
“ 上下文管理是大模型应用稳定性的一个重要环节。”
今天在优化智能体的时候发现一个问题,就是智能体第一次思考和工具调用都是正常的,但第二次思考的时候就输出一个think标签就结束了;而且不是因为代码出现异常结束,而是智能体输出了stop结束符。
所以,这个问题就很奇怪,代码都是正常但智能体执行一般就正常结束了;哪怕是出现异常导致结束也没问题,但这种正常结束好像就没那么好排查了。
所以,经过测试发现复现的频率还挺高,之后经过多轮复现之后发现,问题大概率是出现上下文窗口上,上下文超长导致模型正常终止。
而出现这种问题,归根结底就是模型的上下文管理有问题,再准确点说就是模型历史记录没做好。
智能体的历史记录
在Langchain的技术体系中,记忆或者说历史记录有两种实现,一种是基于Memory的大模型记忆功能;另一种是Langgraph中的检查点,利用MemorySaver进行记忆存储。
从记忆的持久性上又分为本地存储和外部存储(如redis)的方式,但不论哪种方式本质上都是把对话内容保存下来,供后续拼接到上下文中。
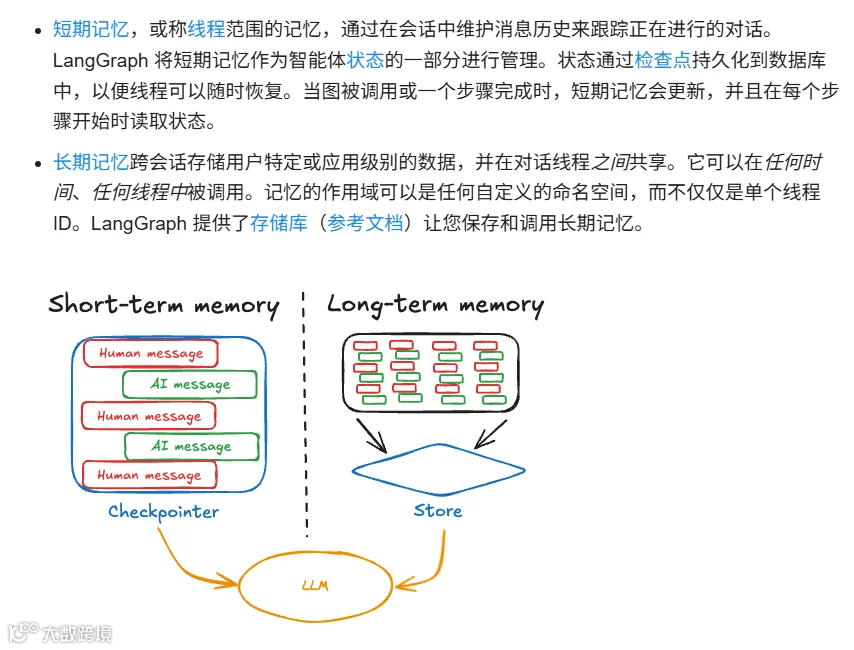
而作者这次bug出现的原因就在于记忆没有管理好;导致上下文超长,最后模型结束。
多说一句,上下文管理是模型应用中的重要环节,原因在于任何模型都会有上下文窗口限制,并且不同的模型上下文窗口大小不同;并且,其理论窗口大小并不是最优窗口大小。
举例来说,现在最新的模型上下文长度能达到128K,但其最优长度可能只有100K或者更少。
所以,怎么管理模型上下文?
模型上下文一般由以下几个部分组成:
用户问题
历史记录
参考内容
系统提示词prompt
而其中系统提示词的长度基本上是固定的,用户问题的长度也有限;因此,上下文超长的主要原因基本上集中在历史记录和参考内容上。
其中历史记录会根据存储的数据和对话次数的增大而不断增长;参考文档也因为不同的文档切分和拼装方式,导致其长度不固定。
所以,一般情况下会对历史对话的轮数,以及参考文档的数量进行限制;防止上下文超长。
但在Langgraph中,哪些东西有可能被存到历史记录中?
事实上在系统中,那些内容被存到历史记录中这个是完全可以由开发人员控制的;但在langgraph中已经实现的记忆存储中,会把messges中的所有数据都存到记录记录中。
但这在某些场景下是有问题的,或者说在大部分场景下都是有问题的;比如说,具备思考模式的模型,以及工具调用的结果,其实这些内容是不需要被存储到历史记录中的;这玩意就像在开会时,做会议纪要,只需要把每个人说的内容记下来就行,而没必要把别人怎么想的也记下来。
因此,这时就需要在记忆模块把思考过程和工具返回的结果给过滤掉,最终只记录对话过程中的问题和回答。
class TrimmedInMemorySaver(InMemorySaver):"""带自动裁剪功能的 InMemorySaver(LangGraph v0.2+ 兼容)"""def __init__(self, max_tokens=3000, strategy="last", *args, **kwargs):super().__init__(*args, **kwargs)self.max_tokens = max_tokensself.strategy = strategydef put(self,config: RunnableConfig,checkpoint: Checkpoint,metadata: CheckpointMetadata,new_versions: ChannelVersions,) -> RunnableConfig:thread_id = config.get("configurable", {}).get("thread_id")if not thread_id:return super().put(config, checkpoint, metadata, new_versions)# 尝试从 checkpoint 中提取 messages(根据你项目 checkpoint 结构调整)messages = Noneif isinstance(checkpoint, dict) and "channel_values" in checkpoint:messages = checkpoint["channel_values"].get("messages")elif isinstance(checkpoint, dict) and "messages" in checkpoint:messages = checkpoint["messages"]logger.info(f"InMemorySaver中的messages: {messages}")# logger.info(f"InMemorySaver中的messages过滤之后的messages: {messages}")""" list 类型 BaseMessage messages.type """if messages:fliter_messages = [messagefor message in messagesif not isinstance(message, ToolMessage)]logger.info(f"记忆去除toolmessage: {fliter_messages}")# 关键:传入 token_counter(这里用近似计数器)trimmed_messages = trim_messages(fliter_messages,max_tokens=self.max_tokens,strategy=self.strategy,token_counter=count_tokens_approximately,# 可选:保证以 human 开始并以 human/tool 结束以确保消息序列有效# start_on="human",# end_on=("human", "tool"),include_system=True,)logger.info(f"trimmed_messages之后 记忆去除think标签和toolmessage: {trimmed_messages}")# 写回裁剪后的 messages(视 checkpoint 具体结构)if "channel_values" in checkpoint:checkpoint["channel_values"]["messages"] = trimmed_messageselse:checkpoint["messages"] = trimmed_messages# 继续调用父类的 put 执行真正保存return super().put(config, checkpoint, metadata, new_versions)
这样,一是可以大大减少思考过程和工具调用结果对模型的干扰,其次是可以控制历史记录的长度,防止上下文超长带来问题。
通过这样的方式,就可以避免模型上下文超长问题,但同样也会导致部分记忆丢失;这时只能要想尽可能的保存记忆,那就只能对记忆进行压缩。
但不论怎么样,只要上下文窗口限制还在,那么就永远无法避免记忆丢失的问题。