
“ 多模态和自然语言处理模型既有算法上的区别,又有本质上的联系。”
在大模型应用中,目前在RAG和Agent方向主要使用的是自然语言模型;但在大模型领域中还有一种很重要的模型是——多模态模型。
而且在RAG中也有多模态RAG,所以,今天我们就主要来讨论一下多模态模型。
多模态模型
多模态模型虽然发展的有几年时间了,但在实际应用场景中接触的一直不多,可能大部分人接触多模态模型是在AIGC领域,用来生成一些图片,音视频等内容。
所以,作者一直很好奇如果用多模态模型做RAG应该怎么搞,文搜图和图搜图的区别是什么?是否能够通用?
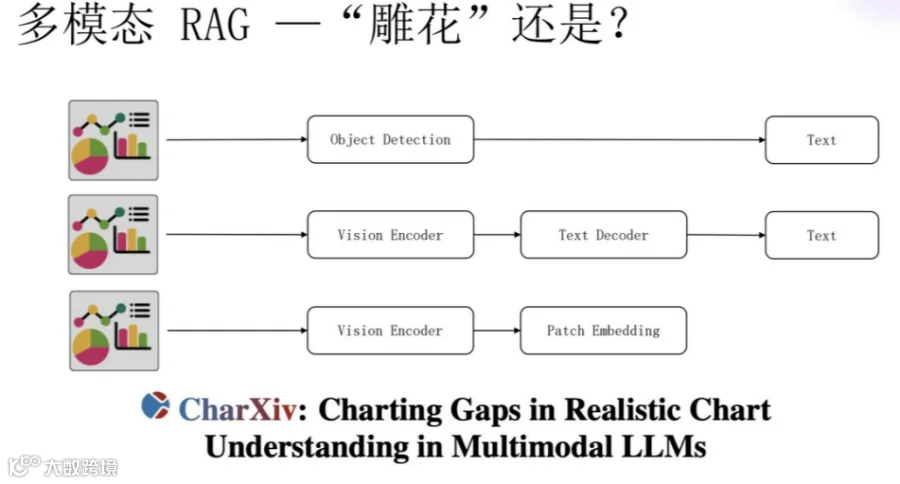
在RAG中,大部分情况下都是以文字处理问题,也就是基于自然语言的对话,通过条件检索或语义检索的方式实现;但这里有个问题就是,如果文档中存在大量的图片怎么办?如架构图,设计图等。
所以,在了解了一部分多模态RAG的知识之后发现,实现多模态RAG检索的原理是:通过多模态模型如Clip模型,提取图片中的主要内容,并转换成文字描述,这时就可以实现文搜图的功能。
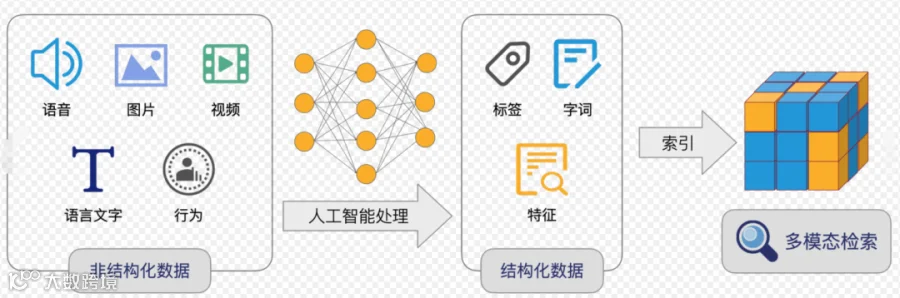
所以,多模态RAG的核心原理是,通过对图片进行文本总结,然后进行语义检索,最后召回图片内容。
但这里有一个小问题,就是图片毕竟是图片,哪怕进行文字描述也很难完全概括图片中的内容,特别是让多模态模型自己对图片内容进行总结,这时可能会丢失大量的图片信息,导致召回不准确。
但多模态模型也没有大家想象中的那么简单,所以才有文搜图和图搜图的区别;文搜图就是上面所说的用文字对图片内容进行总结实现语义检索,那图搜图是怎么实现的呢?
在图搜图中,是把图片内容转换成向量,当需要进行图搜图时,只需要把用户的图片也转换成向量就可以实现相似度检索,其功能就类似于文本检索中,对知识库内容和用户问题进行Embedding嵌入,然后进行相似度计算。
这样就可以绕开图片转文字的过程,大大提高图片检索的准确率。
当然,虽然文搜图存在一些问题,如检索结果可能不准确,但在基于自然语言对话的场景中,只能通过文搜图的方式进行数据召回。

因此,针对文搜图和图搜图的特点,两者的应用场景也有所不同;在RAG中一般使用文搜图的方式,而在一些搜索场景中,就可以使用图搜图的方式,如物体识别,电商APP的搜索功能等。
同样,针对视频的搜索原理也是如此,如果针对视频进行搜索,其基本原理和图搜图差不多;通过对视频进行关键帧提取的方式,来获取多个视频的关键帧,也就是图片;这样就可以实现视频搜索的功能。
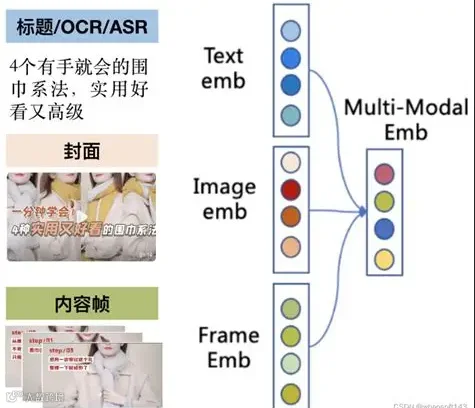
而各大视频和图片网站,在针对图片和视频审核时,就是通过这个原理实现的;当,图片或视频中包含某些敏感信息时,就对这些图片或视频进行限流或删除操作。
自然语言模型和多模态模型,在原理上虽有差别,但本质是一样的;只不过文字和图片,视频的表示方式不同,导致其最后处理的流程不同。
如在自然语言处理中,针对文字会构建词汇表,针对图片会处理其像素矩阵,而针对视频又会提取关键帧,也就是图片进行处理。