
“ 搜索技术是RAG的核心组成部分,没有搜索就不存在RAG。”
说到RAG检索增强,很多人都知道它是和大模型应用有关的技术,而且网上也有很多介绍RAG的文章和代码;作者在之前的文章中也介绍过RAG的本质并不是指一项具体的技术,而是一种方法论;因此,RAG更像是多种技术的组合体。
RAG——中文名称叫检索增强生成,其实RAG是由两部分组成,检索和增强生成;检索类似于传统的搜索技术,而增强生成才是和大模型相关的内容。
检索增强生成和搜索
RAG检索增强生成的目的是为了解决大模型的缺陷问题:
知识更新不及时
模型幻觉问题
知识时效性问题
所以,为了解决这些问题,在模型进行生成之前,先使用搜索技术从外部知识库中检索到与问题相关的内容,然后再用这些内容构建上下文,交给大模型,让模型根据这些外部知识进行内容生成,这就达到了检索增强生成的目的。
为什么说RAG是一种方法论,而不是指某一项具体的技术?
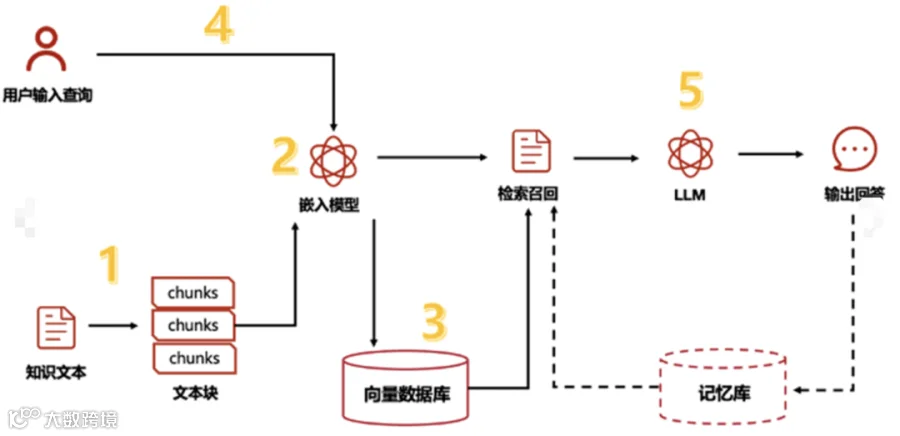
原因就在于,RAG本身并没有约束你使用那种搜索技术,也没约束你怎么构建大模型上下文进行更好的内容生成。
对大模型来说,它只关注你构建的上下文质量怎么样,不要超出上下文窗口限制;但上下文中的内容是怎么来的,就不是它关心的事了。
因此,大模型生成的内容怎么样,一是看你的上下文构建方式,二是看你检索到的数据质量。
所以,如果说上下文管理技术决定了模型生成的质量,那么搜索技术就是保证上下文质量的核心组件。
搜索技术
自搜索引擎出现以来,搜索技术就已经渗透到我们生活的方方面面;我们平常遇到问题使用百度或谷歌,买东西时在购物APP中搜索需要的商品,在视频网站搜索我们想看的电影,这些都属于搜索技术的范畴。
但这些都是从用户的角度来看的,那么从技术的角度来说,有哪些常见的搜索技术呢?
事实上搜索技术涉及的范围非常广,在不同的场景中有不同的解决方案和技术栈;如搜索引擎的搜索技术和电商APP的搜索技术就不尽相同。
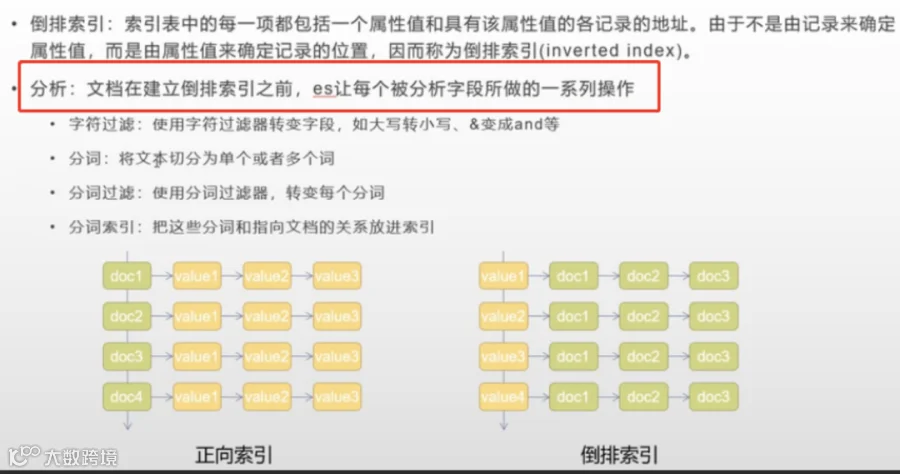
而作为开发人员,我们经常用到的所谓的搜索技术,应该就是基于数据库的字符匹配方式了;通过完整的字符串匹配获取最终的结果,基于缓存的搜索方式同样如此。
只不过,在类似于搜索引擎和大模型自然语言对话场景中,基于字符串匹配的方式就不太行了;这时就需要用到分词技术和语义相似度检索技术。
原因就是,用户可能说了一段话,但这段话中并没有完整的字符匹配内容,这时通过分词,从用户问题中提取关键字和词,进行数据匹配,以实现搜索的目的。
而语义相似度检索方式,是人工智能技术发展的产物,其原理是通过向量计算,来计算文本的语义相似度,这样就可以根据问题找到与问题相关的内容。
但是,这些基于分词和语义匹配的方式虽然好用,但如果针对格式化数据应该怎么办呢?比如说表数据?
这时,你可能说这不就是字符匹配的方式吗?
基于表结构的数据检索确实是字符匹配,但在自然语言对话中,用户说的是自然语言并不是专业术语,这个应该怎么办?
这种方式使用语义检索明显不是一个好的办法,因此这时大模型的语义理解能力就有用武之地了。
通过让大模型理解用户的问题,然后根据问题去生成查询语句或查询参数,这样就可以通过SQL或调用API的方式来获取数据。