
“ 长文处理中,最好的方式就是分步处理,而不是一次性解决所有问题。”
在大模型应用中,长文本处理应该算是一个重点,也是一个难点;原因有二,一是因为大模型上下文窗口有大小限制,二是因为当文本过长时,大模型的处理能力会下降,导致文本丢失或理解偏差。
但不能因为有问题就因噎废食,所以怎么用大模型解决这些问题?
大模型长文本处理
最近作者遇到一个需求,是根据审核结果生成一份专业的审核报告,但由于数据量较大导致上下文超长,因此需要解决这个超长问题。
但是呢又担心一个问题,就是如果每次只给模型一部分数据,模型在进行总结报告时会不会出现理解偏差,即最后给出的报告不准确,当然这个是从业务的角度出发。
但如果从技术的角度出发,由于模型的上下文限制,我们又无法完全一次性把所有数据全部给到模型,这个是由模型的特性决定的,无法改变。
所以,这时候应该怎么解决这个问题?
首先从第一性原理出发,模型的上下文窗口限制是我们无法绕过的一个坎,所以我们只有一个办法,那就是在模型上下文窗口内解决这个问题。
所以,这里我们有两种解决方案,或者说也是一种解决方案。
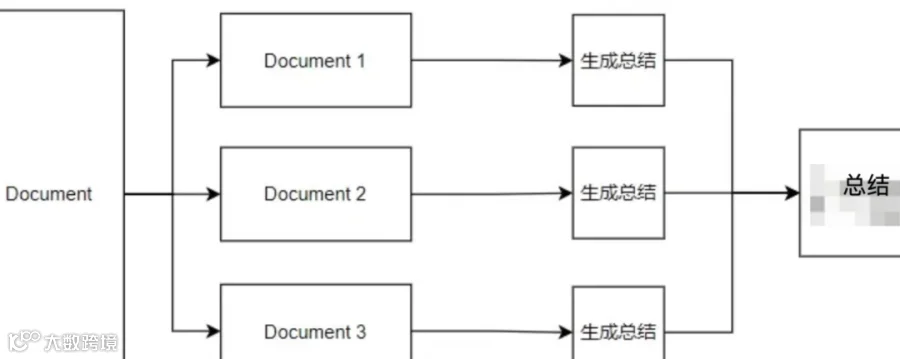
第一,在我们人类自己进行总结报告时,报告的每一部分也是一点一点写出来的;而报告的不同部分使用的数据和内容也不一样。
因此,第一种方案就是通过多次生成,然后拼接成一份完整的报告;即根据报告的要求,生成报告的每一部分都使用需要的数据,不需要的数据直接给过滤掉。这样通过多次生成的方式,就可以生成一份完整的总结报告。
其次,对审核数据进行分批处理,对每个批次的数据生成相应的报告内容;然后再对每部分内容进行总结处理。这样也可以生成完整的总结报告。
但面对这两种方案,我们到底使用哪种方案比较好呢?
从作者的个人经验上来看,其实第一种解决方案更好。
原因在于,一份完整的报告分为多个部分,如概览,详细审核内容,建议,总结等。
其中,每个部分的内容和要求都不相同,即使我们人工处理时,也是先解决第一部分,再解决第二部分,第三部分。
所以,从理论和实际操作上来说,分步骤处理更符合人类的操作习惯,而这一点对大模型来说同样如此。
而且从报告本身的角度来看,报告的有些内容需要模型自主生成,但有些报告的内容是有范式的,简单来说就是有些报告格式和内容是固定的,其中只有一部分内容需要我们进行手动填充,而不是要填充整个内容。
所以说,在长文处理中,一我们需要认清我们的需求,二我们要了解模型的能力极限;不能在超脱模型本身能力的范畴去实现它不可能完成的任务。