“ 知识库问答的难点从来不在系统开发,而在于持续优化。”
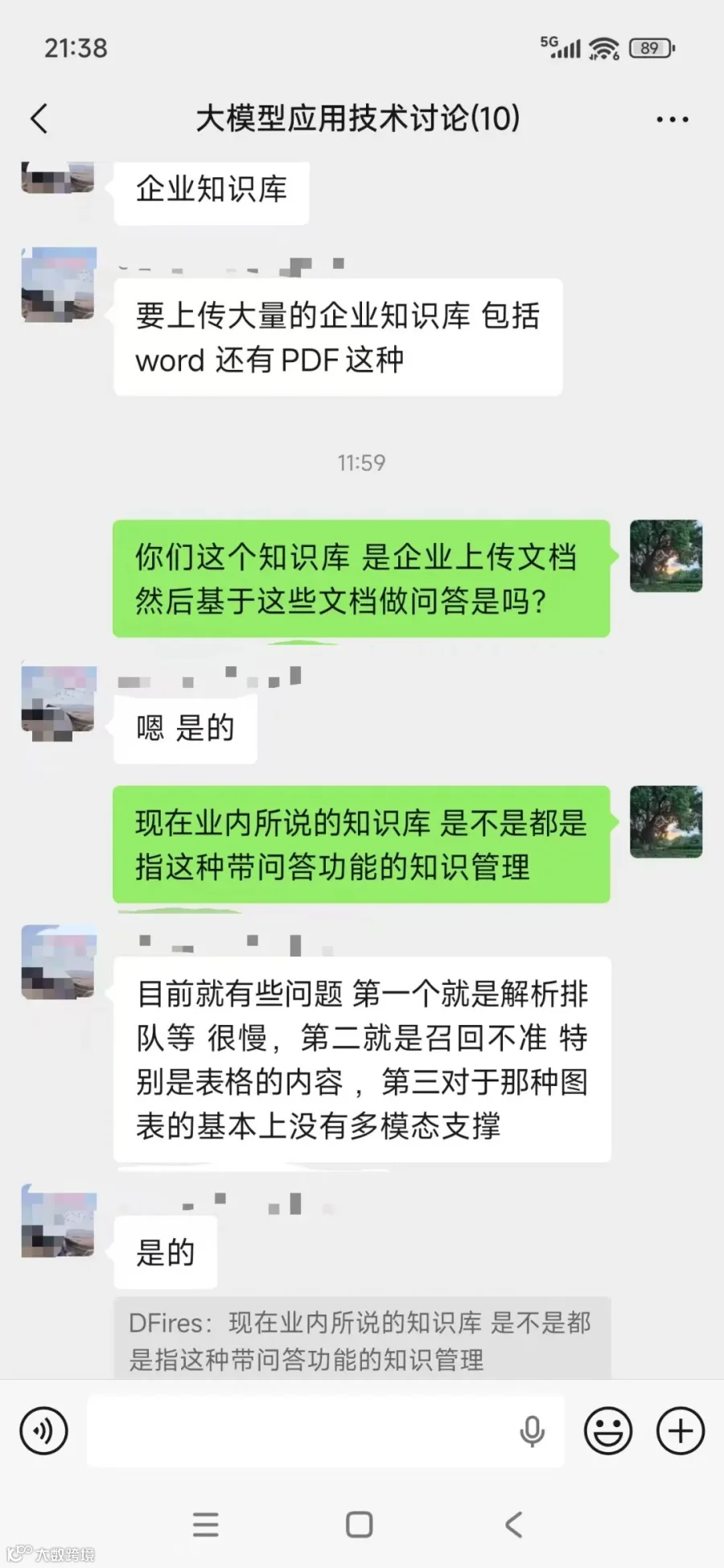
随着社群里的人越来越多,再加上这几天的讨论,慢慢发现一个共同点,就是大部分人的问题都围绕着知识库的智能问答为核心展开;而最常见的问题主要有两个,一是文档不知道该怎么处理或处理效果不好;二是召回效果不好。
而这些归根结底就是一句话,RAG系统的优化问题,这个即是个人学习者所面临的问题,也是很多企业所面临的问题。
知识库问答问题检查
在之前的文章中,作者强调过一句话,就是大模型应用流程对了,并不代表结果也对了;大模型应用难的不是做出来,而是做好。
这一点在目前很火的知识库产品中有着很好的体现,而且作者发现虽然说智能体是大模型应用的未来,但目前对很多中小企业来说,知识库依然是必然的一个选择。但受限于技术,算力等问题,他们在产品开发中又面临着各种各样的问题。
目前市面上的问答系统实现方式主要是以下三种:
1. 使用第三方框架搭建一个问答系统,如coze,dify等
2. 基于一些开源知识库系统做二开,如ragflow,mineru等
3. 自己借鉴别人的思路做定制开发
但不管使用哪种方式,对这些人来说都面临着同样的问题,具体表现就是效果不好;当然,导致问答系统效果不好的原因有很多,也不是三两句话能说明白的;但至少我们要有一个基本的思路,问题大概出在那地方,应该怎么查,因为作者就遇到过效果不好,但不知道该怎么优化的用户,甚至想直接微调模型。
首先,要想知道问题出在哪里,要先明白整个系统的流程是什么样的,然后才能做到对症下药,优化流程中的细节问题。而基于知识库的问答,基本上都是基于RAG的思想实现的,而RAG拆分开来主要由三个子模块组成。
1. 知识库的建设,主要就是文档处理入库
2. 检索策略,什么样的数据适合什么样的检索策略
3. 上下文管理,用合适的结构组织数据
