“ 多模态RAG是一项非常复杂的系统,需要分布解决,文档解析,嵌入多模态融合,上下文构建等。”
RAG技术虽然还存在很多问题,但基本上已经可以应用于真实的业务场景,并且用来解决部分实际问题;但随着业务场景越来越复杂,多模态RAG也被提上了日程,因为有些场景下单纯的文本解决不了问题。
如各种领域内的设计图,产品图,架构图,单纯靠文字描述很难解决问题;所以才有了多模态RAG,当然多模态RAG并不是一个新概念,而且已经被提出了一段时间;如果单纯从理论上来讲,多模态RAG很简单,只是在之前的RAG上加上了多模态数据,但在真实的工程开发中,多模态却面临着各种各样的问题。
所以,今天我们就来简单记录一下多模态系统是怎么实现的,然后存在哪些问题。
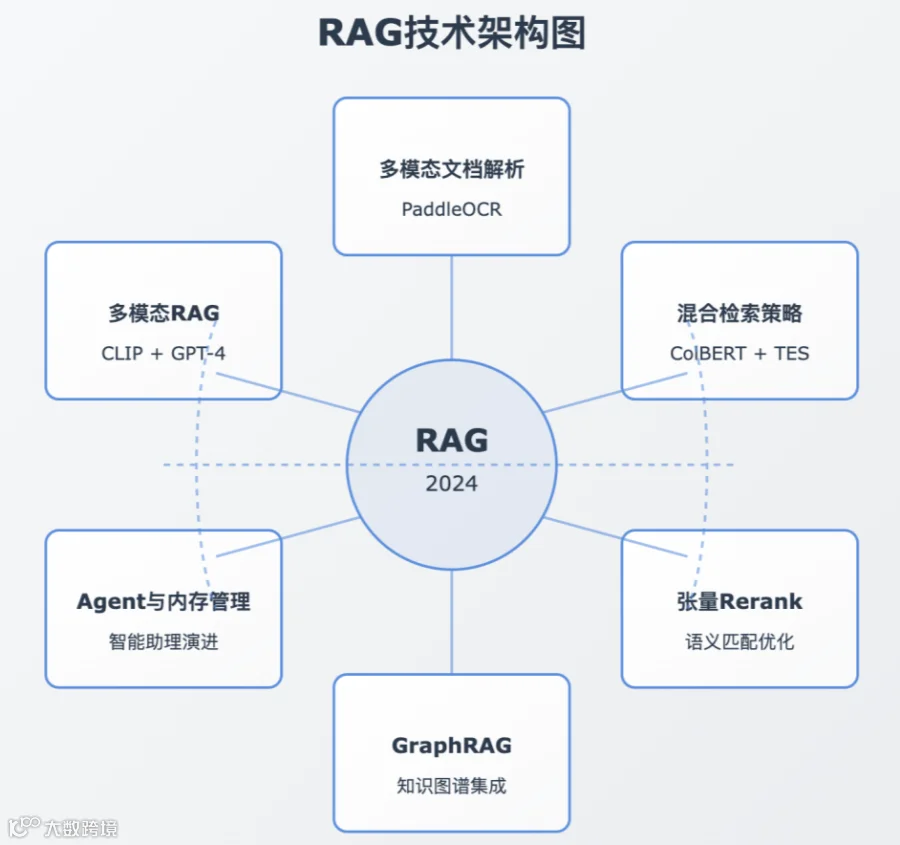
多模态RAG实现流程
多模态RAG既然是在基础RAG之上增加了多模态数据,那么它依然遵循RAG的完整流程,文档解析-->入库-->检索召回-->生成。
而由于多模态数据的特殊性,它和传统的纯文本处理还存在很大的差别;首先,在第一步文档解析,需要把文档中不同模态的数据提取出来,如文本,图片等,然后分别存储,并构建关联关系。
{"file_id": "文件id","page_no": "页码","text": "文本描述","img": ["图片地址", "图片地址"]}
关于文档解析,可以使用多种技术,如使用一些文档处理库,自己手动解析文档中的文本,图片,页码等信息;其次,也可以使用VLM模型进行解析,或者使用OCR技术(解析文本,表格类文档),亦或者是第三方文档解析服务。
总之,文档解析的第一步就是提取文档中不同模态的数据,并保留结构和元数据信息。
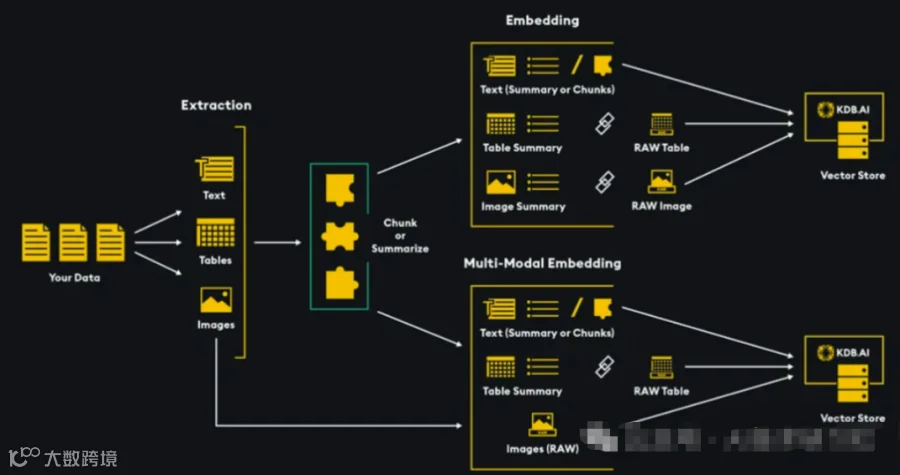
入库与检索
多模态文档入库的目的和传统RAG一样,都是为了进行向量相似度计算;但多模态文档入库有两种方式:
1. 内容提取,转换为文本说明,然后通过文本语义相似度进行检索
2. 多模态嵌入模型,使用模态融合的方式,直接把不同模态的数据转换成同一向量空间进行检索,包括文字,图片,视频,音频等模态数据,经典模型如CLIP。
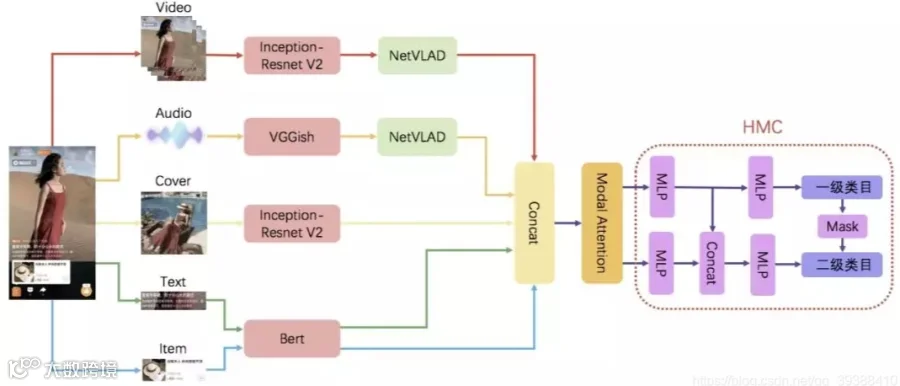
