“ 你知道怎么在真实的业务场景中用标量检索提升RAG的效果吗?”
很多新手刚开始做RAG的时候,都会有一个误区,那就是既然是基于语义理解的智能问答,那么直接使用向量数据库做语义召回即可,也就是相似度检索。
你是否也在RAG场景中全部使用语义检索,以为只要把文档切片并使用embedding向量化,即可解决所有问题。但是,在实际的业务场景中却发现,很多时候单纯使用语义检索效果好像并不好。
这是什么原因呢?
原因在于你只知其然,而不知所以然,因为你只知道向量检索。
学会使用标量能大大提升你RAG的准确率
举个简单的例子,比如用户问:2026年杭州市政府人才补贴政策有哪些?
很多人只知道做chunk,把问题向量化,然后使用相似度检索进行召回;最后发现召回的数据要么上过期的,要么是相关但不准确的内容。
实际情况可能是,我想要的是2026年的人才补贴,然后召回的却是:
2025年或之前的旧数据
其它地区的政策
家电补贴等
然后更离谱的是,模型还回答的一本正经。
这时,你就开始怀疑,是不是我那个技术环节又出问题了?是embedding模型没选好,还是文档切片有问题?
但问题可能并不是向量问题,而是你没有做“条件过滤”。

事实上很多人理解的向量检索,其实只理解了表象——找语义相似的内容。
但真实的业务场景中,很多问题中除了语义之外,还天然携带了很多过滤条件。
地区
部门
文件类型
状态
权限
数据来源
而这些条件更适合传统的条件查询,而不是语义检索。
原因在于哪怕你chunk和数据清理的再好,它也会存在部分噪音数据;再有就是,语义本身就不准确,因为它是有歧义的。
所以,如果用标量做查询会有哪些好处?
比如用标量做检索,也就是用metadata做过滤条件,如:
year=2026
city=杭州
type=人才补贴
这样经过精确过滤的数据,肯定要比语义检索效果好;而且在此基础之上,还可以继续做语义检索,这样经过多重过滤的方式肯定比简单的语义检索更加准确。
但真实项目里,metadata并不是天然存在的。尤其很多企业数据:
PDF没有结构
Word标题混乱
Excel字段不统一
OCR还有乱码
这个时候,metadata本身就需要“加工”。
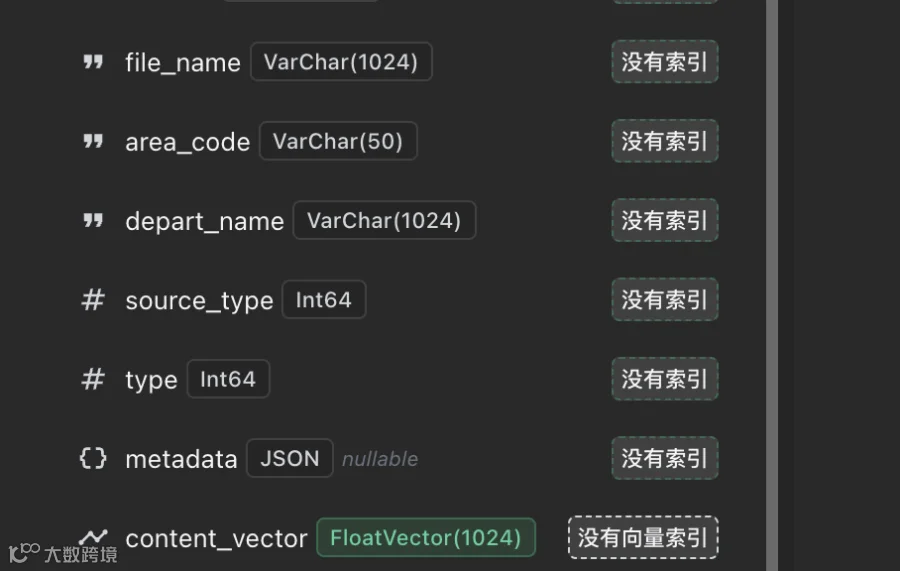
那么这些做标量检索的metadata数据从哪来呢?也就是怎么加工出来的呢?
这个元数据来源可以有多种方式,如果你的数据源是标准的结构化数据,比如来自数据库表结构,那么这种数据格式天生支持标量检索;而如果你的数据是一些word/pdf文档,那么你可以通过模型或者关键字提取的方式获取元数据做标量。
从RAG的角度来看,语义检索应用范围最广,可以直接任何格式的数据;但标量数据最准确,因为某些场景中用户要的不是语义接近,而是条件正确。
因此,经过这么长时间的RAG开发,我发现RAG的效果更多拼的不是模型能力,也不是embedding能力,更不是prompt提示词。
RAG效果最终拼的是,并不是接模型,因为模型随时可以更换,而是怎么把混乱的数据,变成模型能理解的数据;也就是谁数据处理做得更好,谁更懂得组织数据。
给不同格式,不同类型,不同模态的数据选择合适的处理方式和组织结构,比你单纯的去做技术优化效果要更好。
真正文档的RAG,并不是简单的只靠向量,而是:
标量过滤+向量召回+业务规则多个角度共同作用的结果。
如果你最近也在做企业知识库,或者遇到:
明明有内容却召回错误
新旧政策混乱
不同业务数据串库
回答似是而非
RAG效果始终不稳定
那你可以回头看看,是不是你的数据,从一开始就没有做好metadata设计。
当然,也欢迎有问题的朋友添加作者微信一起交流。