“ 复杂文档解析只有适合的解决方案,没有完美的解决方案。”
在基于RAG的大模型应用场景中,复杂文档解析一直是一个困难点,甚至直接影响到知识库的质量;但目前来看,业内并没有什么特别好的办法来解决这个问题。
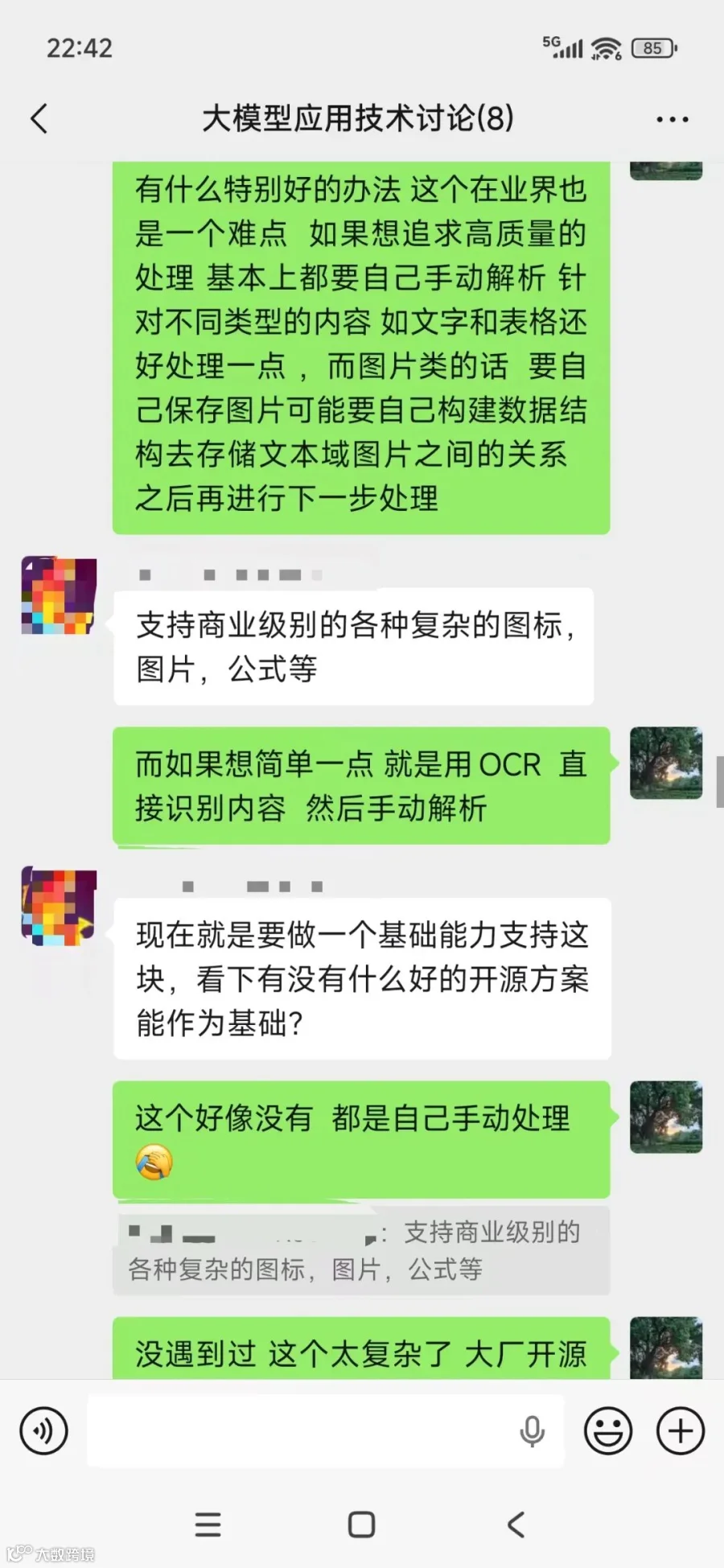
而刚好这周社群中有人问这个问题,并且也是在实际场景中遇到的困难,所以我们就讨论了一下,并且总结了三种方案。
有句话说得很好,既然需求是合理的,那就一定能做。
复杂文档解析
在RAG的应用场景中,包括但不仅限于智能问答,智能客服,搜索等场景;知识库的建设都是重中之重,甚至可以说知识库的质量直接影响到RAG的效果。
而在知识库的建设中,第一步就是文档解析;而文档解析的难点,就是面对复杂的文档类型和内容,怎么高效快速地进行处理,并且不会丢失其核心结构。
而这一点也是目前为止,最困难的一点,特别是以pdf/word等富文本文档,一个文档中可能同时存在图片,表格,文字,甚至是架构图,流程图等复杂格式的内容;如果是做过RAG文档处理的人应该都深有体会。
所以,经过讨论之后,总结了三种方案:
OCR——光学字符识别
OCR学名叫光学字符识别,能够从图片和扫描文档中提取文本数据,但无法保存图片结构或架构图的结构关系;因此一般比较适合处理那种文字和表格比较多的文档。
