“ RAG是做出来容易,做好却很难。”
最近这段时间一直有人问我RAG效果不好的问题,然后又没有具体的优化思路,甚至有人想尝试微调模型;但了解之后才发现,在技术上还有很多能优化的点,微调模型实在不是一个好的选择。
然后前两天在社群中又有人遇到在智能问答场景中,文档中的表格数据召回效果不满意,不知道该怎么处理;而这也让我意识到作者之前遇到的问题,现在还有很多人在重现,且不知道该怎么解决。
而建立这个社群的目的,也是为了方便大家交流,并且可以一起讨论,分享一下关于大模型应用中所遇到的问题,并且会不定时的分享一些技术,想法和问题,想加群的朋友可以在文章末尾找到加群方式。
文档中的表格处理
在当前的基于RAG的智能问答场景中,目前大部分人遇到的问题不是不知道该怎么做,而是做出来之后效果都差强人意,原因是很多人都没明白,RAG做出来简单,想做好却不简单。
在传统的技术开发中,一就是一,二就是二,流程对了结果基本上就对了;但在大模型应用中,做出来只是第一步,流程对了并不代表结果对了,所以说RAG的难点不在于开发,而在于优化。
但RAG的优化涉及到很多方面,并不是三言两语就能讲的明白的,而且针对不同的场景,不同的文档类型和内容,还需要进行适当的处理才行,根本没有一个通用的方法来解决所有问题。
而今天我们就以文档中的表格数据为例,提供一个具体的解决思路,即如果文档中存在大量的表格数据,怎么才能使得检索效果达到最好?当然,很多问题在文章中没办法说清楚,在这方面有问题的读者,可以加入社群,大家一起讨论。
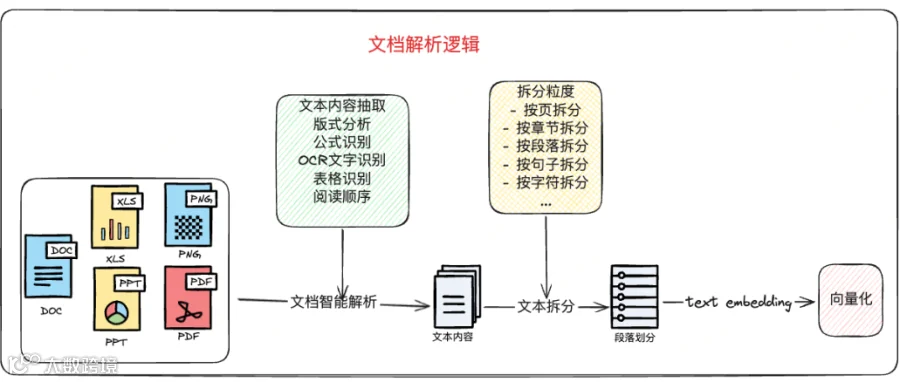
首先,在RAG场景中没有真实实操过的人,可能认为RAG就是把文档内容读取之后,按照固定长度切分入库即可;但作者要说的是,针对不同的文档类型和内容,以及业务需求需要进行适当的处理才行。
以基于知识库的智能问答为例,如果文档中存在大量的表格数据,然后在处理过程中只是进行简单的拆分入库,那么在实际检索中可能很难召回准确的数据,就像社群中的朋友遇到的一样。
所以,针对这种情况最好的方式是,把文档中的表格数据给拆分出来,把其当做结构化数据进行处理。
一是因为表格中的数据如果当做普通文本去处理,由于数据比较分散,语义关联度低,会导致语义召回效果特别差;二是表格数据本身就是结构化数据,使用智能体进行SQL或字符匹配的方式进行精确查询,要远比语义检索效果好得多。
再有,如果真的需要语义查询,表格数据原本的格式会导致数据很分散;这时,我们只需要把表格中的数据,使用pandas或其它库读取之后,按照行和列转换成结构更加紧密的markdown格式的内容,这时再进行语义召回,效果也会好得多。格式如下:
# 表名- 字段1 备注- 字段2 备注- 字段3 备注... ...
而且,前面所说的只是在知识库端的优化方式;在把表格数据提取之后,可以同时保存一份结构化数据到关系数据库中,再保存一份markdown数据到向量库中;这时,我们就可以同时使用SQL查询和语义召回的方式,进行多种召回策略的组合,以此达到更好的召回效果。并且,只需要在最后,对召回的数据做一个简单的去重即可。
从RAG的本质上来说,知识库建设的核心要义,就是能够用更适合,更快更准确的方式召回所需要的数据,而对数据的具体格式和存储方式并没有特定的要求,我们只需要在合适的场景选择合适的方式即可。
加入社群方式:我想建一个19.9元的“RAG情报站”,你会来吗? 一周内可以免费退群。并且,很多在文章中不好讲,讲不明白,以及一些实操案例会在社群中进行分享,讨论,欢迎加入。
或者直接扫描作者二维码,并备注 社群 即可。