其中1和2的关联比较紧密,3相对比较独立,因为1和2可以使用任何方法,任何技术,并且其会互相影响,而唯一的目的就是准确快速的召回数据。
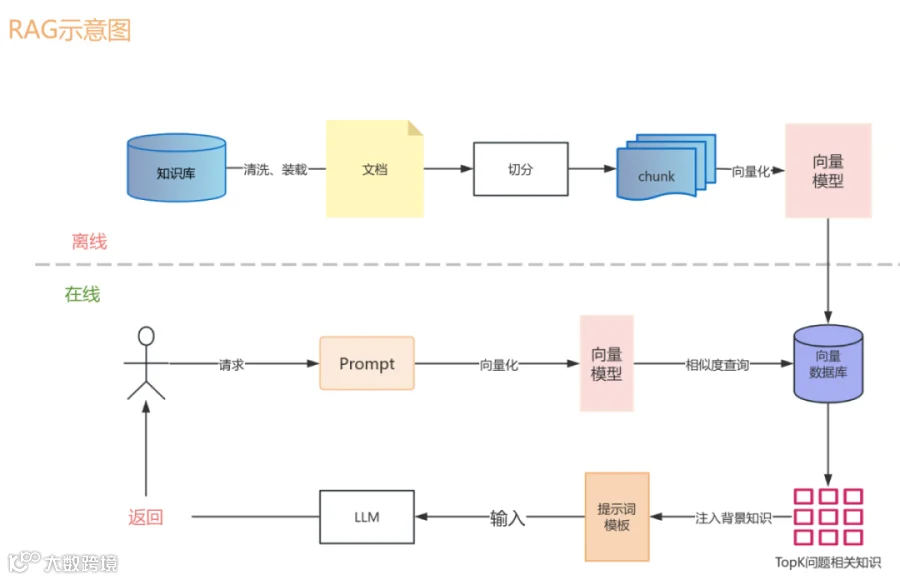
比如,文档解析做得不好,导致文档切片不合理,丢失大量的重要数据,或者数据清洗效果不好,导致知识库中存在大量噪音数据;这些会直接导致召回效果变差,需要的数据召不回来,召回的数据又乱七八糟不利用模型生成等问题。
而目前难点主要集中在两个方面,一是文档解析,二是数据召回。
其中,文档解析由于文档本身的复杂性,一直是RAG中的一个难点;二是在召回侧,不知道有哪些召回策略,也不知道不同的召回策略应该怎么优化等问题,比如说小块召回,大块生成,可能有些人知道是怎么回事,但更多的人根本不理解这句话啥意思。
在文档解析端,不管是自己开发还是使用一些开源框架,针对不同的文档内容需要使用不同的策略;如OCR,多模态,或者针对文档处理优化过的小模型等。如mineru就使用了很多优化后的小模型做文档解析。

当然,RAG的优化过程是一个复杂的过程,需要针对特定的场景做特定的优化,最忌讳的就是想用一个同样框架解决所有问题。
而且从社群来看,很多企业为了快速开发,节省成本,直接使用三方开源框架,还想达到想要的效果;只能说这是不可能的,因为框架需要的普适和通用,而不同的场景需要特定的处理,从这一点来看它们是相悖的。
所以,知识库问答的难点一直都不是系统开发,而是怎么优化。
因此,欢迎更多的小伙伴来加入我们的社群,大家遇到问题一起讨论,一起解决;重要的不仅仅只是解决问题,重要的是记录我们解决问题的思路。
当然,针对企业用户想快速查找问题,优化产品,本公众号也提供企业咨询和培训服务,有需要的企业负责人或技术开发者也可以加作者微信联系。
加作者微信最后备注一下,如社群或企业咨询,这样作者才能知道你需要什么。