但也是目前业内比较普遍的一种解决方案,优点是相对比较简单,成本和开发难度相对较低。

多模态模型
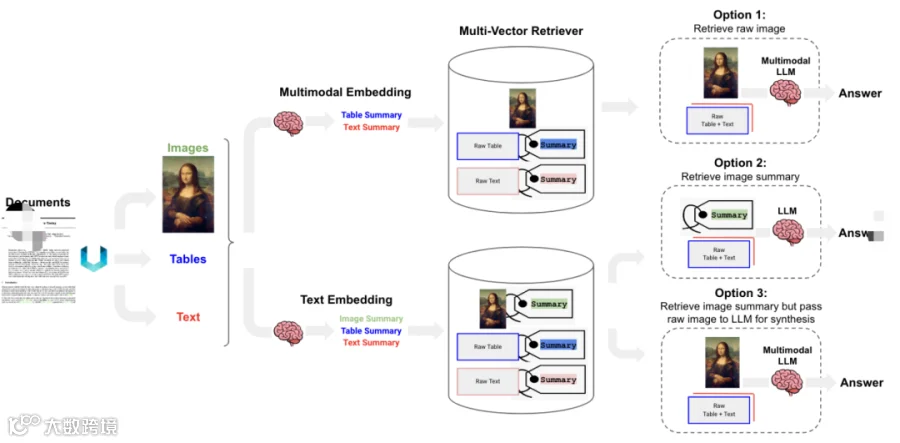
第二种方案就是使用多模态技术,对复杂文档中的内容进行识别,有些多模态模型可以同时识别文字,图片,结构图等内容数据;并且可以对其进行文字总结,有利于进行语义检索。
多模态RAG经典处理流程:
自定义处理
自定义处理一般应用于对质量处理要求较高的场景中,原因在于其开发成本高,难度大,想用相对固定的流程来解决复杂的文档解析问题,其本身就是一个悖论。
自定义处理的实现思路并不是说完全从零开始开发,其实现原理是结合现有的OCR,多模态或其它文档解析工具等技术;对不同类型和内容的文档,提供不同的解析流程和方式,并且在薄弱点进行定制化设计开发,这样就能尽可能的利用这些解析工具的优势,降低开发难度。
总之,在文档解析中,要想做得好就必须根据业务和文档进行开发和调整,而如果想使用通用的处理过程,那么效果就肯定不尽人意。

当然,文档解析是一个复杂的过程,这里也只是简单记录几个解决方案,而且很多问题知道是一回事讲明白又是一回事;所以,这里只是做了一个简单的总结,详细的内容会在社群中继续讨论,并且会记录讨论过程和结果,欢迎大家加入。
想了解社群的,可以查看我想建一个19.9元的“RAG情报站”,你会来吗?
感兴趣的可以扫描作者二维码,并备注 社群 即可。