构进行转换。
参考如下:https://blog.csdn.net/weixin_52263647/article/details/155536219
其次,模型本身支持的参数,在推理引擎中可能并不支持,对一些推理引擎来说,有些模型的参数使用频率不高,或者兼容性不太好,因此推理引擎就会对模型参数进行适当的裁剪,如放弃一部分参数,这时你按照模型的官方文档进行开发,结果发现部署之后无法使用。
原因就在于,模型开发和推理引擎处于不同的维度,推理引擎对模型进行了适当的封装和处理;所以面向推理引擎和面向模型本身的处理方式也不一样,推理引擎就是加在模型和应用之间的一个中间层。
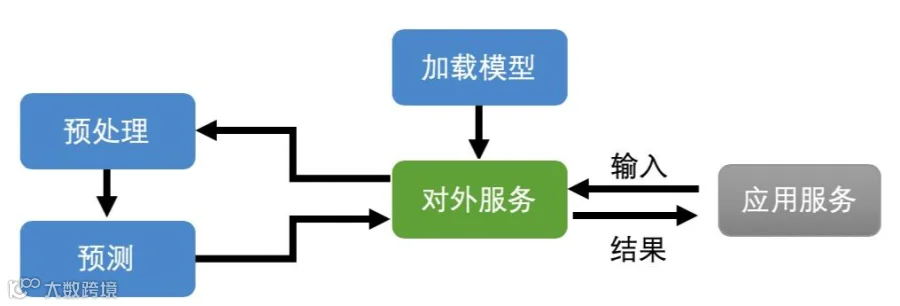
还有,在我们完成模型的部署之后,不论是直接部署,还是使用推理引擎进行部署;我们需要对模型的能力进行适当的封装和处理,这一步是很有必要的。
原因在于,模型有上下文长度限制,并发限制,如果我们不做任何处理很有可能会导致模型崩溃。

以作者为例,今天在部署一个rerank模型时就发现,部署的时候好好的,但运行的时候一直报错,经过检查之后才发现,模型本身默认的上下文长度才512,这个对rerank模型来说是无法接受的。
还有就是,为了提升响应速度我们可能会在接口中直接提交列表进行排序;但列表的长度如果我们不加以处理,肯定会导致模型无法处理而崩溃;所以我们可能需要对提交的数据进行拆分之后,进行分批次处理。
而为了模型的稳定性,防止模型不会因为并发问题而崩溃,我们可能还需要做限流或队列;而这些都是本地部署模型所需要解决的问题。
因此,模型本地部署并不是说你跑起来就完事了,你需要考虑实际场景中可能存在的任何问题。所以,最好的方式是,我们在中间加一层,不直接把模型接口暴露给外部服务,而是经过中间层的封装和转发处理之后,通过中间层去调用模型。