当然,在以后可能还会存在其它方法解决多模态检索的问题,如不同模态的数据分块进行检索,即文本数据用来检索文本内容,图片数据用来检索图片内容,最后把不同模态数据的检索结果进行合并;或者其它新的算法出现。
总之,你用什么样的方法存,就要用对应的方法取;多模态数据涉及到多种算法,包括但不仅限于跨模态对齐,多模态表示,多模态融合等,最终目的只有一个,那就是怎么更好的处理不同模态的数据。
生成
在RAG中检索的目的是为了增强生成,因此生成才是最后一步,也是最重要的一步,否则前面检索做的再好,也没有任何意义。
而在生成过程中,最重要的就是构建上下文,合理的上下文有利于模型理解和生成。
在文本RAG中,上下文构建只需要按照提示词模板,把用户问题,历史记录,参考文档等拼接到一块即可;但在多模态中,因为涉及到多种模态的数据,因此其上下文构建要复杂得多,因为目前多模态模型的接口,都是把文本和图片分开处理的,所以这个对应关系怎么搞。
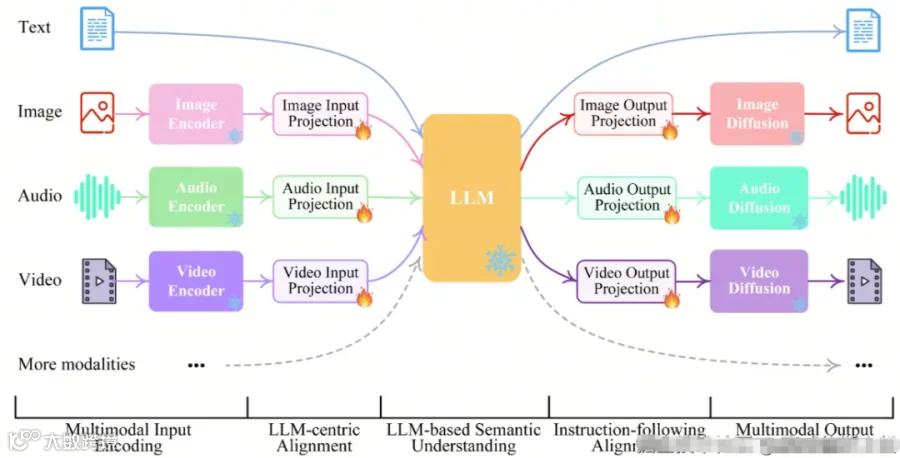
而且,在多模态RAG中,前面的检索和上下文构建好之后,还需要模型的理解和生成能力,这个就需要靠模型自己了;比如说,互联网的产品设计图,和房地产的产品设计图,以及铁路,交通等设计图结构,侧重点都不一样;针对这些特定的行业,可能需要对模型进行适当的训练和优化,否则很难达到想要的效果。
总结
多模态RAG实操要远比理论复杂的多,我们没有办法一次性解决所有问题,只能按照RAG的整体框架,一步一步的解决问题和优化问题,而在多模态RAG中,作者认为最核心的三个步骤就是,文档解析,嵌入和生成;对应的就是智能文档处理,多模态融合嵌入,上下文构建。
其中,对模型来说它需要的是一个结构化的,文本,图片,视频,音频等内容组成的一个多模态上下文;而嵌入是解决怎么存储和检索多模态数据,包括内容总结,多模态融合等技术,解决的构建上下文的数据从哪来,怎么来的问题;而文档解析的目的,是对文档进行拆分,然后方便存储和检索。
本人创建了一个大模型应用学习交流的社群,入群需要缴费19.9,仅此一次不会后续收费,目的是为了防止有人乱发广告,并保持社群的活性;一周内可以免费退群,但乱发广告不退费,并直接踢出。
并且,对RAG或Agent应用遇到问题的企业人员,也可以和作者咨询讨论,作者提供相关的企业服务,详情可以添加作者进一步了解。
如下是社群中问题讨论的内容记录
感兴趣的可以扫描作者二维码: